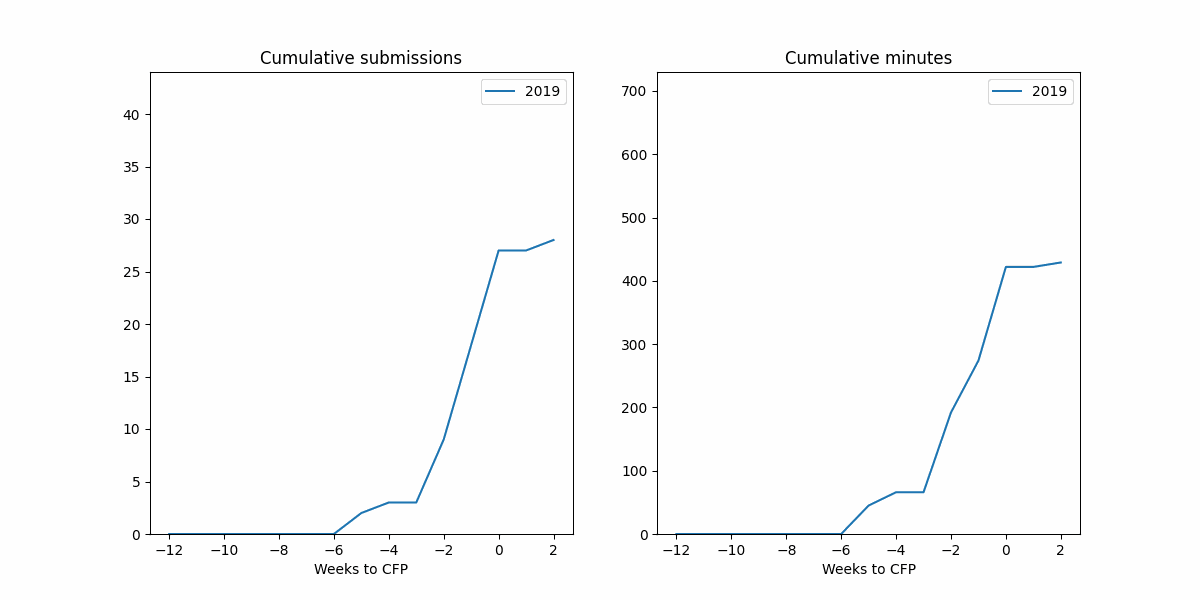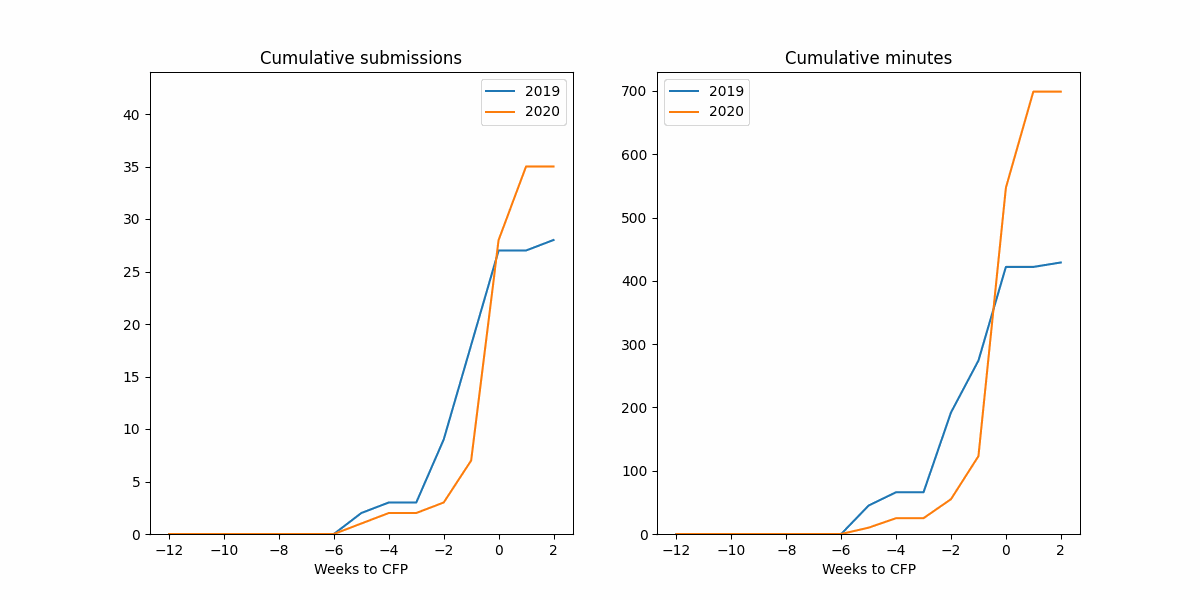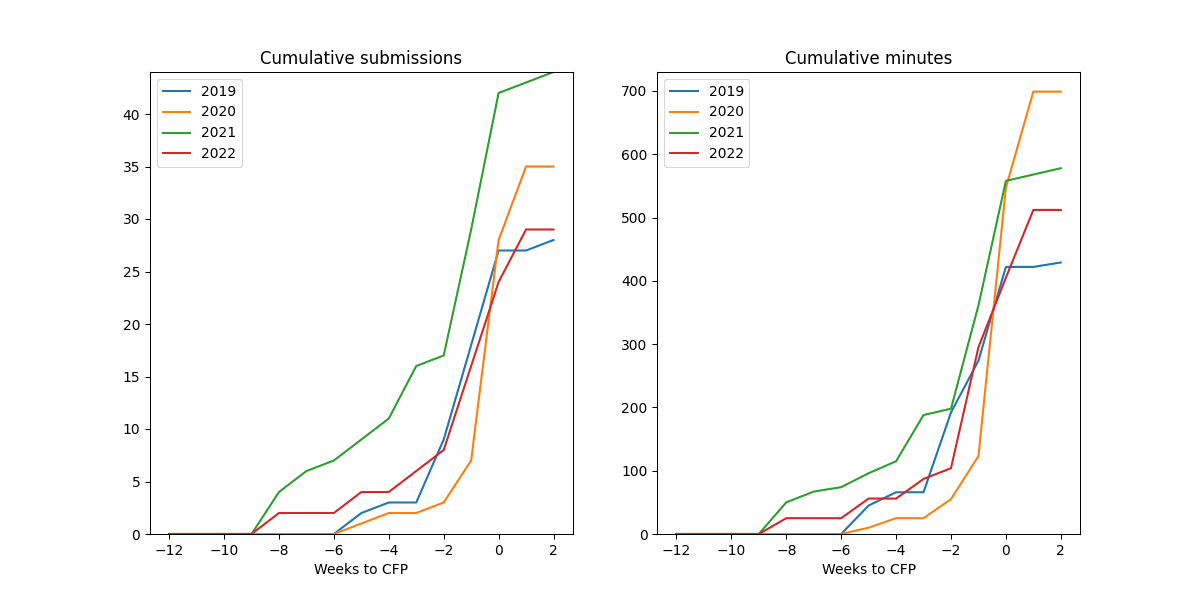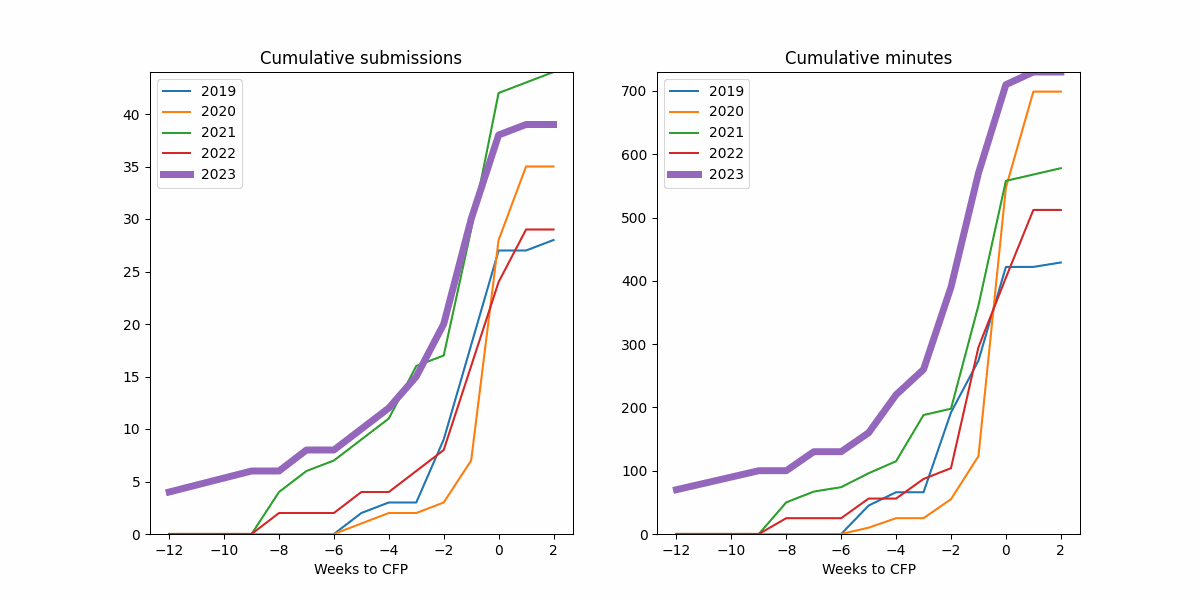
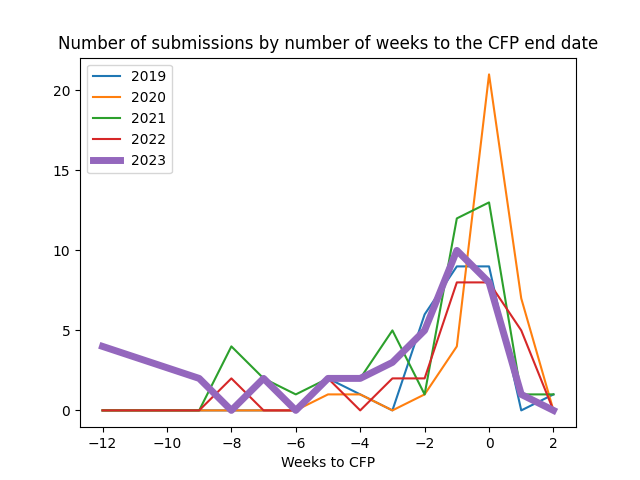
