Getting a Google Docs draft ready for Mailchimp via Emacs and Org Mode
Posted: - Modified: | emacs, org: Got it to include the dates in the TOC as well
I've been volunteering to help with the Bike Brigade newsletter. I like that there are people who are out there helping improve food security by delivering food bank hampers to recipients. Collecting information for the newsletter also helps me feel more appreciation for the lively Toronto biking scene, even though I still can't make it out to most events. The general workflow is:
- collect info
- draft the newsletter somewhere other volunteers can give feedback on
- convert the newsletter to Mailchimp
- send a test message
- make any edits requested
- schedule the email campaign
We have the Mailchimp Essentials plan, so I can't just export HTML for the whole newsletter. Someday I should experiment with services that might let me generate the whole newsletter from Emacs. That would be neat. Anyway, with Mailchimp's block-based editor, at least I can paste in HTML code for the text/buttons. That way, I don't have to change colours or define links by hand.
The logistics volunteers coordinate via Slack, so a Slack Canvas seemed like a good way to draft the newsletter. I've previously written about my workflow for copying blocks from a Slack Canvas and then using Emacs to transform the rich text, including recolouring the links in the section with light text on a dark background. However, copying rich text from a Slack Canvas turned out to be unreliable. Sometimes it would copy what I wanted, and sometimes nothing would get copied. There was no way to export HTML from the Slack Canvas, either.
I switched to using Google Docs for the drafts. It was a little less convenient to add items from Slack messages and I couldn't easily right-click to download the images that I pasted in. It was more reliable in terms of copying, but only if I used xclip to save the clipboard into a file instead of trying to do the whole thing in memory.
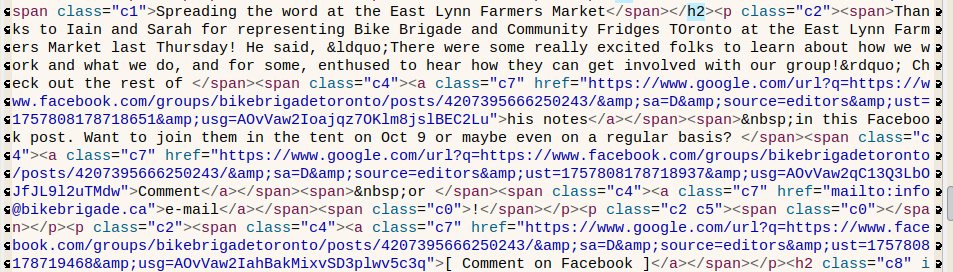
I finally got to spend a little time automating a new workflow. This time I exported the Google Doc as a zip that had the HTML file and all the images in a subdirectory. The HTML source is not very pleasant to work with. It has lots of extra markup I don't need. Here's what an entry looks like:
Things I wanted to do with the HTML:
- Remove the google.com/url redirection for the links. Mailchimp will add its own redirection for click-tracking, but at least the links can look simpler when I paste them in.
- Remove all the extra classes and styles.
- Turn [ call to action ] into fancier Mailchimp buttons.
Also, instead of transforming one block at a time, I decided to make an Org Mode document with all the different blocks I needed. That way, I could copy and paste things in quick succession.
Here's what the result looks like. It makes a table of contents, adds the sign-up block, and adds the different links and blocks I need to paste into Mailchimp.
