Emacs Lisp and NodeJS: Getting the bolded words from a section of a Google Document
Posted: - Modified: | french, js, emacs- : Cleaned up links from Google
- : Simplified getting a section or finding the bolded text by using the Org Mode format instead.
During the sessions with my French tutor, I share a Google document so that we can mark the words where I need to practice my pronunciation some more or tweak the wording. Using Ctrl+B to make the word as bold is an easy way to make it jump out.
I used to copy these changes into my Org Mode notes manually, but today I thought I'd try automating some of it.
First, I need a script to download the HTML for a specified Google document. This is probably easier to do with the NodeJS library rather than with oauth2.el and url-retrieve-synchronously because of various authentication things.
require('dotenv').config();
const { google } = require('googleapis');
async function download(fileId) {
const auth = new google.auth.GoogleAuth({
scopes: ['https://www.googleapis.com/auth/drive.readonly'],
});
const drive = google.drive({ version: 'v3', auth });
const htmlRes = await drive.files.export({
fileId: fileId,
mimeType: 'text/html'
});
return htmlRes.data;
}
async function main() {
console.log(await download(process.argv.length > 2 ? process.argv[2] : process.env['DOC_ID']));
}
main();
Then I can wrap a little bit of Emacs Lisp around it.
(defvar my-google-doc-download-command
(list "nodejs" (expand-file-name "~/bin/download-google-doc-html.cjs")))
(defun my-google-doc-html (doc-id)
(when (string-match "https://docs\\.google\\.com/document/d/\\(.+?\\)/" doc-id)
(setq doc-id (match-string 1 doc-id)))
(with-temp-buffer
(apply #'call-process (car my-google-doc-download-command)
nil t nil (append (cdr my-google-doc-download-command) (list doc-id)))
(buffer-string)))
(defun my-google-doc-clean-html (html)
"Remove links on spaces, replace Google links."
(let ((dom (with-temp-buffer
(insert html)
(libxml-parse-html-region))))
(dom-search
dom
(lambda (o)
(when (eq (dom-tag o) 'a)
(when (and (dom-attr o 'href)
(string-match "https://\\(www\\.\\)?google\\.com/url\\?q=" (dom-attr o 'href)))
(let* ((parsed (url-path-and-query
(url-generic-parse-url (dom-attr o 'href))))
(params (url-parse-query-string (cdr parsed))))
(dom-set-attribute o 'href (car (assoc-default "q" params #'string=)))))
(let ((text (string= (string-trim (dom-text o)) "")))
(when (string= text "")
(setf (car o) 'span))))
(when (and
(string-match "font-weight:700" (or (dom-attr o 'style) ""))
(not (string-match "font-style:normal" (or (dom-attr o 'style) ""))))
(setf (car o) 'strong))
(when (dom-attr o 'style)
(dom-remove-attribute o 'style))))
;; bold text is actually represented as font-weight:700 instead
(with-temp-buffer
(svg-print dom)
(buffer-string))))
(defun my-google-doc-org (doc-id)
"Return DOC-ID in Org Mode format."
(pandoc-convert-stdio (my-google-doc-clean-html (my-google-doc-html doc-id)) "html" "org"))
I have lots of sections in that document, including past journal entries, so I want to get a specific section by name.
(defun my-org-get-subtree-by-name (org-text heading-name)
"Return ORG-TEXT subtree for HEADING-NAME."
(with-temp-buffer
(insert org-text)
(org-mode)
(goto-char (point-min))
(let ((org-trust-scanner-tags t))
(car (delq nil
(org-map-entries
(lambda ()
(when (string= (org-entry-get (point) "ITEM") heading-name)
(buffer-substring (point) (org-end-of-subtree))))))))))
Now I can get the bolded words from a section of my notes, with just a sentence for context. I use pandoc to convert it to Org Mode syntax.
(defvar my-lang-words-for-review-context-function 'sentence-at-point)
(defvar my-lang-tutor-notes-url nil)
(defun my-lang-tutor-notes (section-name)
(my-org-get-subtree-by-name
(my-google-doc-org my-lang-tutor-notes-url)
section-name))
(defun my-lang-words-for-review (section)
"List the bolded words for review in SECTION."