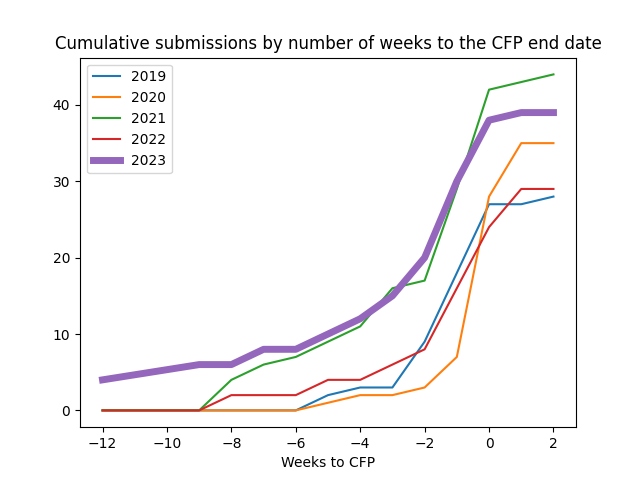
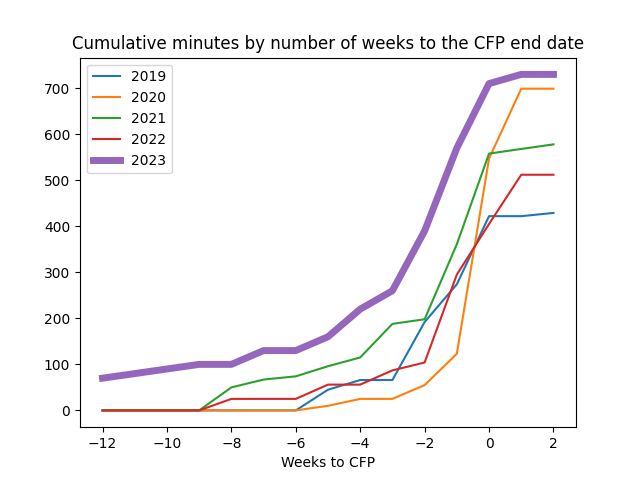
Not everyone has Javascript turned on, so I wanted
to start with something that made sense even in
RSS feeds like the one on Planet Emacslife (which
strips out <style> and <script>) and was
progressively enhanced with captions and
highlighting if you saw it on my site.