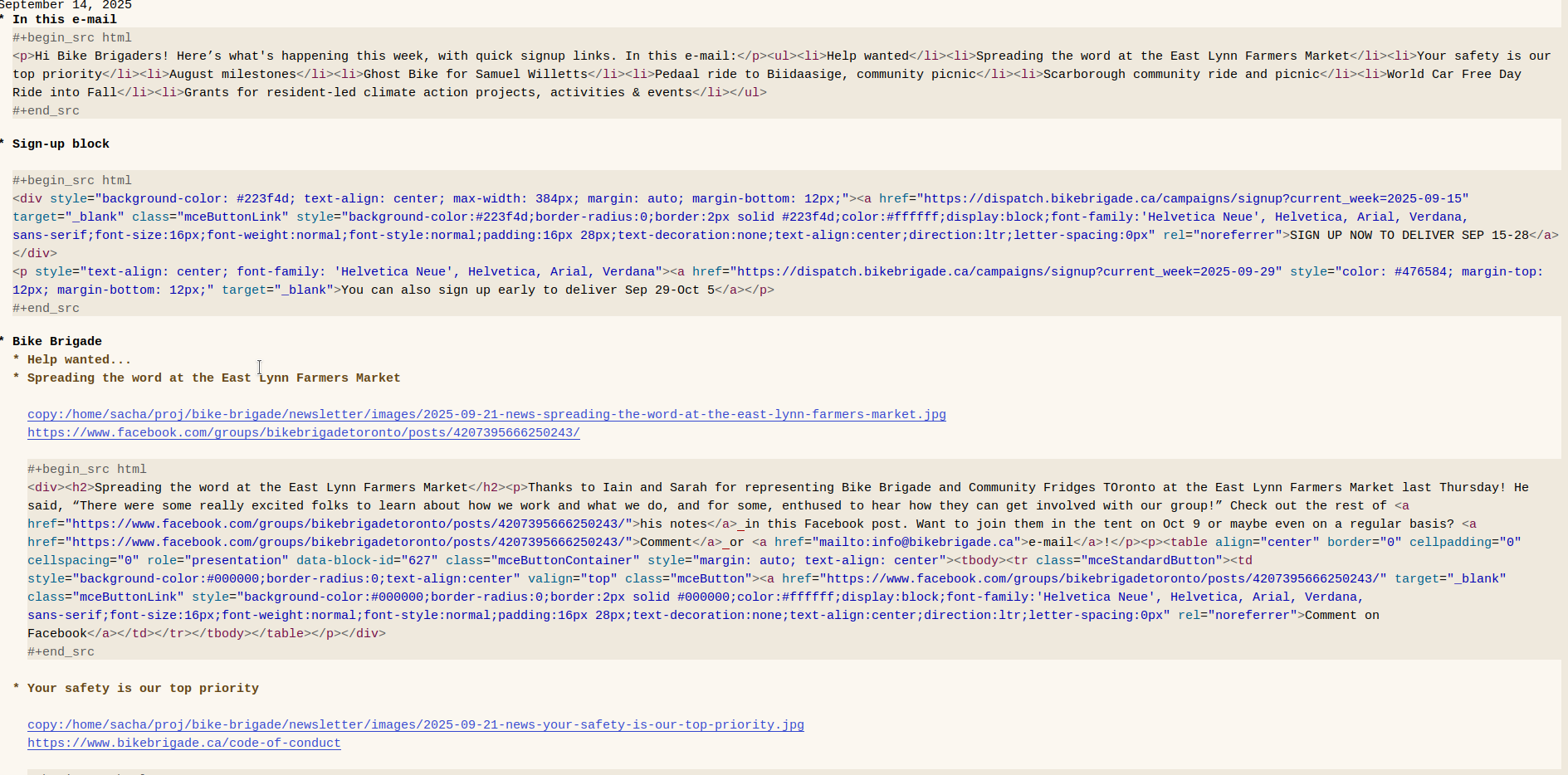
I need to copy and paste the image filenames into the upload dialog on Mailchimp, so I use my custom Org Mode link type for copying to the clipboard. For the HTML code, I use #+begin_src html ... #+end_src instead of #+begin_export html ... #+end_export so that I can use Embark and embark-org to quickly copy the contents of the source block. (That doesn't work for export blocks yet.) I have C-. bound to embark-act, the source block is detected by the functions that embark-org.el added to embark-target-finders, and the c binding in embark-org-src-block-map calls embark-org-copy-block-contents. So all I need to do is C-. c in a block to copy its contents.
Here's the code to process the newsletter draft
(defun my-brigade-process-latest-newsletter-draft (date)
"Create an Org file with the HTML for different blocks."
(interactive (list (if current-prefix-arg (org-read-date nil t nil "Date: ")
(org-read-date nil t "+Sun"))))
(when (stringp date) (setq date (date-to-time date)))
(let ((default-directory "~/Downloads/newsletter")
file
dom
sections)
(call-process "unzip" nil nil nil "-o" (my-latest-file "~/Downloads" "\\.zip$"))
(setq file (my-latest-file default-directory))
(with-temp-buffer
(insert-file-contents-literally file)
(goto-char (point-min))
(setq dom (my-brigade-simplify-html (libxml-parse-html-region (point-min) (point-max))))
(my-brigade-save-newsletter-images dom)
(setq sections
(my-html-group-by-tag
'h1
(dom-children
(dom-by-tag
dom 'body)))))
(with-current-buffer (get-buffer-create "*newsletter*")
(erase-buffer)
(org-mode)
(insert
(format-time-string "%B %-e, %Y" date) "\n"
"* In this e-mail\n#+begin_src html\n"
"<p>Hi Bike Brigaders! Here’s what's happening this week, with quick signup links. In this e-mail:</p>"
(replace-regexp-in-string
"<li>" "\n<li>"
(with-temp-buffer
(svg-print
(apply 'dom-node
'ul nil
(append
(my-brigade-toc-items (assoc-default "Bike Brigade" sections 'string=))
(my-brigade-toc-items (assoc-default "In our community" sections 'string=)))))
(buffer-string)))
"\n<br />\n"
(my-brigade-copy-signup-block date)
"\n#+end_src\n\n")
(dolist (sec '("Bike Brigade" "In our community"))
(insert "* " sec "\n"
(mapconcat
(lambda (group)
(let* ((item (apply 'dom-node 'div nil
(append
(list (dom-node 'h2 nil (car group)))
(cdr group))))
(image (my-brigade-image (car group))))
(format "** %s\n\n%s\n%s\n\n#+begin_src html\n%s\n#+end_src\n\n"
(car group)
(if image (org-link-make-string (concat "copy:" image)) "")
(or (my-html-last-link-href item) "")
(my-transform-html
(delq nil
(list
'my-transform-html-remove-images
'my-transform-html-remove-italics
'my-brigade-format-buttons
(when (string= sec "In our community")
'my-brigade-recolor-recursively)))
item))))
(my-html-group-by-tag 'h2 (cdr (assoc sec sections 'string=)))
"")))
(insert "* Other updates\n"
(format "#+begin_src html\n<h2>Other updates</h2>%s\n#+end_src\n\n"
(my-transform-html
'(my-transform-html-remove-images
my-transform-html-remove-italics)
(car (cdr (assoc "Other updates" sections 'string=))))))
(goto-char (point-min))
(display-buffer (current-buffer)))))
(defun my-brigade-toc-items (section-children)
"Return a list of <li /> nodes."
(mapcar
(lambda (group)
(let* ((text (dom-texts (cadr group)))
(regexp (format "^%s \\([A-Za-z]+ [0-9]+\\)"
(regexp-opt '("Mon" "Tue" "Wed" "Thu" "Fri" "Sat" "Sun"))))
(match (when (string-match regexp text) (match-string 1 text))))
(dom-node 'li nil
(org-html-encode-plain-text
(if match
(format "%s: %s" match (car group))
(car group))))))
(my-html-group-by-tag 'h2 section-children)))
(defun my-html-group-by-tag (tag dom-list)
"Use TAG to divide DOM-LIST into sections. Return an alist of (section . children)."
(let (section-name current-section results)
(dolist (node dom-list)
(if (and (eq (dom-tag node) tag)
(not (string= (string-trim (dom-texts node)) "")))
(progn
(when current-section
(push (cons section-name (nreverse current-section)) results)
(setq current-section nil))
(setq section-name (string-trim (dom-texts node))))
(when section-name
(push node current-section))))
(when current-section
(push (cons section-name (reverse current-section)) results)
(setq current-section nil))
(nreverse results)))
(defun my-html-last-link-href (node)
"Return the last link HREF in NODE."
(dom-attr (car (last (dom-by-tag node 'a))) 'href))
(defun my-brigade-image (heading)
"Find the latest image related to HEADING."
(car
(nreverse
(directory-files my-brigade-newsletter-images-directory
t (regexp-quote (my-brigade-newsletter-heading-to-image-file-name heading))))))
Some of the functions it uses are in my config, particularly the section on Transforming HTML clipboard contents with Emacs to smooth out Mailchimp annoyances: dates, images, comments, colours.
Along the way, I learned that svg-print is a good way to turn document object models back into HTML.
When I saw two more events and one additional link that I wanted to include, I was glad I already had this code sorted out. It made it easy to paste the images and details into the Google Doc, reformat it slightly, and get the info through the process so that it ended up in the newsletter with a usefully-named image and correctly-coloured links.
I think this is a good combination of Google Docs for getting other people's feedback and letting them edit, and Org Mode for keeping myself sane as I turn it into whatever Mailchimp wants.
My next step for improving this workflow might be to check out other e-mail providers in case I can get Emacs to make the whole template. That way, I don't have to keep switching between applications and using the mouse to duplicate blocks and edit the code.