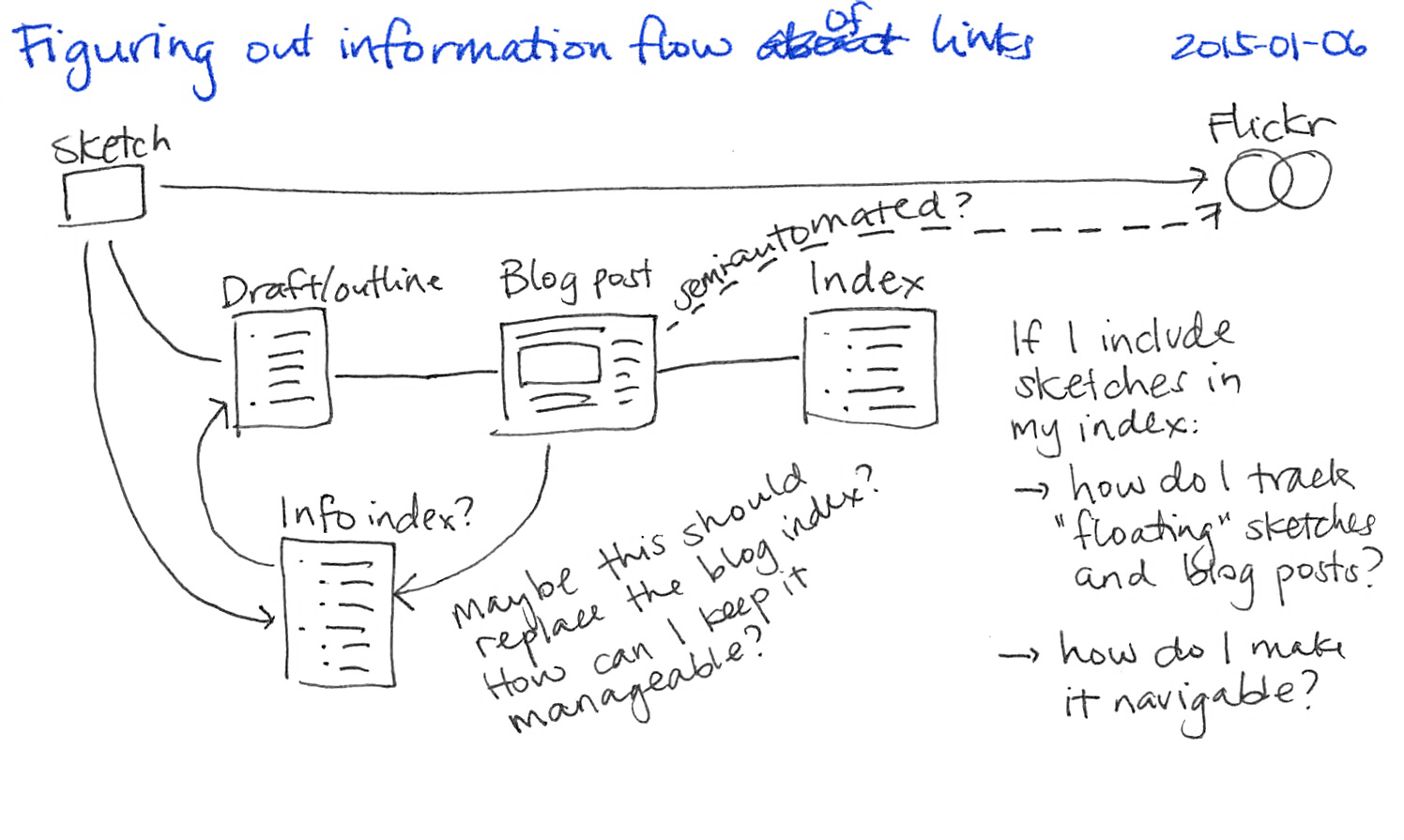
We hardly ever watch movies in the theatre now, since we prefer watching movies with subtitles and the ability to pause. Fortunately, the Toronto Public Library has a frequently updated collection of DVDs. The best time to grab a movie is when it’s a new release, since DVDs that have been in heavy circulation can get pretty scratched up from use. However, newly released movies can’t be reserved. You need to find them at the library branches they’re assigned to, and then you can borrow them for seven days. You can check the status of each movie online to see if it’s in the library or when it’s due to be returned.
Since there are quite a few movies on our watch list, quite a few library branches we can walk to, and some time flexibility as to when to go, checking all those combinations is tedious. I wrote a script that takes a list of branches and a list of movie URLs, checks the status of each, and displays a table sorted by availability and location. My code gives me a list like this:
| In Library |
Annette Street |
Mad Max Fury Road |
M 10-8:30 T 12:30-8:30 W 10-6 Th 12:30-8:30 F 10-6 Sat 9-5 |
| In Library |
Bloor/Gladstone |
Inside Out |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 Sun 1:30-5 |
| In Library |
Bloor/Gladstone |
Match |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 Sun 1:30-5 |
| In Library |
Jane/Dundas |
Avengers: Age of Ultron |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 |
| In Library |
Jane/Dundas |
Ant-Man |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 |
| In Library |
Jane/Dundas |
Mad Max Fury Road |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 |
| In Library |
Jane/Dundas |
Minions |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 |
| In Library |
Perth/Dupont |
Chappie |
T 12:30-8:30 W 10-6 Th 12:30-8:30 F 10-6 Sat 9-5 |
| In Library |
Runnymede |
Ant-Man |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 |
| In Library |
Runnymede |
Minions |
M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5 |
| In Library |
St. Clair/Silverthorn |
Kingsman: the Secret Service |
T 12:30-8:30 W 10-6 Th 12:30-8:30 F 10-6 Sat 9-5 |
| In Library |
St. Clair/Silverthorn |
Mad Max Fury Road |
T 12:30-8:30 W 10-6 Th 12:30-8:30 F 10-6 Sat 9-5 |
| In Library |
Swansea Memorial |
Ant-Man |
T 10-6 W 1-8 Th 10-6 Sat 10-5 |
| In Library |
Swansea Memorial |
Chappie |
T 10-6 W 1-8 Th 10-6 Sat 10-5 |
| In Library |
Swansea Memorial |
Kingsman: the Secret Service |
T 10-6 W 1-8 Th 10-6 Sat 10-5 |
| In Library |
Swansea Memorial |
Kingsman: the Secret Service |
T 10-6 W 1-8 Th 10-6 Sat 10-5 |
| In Library |
Swansea Memorial |
Mad Max Fury Road |
T 10-6 W 1-8 Th 10-6 Sat 10-5 |
| In Library |
Swansea Memorial |
Minions |
T 10-6 W 1-8 Th 10-6 Sat 10-5 |
| 2015-12-08 |
Perth/Dupont |
Terminator Genisys |
T 12:30-8:30 W 10-6 Th 12:30-8:30 F 10-6 Sat 9-5 |
| 2015-12-08 |
Perth/Dupont |
Mad Max Fury Road |
T 12:30-8:30 W 10-6 Th 12:30-8:30 F 10-6 Sat 9-5 |
| 2015-12-09 |
Swansea Memorial |
Avengers: Age of Ultron |
T 10-6 W 1-8 Th 10-6 Sat 10-5 |
… many more rows omitted. =)
With this data, I can decide that Swansea Memorial has a bunch of things I might want to check out, and pick that as the destination for my walk. Sure, there’s a chance that someone else might check out the movies before I get there (although I can minimize that by getting to the library as soon as it opens), or that the video has been misfiled or misplaced, but overall, the system tends to work fine.
It’s easy for me to send the output to myself by email, too. I just select the part of the table I care about and use Emacs’ M-x shell-command-on-region (M-|) to mail it to myself with the command mail -s "Videos to check out" sacha@sachachua.com.
The first time I ran my script, I ended up going to Perth/Dupont to pick up seven movies in addition to the two I picked up from Annette Library. Many of the movies had been returned but not yet shelved, so the librarian retrieved them from his bin and gave them to me. When I got back, W- looked at the stack of DVDs by the television and said, “You know that’s around 18 hours of viewing, right?” It’ll be fine for background watching. =)
Little things like this make me glad that I can write scripts and other tiny tools to make my life better. Anything that involves multiple steps or combining information from multiple sources might be simpler with a script. I wrote this script as a command-line tool with NodeJS, since I’m comfortable with the HTML request and parsing libraries available there.
Anyway, here’s the code, in case you want to build on the idea. Have fun!
/* Shows you which videos are available at which libraries.
Input: A json filename, which should be a hash of the form:
{"branches": {"Branch name": "Additional branch details (ex: hours)", ...},
"videos": [{"Title": "URL to library page"}, ...]}.
Example: {
"branches": {
"Runnymede": "M 9-8:30 T 9-8:30 W 9-8:30 Th 9-8:30 F 9-5 Sat 9-5"
},
"videos": [
{"title": "Avengers: Age of Ultron", "url": "http://www.torontopubliclibrary.ca/detail.jsp?Entt=RDM3350205&R=3350205"}
]}
Output:
Status,Branch,Title,Branch notes
*/
var rp = require('request-promise');
var moment = require('moment');
var async = require('async');
var cheerio = require('cheerio');
var q = require('q');
var csv = require('fast-csv');
var fs = require('fs');
if (process.argv.length < 3) {
console.log('Please specify the JSON file to read the branches and videos from.');
process.exit(1);
}
var config = JSON.parse(fs.readFileSync(process.argv[2]));
var branches = config.branches;
var videos = config.videos;
/*
Returns a promise that will resolve with an array of [status,
branch, movie, info], where status is either the next due date, "In
Library", etc. */
function checkStatus(branches, movie) {
var url = movie.url;
var matches = url.match(/R=([0-9]+)/);
return rp.get(
'http://www.torontopubliclibrary.ca/components/elem_bib-branch-holdings.jspf?print=&numberCopies=1&itemId='
+ matches[1]).then(function(a) {
var $ = cheerio.load(a);
var results = [];
var lastBranch = '';
$('tr.notranslate').each(function() {
var row = $(this);
var cells = row.find('td');
var branch = $(cells[0]).text().replace(/^[ \t\r\n]+|[ \t\r\n]+$/g, '');
var due = $(cells[2]).text().replace(/^[ \t\r\n]+|[ \t\r\n]+$/g, '');
var status = $(cells[3]).text().replace(/^[ \t\r\n]+|[ \t\r\n]+$/g, '');
if (branch) { lastBranch = branch; }
else { branch = lastBranch; }
if (branches[branch]) {
if (status == 'On loan' && (matches = due.match(/Due: (.*)/))) {
status = moment(matches[1], 'DD/MM/YYYY').format('YYYY-MM-DD');
}
if (status != 'Not Available - Search in Progress') {
results.push([status, branch, movie.title, branches[branch]]);
}
}
});
return results;
});
}
function checkAllVideos(branches, videos) {
var results = [];
var p = q.defer();
async.eachLimit(videos, 5, function(video, callback) {
checkStatus(branches, video).then(function(result) {
results = results.concat(result);
callback();
});
}, function(err) {
p.resolve(results.sort(function(a, b) {
if (a[0] == 'In Library') {
if (b[0] == 'In Library') {
if (a[1] < b[1]) return -1;
if (a[1] > b[1]) return 1;
if (a[2] < b[2]) return -1;
if (a[2] > b[2]) return 1;
return 0;
} else {
return -1;
}
}
if (b[0] == 'In Library') { return 1; }
if (a[0] < b[0]) { return -1; }
if (a[0] > b[0]) { return 1; }
return 0;
}));
});
return p.promise;
}
checkAllVideos(branches, videos).then(function(result) {
csv.writeToString(result, {}, function(err, data) {
console.log(data);
});
});
P.S. Okay, I’m really tempted to walk over to Swansea Memorial, but W- reminds me that we’ve got a lot of movies already waiting to be watched. So I’ll probably just walk to the supermarket, but I’m looking forward to running this script once we get through our backlog of videos!