De-dupe and link: Using the Flickr API to neaten up my archive and link sketches to blog posts
Posted: - Modified: | development, geekI've been thinking about how to manage the relationships between my blog posts and my Flickr sketches. Here's the flow of information:
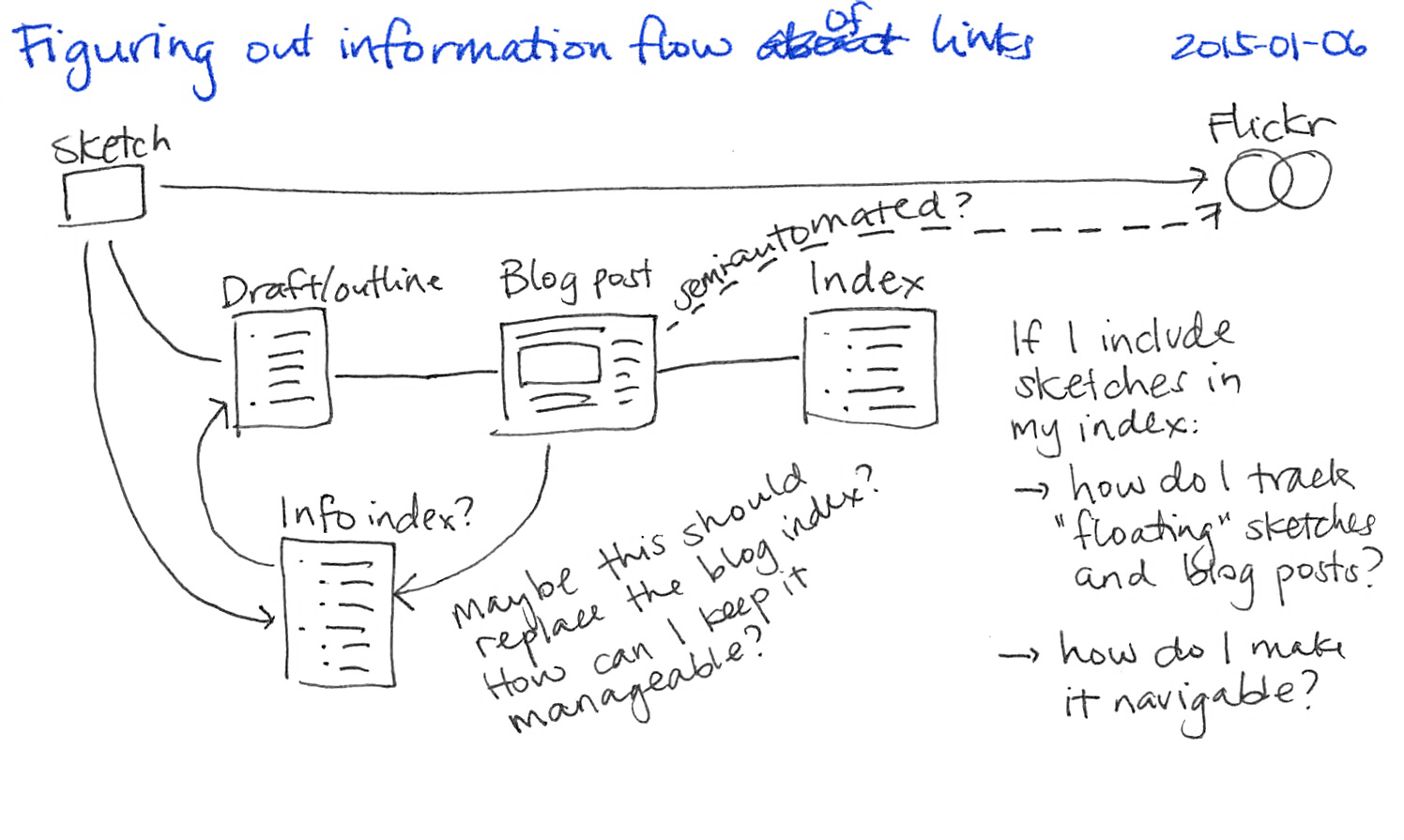

I scan my sketches or draw them on the computer, and then I upload these sketches to Flickr using photoSync, which synchronizes folders with albums. I include these sketches in my outlines and blog posts, and I update my index of blog posts every month. I recently added a tweak to make it possible for people to go from a blog post to its index entry, so it should be easier to see a post in context. I've been thinking about keeping an additional info index to manage blog posts and sketches, including unpublished ones. We'll see how well that works. Lastly, I want to link my Flickr posts to my blog posts so that people can see the context of the sketch.
My higher goal is to be able to easily see the open ideas that I haven't summarized or linked to yet. There's no shortage of new ideas, but it might be interesting to revisit old ones that had a chance to simmer a bit. I wrote a little about this in Learning from artists: Making studies of ideas. Let me flesh out what I want this archive to be like.
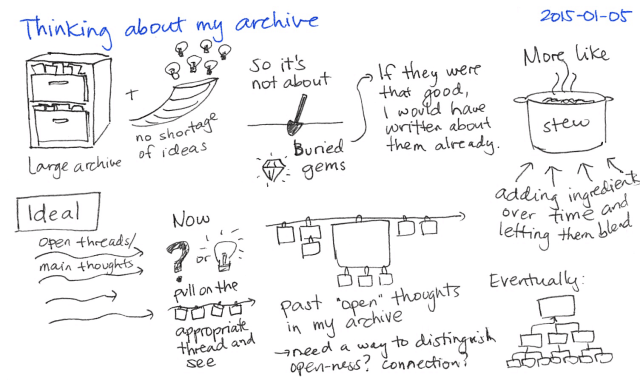
2015.01.05 Thinking about my archive
When I pull on an idea, I'd like to be able to see other open topics attached to it. I also want to be able to see open topics that might jog my memory.
How about the technical details? How can I organize my data so that I can get what I want from it?

2015.01.05 Figuring out the technical details of this idea or visual archive I want – index card
Because blog posts link to sketches and other blog posts, I can model this as a directed graph. When I initially drew this, I thought I might be able to get away with an acyclic graph (no loops). However, since I habitually link to future posts (the time traveller's problem!), I can't make that simplifying assumption. In addition, a single item might be linked from multiple things, so it's not a simple tree (and therefore I can't use an outline). I'll probably start by extracting all the link information from my blog posts and then figuring out some kind of Org Mode-based way to update the graph.
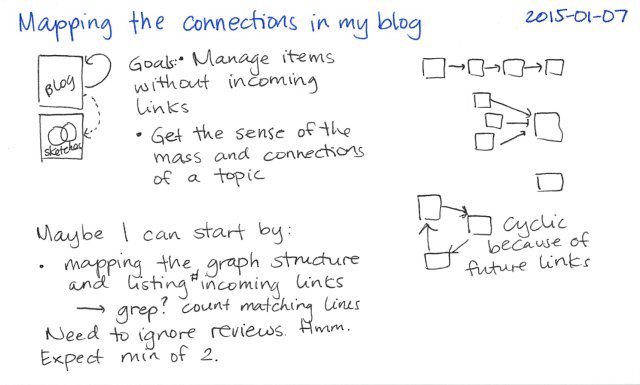

To get one step closer to being able to see open thoughts and relationships, I decided that my sketches on Flickr:
- should not have duplicates despite my past mess-ups, so that:
- I can have an accurate count
- it's easier for me to categorize
- people get less confused
- should have hi-res versions if possible, despite the IFTTT recipe I tried that imported blog posts but unfortunately picked up the low-res thumbnails instead of the hi-res links
- should link to the blog posts they're mentioned in, so that:
- people can read more details if they come across a sketch in a search
- I can keep track of which sketches haven't been blogged yet
I couldn't escape doing a bit of manual cleaning up, but I knew I could automate most of the fiddly bits. I installed node-flickrapi and cheerio (for HTML parsing), and started playing.
Removing duplicates
Most of the duplicates had resulted from the Great Renaming, when I added tags in the form of #tag1 #tag2 etc. to selected filenames. It turns out that adding these tags en-masse using Emacs' writable Dired mode broke photoSync's ability to recognize the renamed files. As a result, I had files like this:
- 2013-05-17 How I set up Autodesk Sketchbook Pro for sketchnoting.png
- 2013-05-17 How I set up Autodesk Sketchbook Pro for sketchnoting #tech #autodesk-sketchbook-pro #drawing.png
This is neatly resolved by the following Javascript:
exports.trimTitle = function(str) {
return str.replace(/ --.*$/g, '').replace(/#[^ ]+/g, '').replace(/[- _]/g, '');
};
and a comparison function that compared the titles and IDs of two photos:
exports.keepNewPhoto = function(oldPhoto, newPhoto) {
if (newPhoto.title.length > oldPhoto.title.length)
return true;
if (newPhoto.title.length < oldPhoto.title.length)
return false;
if (newPhoto.id < oldPhoto.id)
return true;
return false;
};
So then this code can process the photos:
exports.processPhoto = function(p, flickr) {
var trimmed = exports.trimTitle(p.title);
if (trimmed && hash[trimmed] && p.id != hash[trimmed].id) {
// We keep the one with the longer title or the newer date
if (exports.keepNewPhoto(hash[trimmed], p)) {
exports.possiblyDeletePhoto(hash[trimmed], flickr);
hash[trimmed] = p;
}
else if (p.id != hash[trimmed].id) {
exports.possiblyDeletePhoto(p, flickr);
}
} else {
hash[trimmed] = p;
}
};
You can see the code on Gist: duplicate_checker.js.
High-resolution versions
I couldn't easily automate this, but fortunately, the IFTTT script had only imported twenty images or so, clearly marked by a description that said: "via sacha chua :: living an awesome life…". I searched for each image, deleting the low-res entry if a high-resolution image was already in the system and replacing the low-res entry if that was the only one there.
Linking to blog posts
This was the trickiest part, but also the most fun. I took advantage of the fact that WordPress transforms uploaded filenames in a mostly consistent way. I'd previously added a bulk view that displayed any number of blog posts with very little additional markup, and I modified the relevant code in my theme to make parsing easier.
/** * Adds "Blogged" links to Flickr for images that don't yet have "Blogged" in their description. * Command-line argument: URL to retrieve and parse */ var secret = require('./secret'); var flickrOptions = secret.flickrOptions; var Flickr = require("flickrapi"); var fs = require('fs'); var request = require('request'); var cheerio = require('cheerio'); var imageData = {}; var $; function setDescriptionsFromURL(url) { request(url, function(error, response, body) { // Parse the images $ = cheerio.load(body); $('article').each(function() { var prettyLink = $(this).find("h2 a").attr("href"); if (!prettyLink.match(/weekly/i) && !prettyLink.match(/monthly/i)) { collectLinks($(this), prettyLink, imageData); } }); updateFlickrPhotos(); }); } function updateFlickrPhotos() { Flickr.authenticate(flickrOptions, function(error, flickr) { flickr.photos.search( {user_id: flickrOptions.user_id, per_page: 500, extras: 'description', text: ' -blogged'}, function(err, result) { processPage(result, flickr); for (var i = 2 ; i < result.photos.pages; i++) { flickr.photos.search( {user_id: flickrOptions.user_id, per_page: 500, page: i, extras: 'description', text: ' -blogged'}, function(err, result) { processPage(err, result, flickr); }); } }); }); } function collectLinks(article, prettyLink, imageData) { var results = []; article.find(".body a").each(function() { var link = $(this); if (link.attr('href')) { if (link.attr('href').match(/sachachua/) || !link.attr('href').match(/^http/)) { imageData[exports.trimTitle(link.attr('href'))] = prettyLink; } else if (link.attr('href').match(/flickr.com/)) { imageData[exports.trimTitle(link.text())] = prettyLink; } } }); return results; } exports.trimTitle = function(str) { return str.replace(/^.*\//, '').replace(/^wpid-/g, '').replace(/[^A-Za-z0-9]/g, '').replace(/png$/, '').replace(/[0-9]$/, ''); }; function processPage(result, flickr) { if (!result) return; for (var i = 0; i < result.photos.photo.length; i++) { var p = result.photos.photo[i]; var trimmed = exports.trimTitle(p.title); var noTags = trimmed.replace(/#.*/g, ''); var withTags = trimmed.replace(/#/g, ''); var found = imageData[noTags] || imageData[withTags]; if (found) { var description = p.description._content; if (description.match(found)) continue; if (description) { description += " - "; } description += '<a href="' + found + '">Blogged</a>'; console.log("Updating " + p.title + " with " + description); flickr.photos.setMeta( {photo_id: p.id, description: description}, function(err, res) { if (err) { console.log(err, res); } } ); } } } setDescriptionsFromURL(process.argv[2]);
And now sketches like
are now properly linked to their blog posts. Yay! Again, this script won't get everything, but it gets a decent number automatically sorted out.
Next steps:
- Run the image extraction and set description scripts monthly as part of my indexing process
- Check my list of blogged images to see if they're matched up with Flickr sketches, so that I can identify images mysteriously missing from my sketchbook archive or not correctly linked
Yay code!
1 comment
John Hansen
2020-04-24T12:45:05ZGreat article, I've learned a lot, thanks.