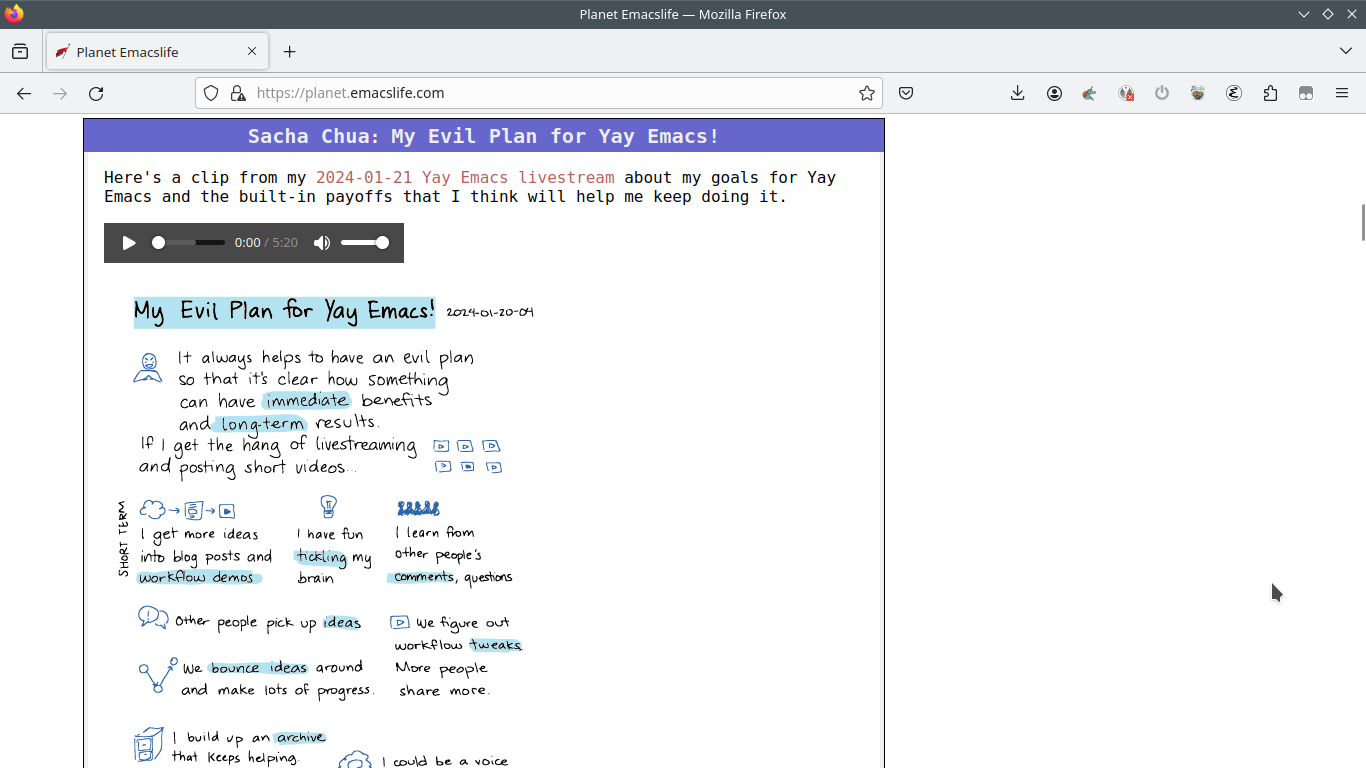
The blog aggregator I'm using, Planet Venus, hasn't been updated in 14 years. It even uses Python 2. I considered switching to a different aggregator, so I started checking out different community planets. Most of the other planets listed in this HN thread about aggregators looked like they were using the same Planet Venus aggregator, although these were some planets that used something else:
- https://github.com/hrw/very-simple-planet-aggregator
- https://github.com/openSUSE/planet-o-o
- https://planet.lisp.org/about.html
I decided I'd stick with Planet Venus for now, since I could probably figure out how to get the attributes sorted out.
I found planet/vendor/feedparser.py by digging
around. Adding mix-blend-mode to the list of
attributes there was not enough to get it working.
I started exploring pdb for interactive Python
debugging inside Emacs, although I think dap is an
option too. I wrote a short bit of code to test things out:
import sys,os sys.path.insert(1, os.path.join(os.path.dirname(__file__), 'planet/vendor')) from feedparser import _sanitizeHTML assert 'strong' in _sanitizeHTML('<strong>Hello</strong>', 'utf-8', 'text/html') assert 'mix-blend-mode' in _sanitizeHTML('<svg><path style="fill: red;mix-blend-mode:darken"></path></svg>', 'utf-8', 'text/html')
It was pretty easy to use pdb to start stepping
through and into functions, although I didn't dig
into it deeply because I figured it out another
way. While looking through the pull requests for
the Venus repository, I came across this
pull
request to add data- attributes which was
helpful because it pointed me to
planet/vendor/html5lib/sanitizer.py. Once I
added mix-blend-mode to that one, things worked.
Here's my Github branch.
On a somewhat related note, I also had to patching shr to handle SVG images with viewBox attributes. I guess SVGs aren't that common yet, but I'm looking forward to playing around with them more, so I might as well make things better (at least when it comes to things I can actually tweak). mix-blend-mode on SVG elements says it's not supported in Safari or a bunch of mobile browsers, but it seems to be working on my phone, so maybe that's cool now. Using mix-blend-mode means I don't have to do something complicated when it comes to animating highlights while still keeping text visible, and improving SVG support is the right thing to do. Onward!
You can e-mail me at sacha@sachachua.com.
]]>