Windows: Pipe output to your clipboard, or how I’ve been using NodeJS and Org Mode together
Posted: - Modified: | emacs, geekIt's not easy
instead of one of the more scriptable operating systems out there, but I stay on it because I like the drawing programs. Cygwin and Vagrant fill enough gaps to keep me mostly sane. (Although maybe I should work up the courage to dual-boot Windows 8.1 and a Linux distribution, and then get my ScanSnap working.)
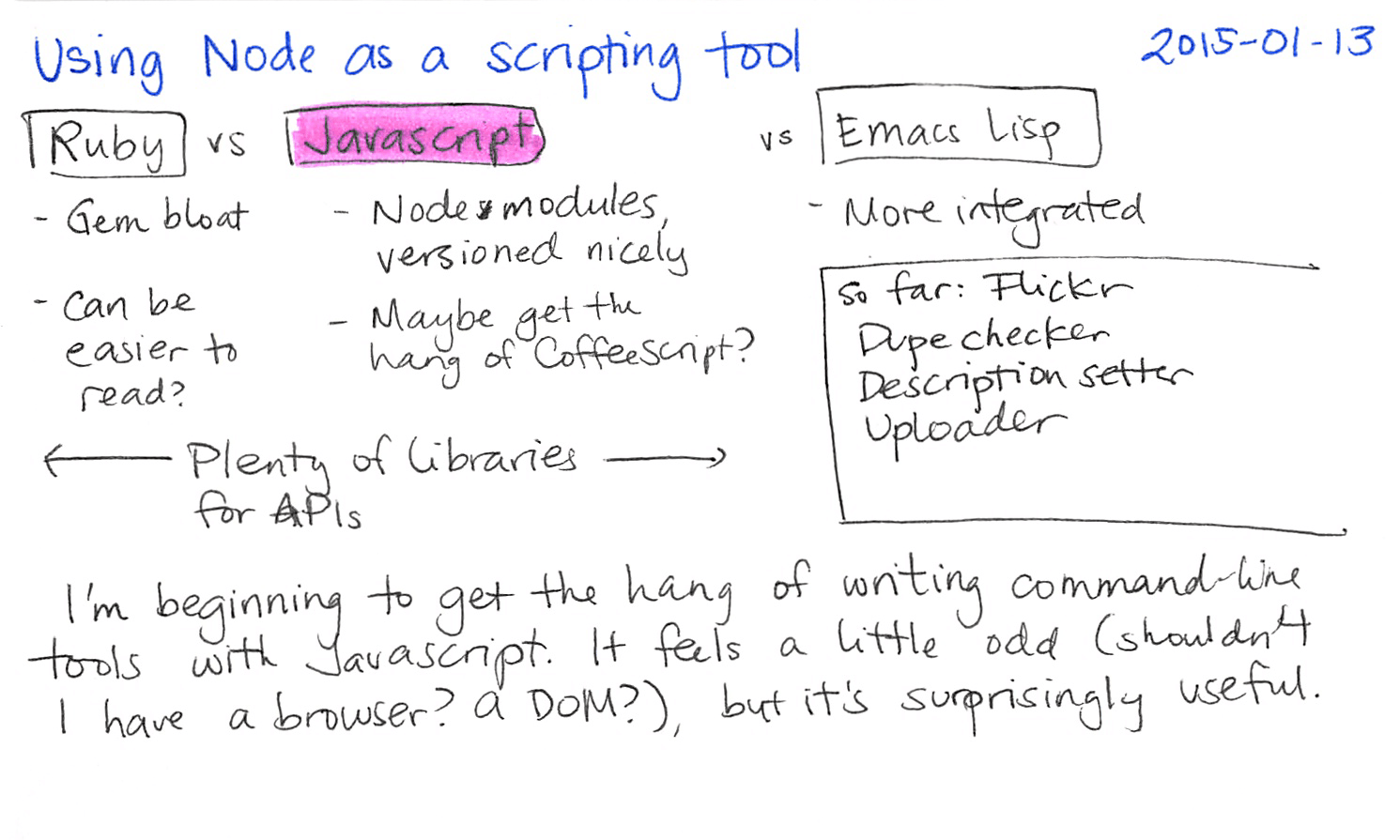
Anyway, I'm making do. Thanks to Node and the abundance of libraries available through NPM, Javascript is shaping up to be a surprisingly useful scripting language.
After I used the Flickr API library for Javascript to cross-reference my Flickr archive with my blog posts, I looked around for other things I could do with it. photoSync occasionally didn't upload new pictures I added to its folders (or at least, not as quickly as I wanted). I wanted to replace photoSync with my own script that would:
- upload the picture only if it doesn't already exist,
- add tags based on the filename,
- add the photo to my Sketchbook photoset,
- move the photo to the "To blog" folder, and
- make it easy for me to refer to the Flickr image in my blog post or index.
The flickr-with-uploads library made it easy to upload images and retrieve information, although the format was slightly different from the Flickr API library I used previously. (In retrospect, I should've checked the Flickr API documentation first – there's an example upload request right on the main page. Oh well! Maybe I'll change it if I feel like rewriting it.)
I searched my existing photos to see if a photo with that title already existed. If it did, I displayed an Org-style list item with a link. If it didn't exist, I uploaded it, set the tags, added the item to the photo set, and moved it to the folder. Then I displayed an Org-style link, but using a plus character instead of a minus character, taking advantage of the fact that both + and – can be used for lists in Org.
While using console.log(...) to display these links in the terminal allowed me to mark and copy the link, I wanted to go one step further. Could I send the links directly to Emacs? I looked into getting org-protocol to work, but I was having problems figuring this out. (I solved those problems; details later in this post.)
What were some other ways I could get the information into Emacs aside from copying and pasting from the terminal window? Maybe I could put text directly into the clipboard. The node-clipboard package didn't build for me and I couldn't get node-copy-paste to work either,about the node-copy-paste README told me about the existence of the clip command-line utility, which worked for me.
On Windows, clip allows you to pipe the output of commands into your clipboard. (There are similar programs for Linux or Mac OS X.) In Node, you can start a child process and communicate with it through pipes.
I got a little lost trying to figure out how to turn a string into a streamable object that I could set as the new standard input for the clip process I was going to spawn, but the solution turned out to be much simpler than that. Just write(...) to the appropriate stream, and call end() when you're done.
Here's the relevant bit of code that takes my result array and puts it into my clipboard:
var child = cp.spawn('clip'); child.stdin.write(result.join("\n")); child.stdin.end();
Of course, to get to that point, I had to revise my script. Instead of letting all the callbacks finish whenever they wanted, I needed to be able to run some code after everything was done. I was a little familiar with the async library, so I used that. I copied the output to the clipboard instead of displaying it so that I could call it easily using ! (dired-do-shell-command) and get the output in my clipboard for easy yanking elsewhere, although I could probably change my batch file to pipe the result to clip and just separate the stderr stuff. Hmm. Anyway, here it is!
/**
* Upload the file to my Flickr sketchbook and then move it to
* Dropbox/Inbox/To blog. Save the Org Mode links in the clipboard. -
* means the photo already existed, + means it was uploaded.
*/
var async = require('async');
var cp = require('child_process');
var fs = require('fs');
var glob = require('glob');
var path = require('path');
var flickr = require('flickr-with-uploads');
var secret = require("./secret");
var SKETCHBOOK_PHOTOSET_ID = '72157641017632565';
var BLOG_INBOX_DIRECTORY = 'c:\\sacha\\dropbox\\inbox\\to blog\\';
var api = flickr(secret.flickrOptions.api_key,
secret.flickrOptions.secret,
secret.flickrOptions.access_token,
secret.flickrOptions.access_token_secret);
var result = [];
function getTags(filename) {
var tags = [];
var match;
var re = new RegExp('#([^ ]+)', 'g');
while ((match = re.exec(filename)) !== null) {
tags.push(match[1]);
}
return tags.join(' ');
}
// assert(getTags("foo #bar #baz qux") == "bar baz");
function checkIfPhotoExists(filename, doesNotExist, existsFunction, done) {
var base = path.basename(filename).replace(/.png$/, '');
api({method: 'flickr.photos.search',
user_id: secret.flickrOptions.user_id,
text: base},
function(err, response) {
var found = undefined;
if (response && response.photos[0].photo) {
for (var i = 0; i < response.photos[0].photo.length; i++) {
if (response.photos[0].photo && response.photos[0].photo[i]['$'].title == base) {
found = i; break;
}
}
}
if (found !== undefined) {
existsFunction(response.photos[0].photo[found], done);
} else {
doesNotExist(filename, done);
}
});
}
function formatExistingPhotoAsOrg(photo, done) {
var title = photo['$'].title;
var url = 'https://www.flickr.com/photos/'
+ photo['$'].owner
+ '/' + photo['$'].id;
result.push('- [[' + url + '][' + title + ']]');
done();
}
function formatAsOrg(response) {
var title = response.photo[0].title[0];
var url = response.photo[0].urls[0].url[0]['_'];
result.push('+ [[' + url + '][' + title + ']]');
}
function uploadImage(filename, done) {
api({
method: 'upload',
title: path.basename(filename.replace(/.png$/, '')),
is_public: 1,
hidden: 1,
safety_level: 1,
photo: fs.createReadStream(filename),
tags: getTags(filename.replace(/.png$/, ''))
}, function(err, response) {
if (err) {
console.log('Could not upload photo: ', err);
done();
} else {
var newPhoto = response.photoid[0];
async.parallel(
[
function(done) {
api({method: 'flickr.photos.getInfo',
photo_id: newPhoto}, function(err, response) {
if (response) { formatAsOrg(response); }
done();
});
},
function(done) {
api({method: 'flickr.photosets.addPhoto',
photoset_id: SKETCHBOOK_PHOTOSET_ID,
photo_id: newPhoto}, function(err, response) {
if (!err) {
moveFileToBlogInbox(filename, done);
} else {
console.log('Could not add ' + filename + ' to Sketchbook');
done();
}
});
}],
function() {
done();
});
}
});
}
function moveFileToBlogInbox(filename, done) {
fs.rename(filename, BLOG_INBOX_DIRECTORY + path.basename(filename),
function(err) {
if (err) { console.log(err); }
done();
});
}
var arguments = process.argv.slice(2);
async.each(arguments, function(item, done) {
if (item.match('\\*')) {
glob.glob(item, function(err, files) {
if (!files) return;
async.each(files, function(file, done) {
checkIfPhotoExists(file, uploadImage, formatExistingPhotoAsOrg, done);
}, function() {
done();
});
});
} else {
checkIfPhotoExists(item, uploadImage, formatExistingPhotoAsOrg, done);
}
}, function(err) {
console.log(result.join("\n"));
var child = cp.spawn('clip');
child.stdin.write(result.join("\n"));
child.stdin.end();
});
Wheeee! Hooray for automation. I made a Windows batch script like so:
up.bat
node g:\code\node\flickr-upload.js %*
and away I went. Not only did I have a handy way to process images from the command line, I could also mark the files in Emacs Dired with m, then type ! to execute my up command on the selected images. Mwahaha!
Anyway, I thought I'd write it up in case other people were curious about using Node to code little utilities, filling the clipboard in Windows, or getting data back into Emacs (sometimes the clipboard is enough).
Back to org-protocol, since I was curious about it. With (require 'org-protocol) (server-start), emacsclient org-protocol://store-link:/foo/bar worked when I entered it at the command prompt. I was having a hard time getting it to work under Node, but eventually I figured out that:
- I needed to pass
-nas one of the arguments toemacsclientso that it would return right away. - The
:afterstore-linkis important! I was passingorg-protocol://store-link/foo/barand wondering why it opened up a file calledbar.org-protocol://store-link:/foo/barwas what I needed.
I only just figured out that last bit while writing this post. Here's a small demonstration program:
var cp = require('child_process');
var child = cp.execFile('emacsclient', ['-n', 'org-protocol://store-link:/foo/bar']);
Yay!