(let* ((section (my-lang-tutor-notes section))
results)
(with-temp-buffer
(insert section)
(org-mode)
(goto-char (point-min))
(org-map-entries
(lambda ()
(org-end-of-meta-data t)
(while (re-search-forward "\\*[^* ].*?\\*" nil t)
(cl-pushnew
(replace-regexp-in-string
"[ \n ]+" " "
(funcall my-lang-words-for-review-context-function))
results
:test 'string=)))))
(nreverse results)))
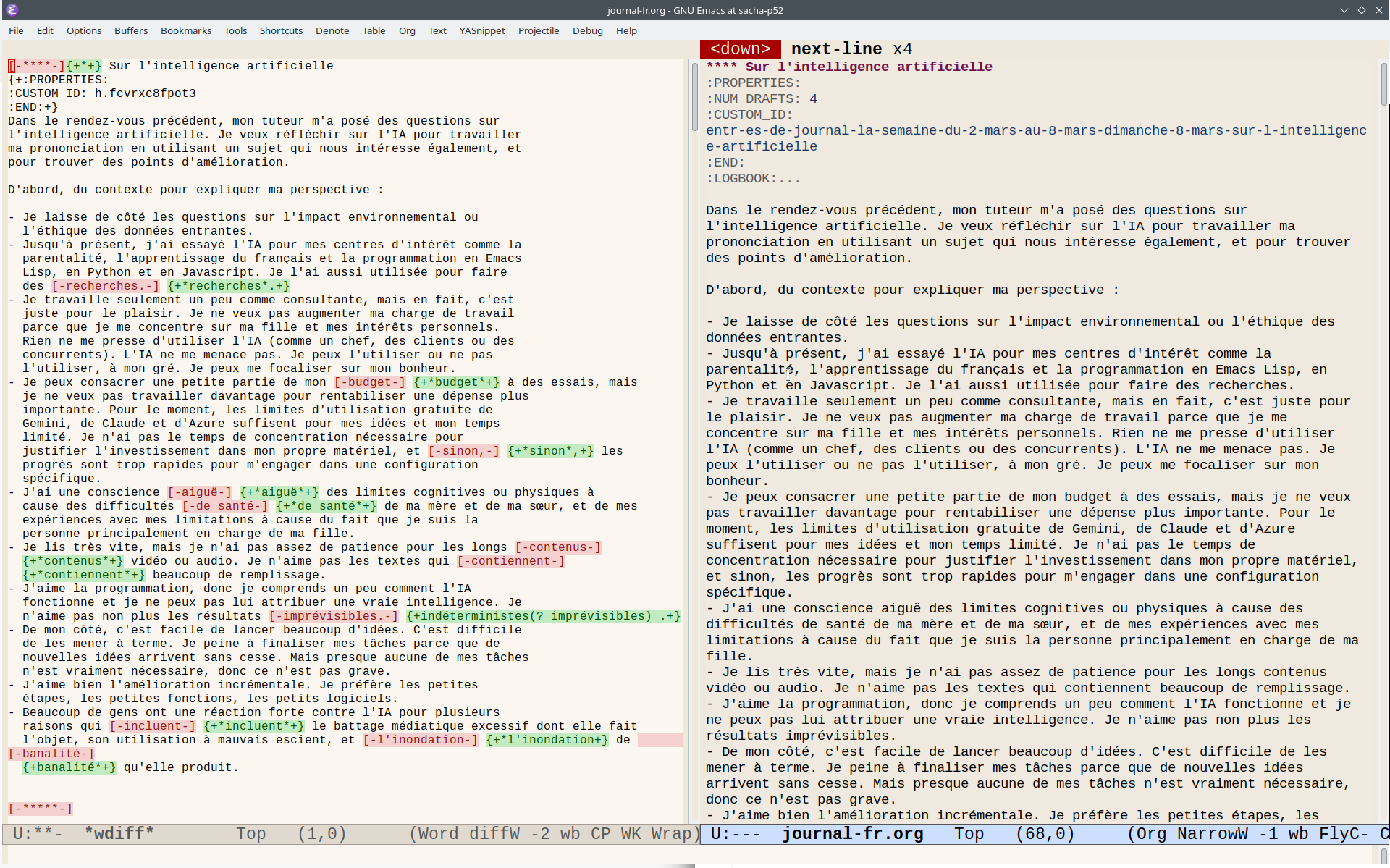
For example, when I run it on my notes on artificial intelligence, this is the list of bolded words and the sentences that contain them.
(my-lang-words-for-review "Sur l'intelligence artificielle")
- Je l'ai aussi utilisée pour faire des recherches.
- Je peux consacrer une petite partie de mon budget à des essais, mais je ne veux pas travailler davantage pour rentabiliser une dépense plus importante.
- Je n'ai pas le temps de concentration nécessaire pour justifier l'investissement dans mon propre matériel, et sinon, les progrès sont trop rapides pour m'engager dans une configuration spécifique.
- J'ai une conscience aiguë des limites cognitives ou physiques à cause des difficultés de santé de ma mère et de ma sœur, et de mes expériences avec mes limitations à cause du fait que je suis la personne principalement en charge de ma fille.
- Je lis très vite, mais je n'ai pas assez de patience pour les longs contenus vidéo ou audio.
- Je n'aime pas les textes qui contiennent beaucoup de remplissage.
- Beaucoup de gens ont une réaction forte contre l'IA pour plusieurs raisons qui incluent le battage médiatique excessif dont elle fait l'objet, son utilisation à mauvais escient, et l'inondation de banalité qu'elle produit.
- Je réécris souvent la majorité du logiciel à l'exception d'un ou deux morceaux parce que ce code ne me convient pas.
- Je ne veux pas l'utiliser pour les correctifs que je veux soumettre à d'autres projets parce que le code ne me semble pas correct et je ne veux pas gaspiller le temps d'autres bénévoles.
- J'aime pouvoir lui donner trois dépôts git et des instructions pour générer un logiciel à partir d'un dépôt pour un autre via le troisième dépôt.
- Mais je ne veux pas le publier avant de réécrire et tout comprendre.
- Sans l'IA, je pourrais peut-être apprendre plus lentement avec l'aide d'Internet, qui a beaucoup de ressources commehttps://vitrinelinguistique.oqlf.gouv.qc.ca/Vitrine linguistique.
- Je veux profiter davantage, apprendre davantage avec l'aide de vraies personnes, complétée par l'aide de l'IA.
- J'adore les sous-titres simultanés, mais je n'ai pas toujours trouvé une méthode ou un système qui me convienne.
I can then go into the WhisperX transcription JSON file and replay those parts for closer review.
I can also tweak the context function to give me less information. For example, to limit it to the containing phrase, I can do this:
(defun my-split-string-keep-delimiters (string delimiter)
(when string
(let (results pos)
(with-temp-buffer
(insert string)
(goto-char (point-min))
(setq pos (point-min))
(while (re-search-forward delimiter nil t)
(push (buffer-substring pos (match-beginning 0)) results)
(setq pos (match-beginning 0)))
(push (buffer-substring pos (point-max)) results)
(nreverse results)))))
(ert-deftest my-split-string-keep-delimiters ()
(should
(equal (my-split-string-keep-delimiters
"Beaucoup de gens ont une réaction forte contre l'IA pour plusieurs raisons qui *incluent* le battage médiatique excessif dont elle fait l'objet, son utilisation à mauvais escient, et *l'inondation de banalité* qu'elle produit."
", \\| que \\| qui \\| qu'ils? \\| qu'elles? \\| qu'on "
)
)))
(defun my-lang-words-for-review-phrase-context (&optional s)
(setq s (replace-regexp-in-string " " " " (or s (sentence-at-point))))
(string-join
(seq-filter (lambda (s) (string-match "\\*" s))
(my-split-string-keep-delimiters s ", \\| parce que \\| que \\| qui \\| qu'ils? \\| qu'elles? \\| qu'on \\| pour "))
" ... "))
(ert-deftest my-lang-words-for-review-phrase-context ()
(should
(equal (my-lang-words-for-review-phrase-context
"Je peux consacrer une petite partie de mon *budget* à des essais, mais je ne veux pas travailler davantage pour rentabiliser une dépense plus importante.")
"Je peux consacrer une petite partie de mon *budget* à des essais")))
(let ((my-lang-words-for-review-context-function 'my-lang-words-for-review-phrase-context))
(my-lang-words-for-review "Sur l'intelligence artificielle"))
- pour faire des recherches.
- Je peux consacrer une petite partie de mon budget à des essais
- , et sinon
- J'ai une conscience aiguë des limites cognitives ou physiques à cause des difficultés de santé de ma mère et de ma sœur
- pour les longs contenus vidéo ou audio.
- Je n'aime pas les textes qui contiennent beaucoup de remplissage.
- qui incluent le battage médiatique excessif dont elle fait l'objet … , et l'inondation de banalité
- Je réécris souvent la majorité du logiciel à l'exception d'un ou deux morceaux
- pour les correctifs … parce que le code ne me semble pas correct et je ne veux pas gaspiller le temps d'autres bénévoles.
- pour un autre via le troisième dépôt.
- Mais je ne veux pas le publier avant de réécrire et tout comprendre.
- , je pourrais peut-être apprendre plus lentement avec l'aide d'Internet
- , apprendre davantage avec l'aide de vraies personnes, complétée par l'aide de l'IA.
- qui me convienne.
Now that I have a function for retrieving the HTML or Org Mode for a section, I can use that to wdiff against my current text to more easily spot wording changes.
(defun my-lang-tutor-notes-wdiff-org ()
(interactive)
(let ((section (org-entry-get (point) "ITEM")))
(my-wdiff-strings
(replace-regexp-in-string
" " " "
(my-org-subtree-text-without-blocks))
(replace-regexp-in-string
" " " "
(my-lang-tutor-notes section)))))
Related:
my-wdiff-stringsis in Wdiffmy-org-subtree-text-without-blocksis in Counting words without blocks
Screenshot: