Audio braindump workflow tweaks: Adding Org Mode hyperlinks to recordings based on keywords
| speech, speechtotext, emacsAdded a quick video!

Audio recording is handy for capturing thoughts as I wait, walk around, or do chores. But my wireless earbuds don't have a good mic, I rarely got back to reviewing the wall of text, and I don't trust speech recognition to catch all my words.
Here's a new brain-dumping workflow that I've been experimenting with, though. I use a lapel mic to record in my phone. Google Recorder gives me an audio file as well as a rough transcript right away.
Animated GIF showing Google Recorder 's real-time transcript
I copy those with Syncthing.
If I use keywords like "start" or "stop" along with things like "topic", "reminder", or "summary", then I can put those on separate lines automatically (my-transcript-prepare-alignment-breaks).
... News. Miscellaneous little tasks that he doing. I do want to finish that blog post about the playlist Just so that it's out. Something else that people can, you know, refer to or that I can refer to. Uh, And at some point I want to think about, This second brain stuff. So, right now, What's my current state? Uh, START CHAPTER second brain STOP CHAPTER Right now, I dumped everything into originally. In my inbox, if I come across an interesting website. As usually in my phone. So then I share it. As. Something links at those or four none. Uh, into my inbox. ...
I use subed-align to get the timestamps, and add the headings.
00:20:18.680 --> 00:20:24.679 So, right now, What's my current state? Uh, NOTE CHAPTER: second brain 00:20:24.680 --> 00:20:30.719 START CHAPTER second brain STOP CHAPTER
I can then create an Org Mode TODO item with a quick hyperlinked summary as well as my transcript.

I can jump to the audio if there are misrecognized words.
Screenshot of jumping to the audio
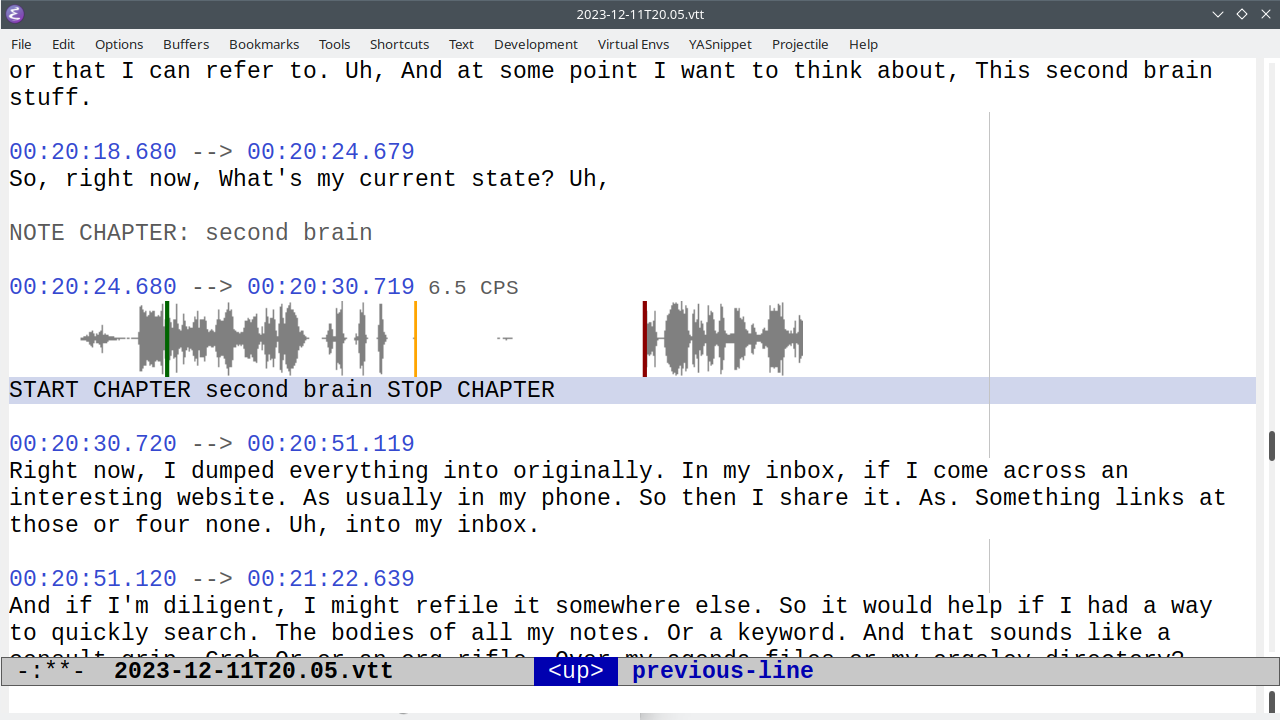
I can use subed-waveform to tweak the start and end times. (subed-waveform-show-current, then left-clicking to set the start or right-clicking to set the end, or using keybindings to adjust the start/stop).
Someday I'll write code to send sections to a better speech recognition engine or to AI. In the meantime, this is pretty good.
Here's how the code works:
Recognizing keyword phrases
There are several things I want to do while dictating.
- I want to mark different topics so that it's easy to find the section where I was talking about something.
- I might want to set tags or priorities, or even schedule something (today, tomorrow, next week, next month).
- I can also use commands to trigger different things, like sending the section to a better speech recognition engine.
By analyzing the text, I might be able to make my own command system.
So far, for starting keywords, I can use "start", "begin", or "open". I pair that with one of these part keywords:
- "section", "chapter", "topic", "summary": I use these pretty interchangeably at the moment. I want them to make a new Org heading.
- "next steps": could be handy for being able to quickly see what to do next
- "reminder":
- "interruption": don't know what I'll use this for yet, but it might be useful to note this.
- "tag", "keyword": maybe use this to add tags to the current section?
Then the code can extract the text until the matching "stop/close/end
<part>", assuming it happens within 50 words or so.
(my-transcript-close-keyword-distance-words)
Sometimes keywords get misrecognized. "Begin summary" sometimes becomes "again summary" or "the game summary". I could try "open" and "close". Commercial dictation programs like Dragon NaturallySpeaking use "open" and "close" for punctuation, so that would probably work fine. "Start" works well, but "end" doesn't because it can confused with "and".
Sometimes an extra word sneaks in, either because I say it or because
the speech recognition tries too hard to guess. "Begin reminder" ends
up as "Begin a reminder." I changed from using regular expressions
that searched for just start-keyword + part-keyword to one that looked
for the start of the keyword phrase and then looked for the next
keyword within the next X words. (my-transcript-scan-for-part-keyword)
Recognizing phrases
(defvar my-transcript-open-keywords '("start" "begin" "open")) (defvar my-transcript-close-keywords '("stop" "end" "close")) (defvar my-transcript-part-keywords '("summary" "chapter" "topic" "section" "action" "idea" "journal" "reminder" "command" "interruption" "note" "next step" "next steps" "tags" "tag" "keywords" "keyword")) (defvar my-transcript-part-keyword-distance-words 2 "Number of words to scan for part keyword.") (defvar my-transcript-close-keyword-distance-words 50 "number of words to scan for stop keyword. Put the keywords on the same line if found.") (defun my-transcript-scan-for-part-keyword (before-part &optional part-keywords within-distance before-distance) "Look for BEFORE-PART followed by PART-KEYWORDS. There might be WITHIN-DISTANCE words between BEFORE-PART and PART-KEYWORDS, and the pair might be within BEFORE-DISTANCE from point. Distances are in words. Return (start end before-part part) if found, nil otherwise." (setq before-part (pcase before-part ('start my-transcript-open-keywords) ('stop my-transcript-close-keywords) ('nil (append my-transcript-open-keywords my-transcript-close-keywords)) (_ before-part))) (setq part-keywords (or part-keywords my-transcript-part-keywords)) (when (stringp part-keywords) (setq part-keywords (list part-keywords))) (setq within-distance (or within-distance my-transcript-part-keyword-distance-words)) (setq before-distance (if (eq before-distance t) (point-max) (or before-distance my-transcript-close-keyword-distance-words))) (let (result start end (before-point (save-excursion (forward-word before-distance) (point))) before-word part-word) (save-excursion (when (looking-at (regexp-opt before-part)) (setq before-word (match-string 0) start (match-beginning 0)) (when (re-search-forward (regexp-opt part-keywords) (save-excursion (forward-word within-distance) (point)) t) (setq result (list start (match-end 0) before-word (match-string 0))))) (while (and (not result) (re-search-forward (regexp-opt before-part) before-point t)) (setq before-word (match-string 0) start (match-beginning 0)) (when (re-search-forward (regexp-opt part-keywords) (save-excursion (forward-word within-distance) (point)) t) (setq result (list start (match-end 0) before-word (match-string 0))))) (when result (goto-char (elt result 1))) result))) (ert-deftest my-transcript-scan-for-part-keyword () (with-temp-buffer (insert "some text start a reminder hello world stop there and do something stop reminder more text") (goto-char (point-min)) (let ((result (my-transcript-scan-for-part-keyword 'start nil))) (expect (elt result 2) :to-equal "start") (expect (elt result 3) :to-equal "reminder")) (let ((result (my-transcript-scan-for-part-keyword 'stop "reminder"))) (expect (elt result 2) :to-equal "stop") (expect (elt result 3) :to-equal "reminder"))))
Splitting the lines based on keywords and oopses
Now I can use that to scan through the text. I want to put commands on
their own lines so that subed-align will get the timestamp for that
segment and so that the commands are easier to parse.
I also want to detect "oops" and split things up so that the start of
that line matches my correction after the "oops". I use
my-subed-split-oops for that, which I should write about in another
post. By putting the oops fragment on its own line, I can use
subed-align to get a timestamp for just that segment. Then I can
either use flush-lines to get rid of anything with "oops" in it. I
can even remove the subtitle and use subed-record-compile-media to
compile audio/video without that segment, if I want to use the audio
without rerecording it.
And the way I can help is by jotting words down in a mind map, typing her sentences. Oops typing, her sentences And generating, follow-up questions.
I also all-caps the keyword phrases so that they're easier to see when skimming the text file.
Alignment breaks
(defun my-transcript-prepare-alignment-breaks () "Split lines in preparation for forced alignment with aeneas. Split \"oops\" so that it's at the end of the line and the previous line starts with roughly the same words as the next line, for easier removal. Add a linebreak before \"begin/start\" followed by `my-transcript-part-keywords'. Add a linebreak after \"stop\" followed by `my-transcript-part-keywords'. Look for begin keyword ... stop keyword with at most `my-transcript-part-keyword-distance-words' between them and put them on one line." (interactive) (let ((case-fold-search t) result close-result) (my-split-oops) ;; break "begin/start keyword" (goto-char (point-min)) (while (setq result (my-transcript-scan-for-part-keyword 'start nil nil t)) (goto-char (car result)) (delete-region (car result) (elt result 1)) (insert "\n" (upcase (concat (elt result 2) " " (elt result 3))) "\n")) ;; break stop (goto-char (point-min)) (while (setq result (my-transcript-scan-for-part-keyword 'stop nil nil t)) (goto-char (car result)) (delete-region (car result) (elt result 1)) (insert (upcase (concat (elt result 2) " " (elt result 3))) "\n")) ;; try to get start and end sections on one line (goto-char (point-min)) (while (setq result (my-transcript-scan-for-part-keyword 'start nil nil t)) (goto-char (elt result 1)) (setq stop-result (my-transcript-scan-for-part-keyword 'stop (elt result 3))) (if stop-result (progn (goto-char (car stop-result)) (while (re-search-backward " *\n+ *" (car result) t) (replace-match " "))) ;; no stop keyword; are we on an empty line? If so, just merge it with the next one (when (looking-at "\n+ *") (replace-match " ")))) ;; remove empty lines (goto-char (point-min)) (when (looking-at "\n+") (replace-match "")) (while (re-search-forward "\n\n+" nil t) (replace-match "\n")) (goto-char (point-min)) (while (re-search-forward " *\n *" nil t) (replace-match "\n")))) (ert-deftest my-transcript-prepare-alignment-breaks () (with-temp-buffer (insert "some text start a reminder hello world stop there and do something stop reminder more text") (goto-char (point-min)) (my-transcript-prepare-alignment-breaks) (expect (buffer-string) :to-equal "some text START REMINDER hello world stop there and do something STOP REMINDER more text")))
Preparing the VTT subtitles
subed-align gives me a VTT subtitle file with timestamps and text. I
add NOTE comments with the keywords and make subed: links to the
timestamps using the ol-subed.el that I just added.
Putting keyword phrases in comments
(defun my-transcript-get-subtitle-note-based-on-keywords (sub-text) (let ((case-fold-search t)) (when (string-match (concat "^" (regexp-opt my-transcript-open-keywords) " \\(" (regexp-opt my-transcript-part-keywords) "\\) \\(.+?\\)\\( " (regexp-opt my-transcript-close-keywords) " " (regexp-opt my-transcript-part-keywords) "\\)?$") sub-text) (concat (match-string 1 sub-text) ": " (match-string 2 sub-text))))) (ert-deftest my-transcript-get-subtitle-note-based-on-keywords () (expect (my-transcript-get-subtitle-note-based-on-keywords "BEGIN NEXT STEPS . Think about how dictation helps me practice slower speed. CLOSE NEXT STEPS") :to-equal "NEXT STEPS: . Think about how dictation helps me practice slower speed.") (expect (my-transcript-get-subtitle-note-based-on-keywords "START SUMMARY hello world STOP SUMMARY") :to-equal "SUMMARY: hello world") (expect (my-transcript-get-subtitle-note-based-on-keywords "START CHAPTER hello world again") :to-equal "CHAPTER: hello world again") )
Formatting the subtitles into Org Mode subtrees
The last step is to take the list of subtitles and format it into the subtree.
Formatting the subtree
;; todo: sort the completion? https://emacs.stackexchange.com/questions/55502/list-files-in-directory-in-reverse-order-of-date ;; (defun my-transcript-insert-subtitles-as-org-tree (vtt-filename) (interactive (list (read-file-name "VTT: " (expand-file-name "./" my-phone-recording-dir) nil t nil (lambda (s) (string-match "\\.vtt$" s))))) (let* ((subtitles (mapcar (lambda (sub) (unless (elt sub 4) (setf (elt sub 4) (my-transcript-get-subtitle-note-based-on-keywords (elt sub 3)))) sub) (subed-parse-file vtt-filename))) (start-date (my-transcript-get-file-start-time vtt-filename)) chapters tags start-of-entry) (setq start-of-entry (point)) (insert (format "* TODO Review braindump from %s :braindump:\n\n" (file-name-base vtt-filename))) (org-entry-put (point) "CREATED" (concat "[" (format-time-string (cdr org-timestamp-formats) (my-transcript-get-file-start-time (file-name-nondirectory vtt-filename))) "]")) (insert (format "%s - %s - %s\n" (org-link-make-string (concat "file:" (file-name-sans-extension vtt-filename) ".vtt") "VTT") (org-link-make-string (concat "file:" (file-name-sans-extension vtt-filename) ".txt") "Text") (org-link-make-string (concat "file:" (file-name-sans-extension vtt-filename) ".m4a") "Audio"))) (save-excursion (insert "** Transcript\n") ;; add each subtitle; add an ID in case we change the title (mapc (lambda (sub) (when (elt sub 4) (let ((note (my-transcript-get-subtitle-note-based-on-keywords (elt sub 3)))) (insert (concat "*** " note " " (org-link-make-string (format "subed:%s::%s" vtt-filename (my-msecs-to-timestamp (elt sub 1))) "VTT") "\n\n")) (org-entry-put (point) "CREATED" (concat "[" (format-time-string (cdr org-timestamp-formats) (time-add start-date (seconds-to-time (/ (elt sub 1) 1000.0)))) "]")) (org-entry-put (point) "START" (my-msecs-to-timestamp (elt sub 2))) (when (elt sub 4) (when (string-match "command: .*recognize" (elt sub 4)) (save-excursion ;; TODO: scope this to just the section someday (goto-char start-of-entry) (org-set-tags (append (list "recognize") (org-get-tags))))) (when (string-match "command: .*outline" (elt sub 4)) (save-excursion (goto-char start-of-entry) (org-set-tags (append (list "outline") (org-get-tags))))) (when (string-match "^time" (elt sub 4)) (insert "[" (org-format-time-string (cdr org-timestamp-formats) (time-add start-date (seconds-to-time (/ (elt sub 1) 1000)))) "]\n")) (when (string-match "command: .+\\(high\\|low\\)" (elt sub 4)) (save-excursion (goto-char start-of-entry) (org-priority (if (string= (downcase (match-string 1)) "high") ?A ?C)))) (when (string-match "\\(?:tags?\\|keywords?\\): \\(.+\\)" (elt sub 4)) (save-excursion (goto-char start-of-entry) (org-set-tags (append (split-string (match-string 1) " ") (org-get-tags)))))) (add-to-list 'chapters (format "- %s (%s)" (org-link-make-string (concat "id:" (org-id-get-create)) note) (org-link-make-string (format "subed:%s::%s" vtt-filename (my-msecs-to-timestamp (elt sub 1))) "VTT"))))) (insert (elt sub 3) "\n")) subtitles)) (when chapters (insert (string-join (nreverse chapters) "\n") "\n")))) (defun my-transcript-get-file-start-time (filename) (setq filename (file-name-base filename)) (cond ((string-match "^\\([0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]T[0-9][0-9]\\.[0-9][0-9]\\)" filename) (date-to-time (replace-regexp-in-string "\\." ":" (match-string 0 filename)))) ((string-match "^\\(?:Copy of \\)?\\([^ ][^ ][^ ]\\)[^ ]+ at \\([0-9]+\\)-\\([0-9]+\\)" filename) (let* ((day (match-string 1 filename)) (hour (match-string 2 filename)) (min (match-string 3 filename)) (changed-time (file-attribute-modification-time (file-attributes filename))) (decoded-time (decode-time changed-time))) ;; get the day on or before changed-time (if (string= (format-time-string "%a" changed-time) day) (encode-time (append (list 0 (string-to-number min) (string-to-number hour)) (seq-drop decoded-time 3))) ;; synchronized maybe within the week after (org-read-date t t (concat "-" day " " hour ":" min)))))))
Process a single transcript from the raw text file
So now we put that all together: rename the file using the calculated start time, prepare the alignment breaks, align the file to get the timestamps, and add the subtree to an Org file.
Making the TODO
(defvar my-transcript-braindump-file "~/sync/orgzly/braindump.org") (defun my-transcript-make-todo (text-file &optional force) "Add TEXT-FILE as a TODO." (interactive (list (buffer-file-name) current-prefix-arg)) ;; rename the files to use the timestamps (unless (string-match "^[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]" (file-name-base text-file)) (setq text-file (my-transcript-rename-files-based-on-time text-file))) (let* ((recording (concat (file-name-sans-extension text-file) ".m4a")) (start (my-transcript-get-file-start-time text-file)) (vtt (concat (file-name-sans-extension text-file) ".vtt")) chapters (title (concat "Review braindump " text-file)) existing) ;; check if already exists (with-current-buffer (find-file-noselect my-transcript-braindump-file) (save-excursion (goto-char (point-min)) (setq existing (org-find-exact-headline-in-buffer title)))) (if (and existing (not force)) (progn (message "Going to existing heading") (org-goto-marker-or-bmk existing)) (if (or (null my-transcript-last-processed-time) (time-less-p my-transcript-last-processed-time start)) (customize-save-variable 'my-transcript-last-processed-time start)) (find-file text-file) (my-transcript-prepare-alignment-breaks) (save-buffer) (when (file-exists-p vtt) (delete-file vtt)) (when (get-file-buffer vtt) (kill-buffer (get-file-buffer vtt))) (subed-align recording text-file "VTT") (when (get-file-buffer vtt) (kill-buffer (get-file-buffer vtt))) (find-file my-transcript-braindump-file) (goto-char (point-min)) (if existing (progn (org-goto-marker-or-bmk existing) (delete-region (point) (org-end-of-subtree))) (org-next-visible-heading 1)) (my-transcript-insert-subtitles-as-org-tree vtt))))
Process multiple files
I want to process multiple files in one batch.
(defun my-transcript-process (files &optional force) (interactive (list (cond ((and (derived-mode-p 'dired-mode) (dired-get-marked-files)) (dired-get-marked-files)) ((derived-mode-p 'dired-mode) (list (dired-get-filename))) ((string-match "\\.txt$" (buffer-file-name)) (list (buffer-file-name))) (t (read-file-name "Transcript: "))) current-prefix-arg)) (mapc (lambda (f) (when (string-match "txt" f) (my-transcript-make-todo f force))) files))
It would be nice to have it automatically keep track of the latest one
that's been processed, maybe via customize-save-variable. This still
needs some tinkering with.
Processing new files
(defcustom my-transcript-last-processed-time nil "The timestamp of the last processed transcript." :group 'sacha :type '(repeat integer)) (defun my-transcript-process-since-last () (interactive) (let ((files (seq-filter (lambda (f) (or (null my-transcript-last-processed-time) (time-less-p my-transcript-last-processed-time (my-transcript-get-file-start-time f)))) (directory-files my-phone-recording-dir 'full " at [0-9][0-9]-[0-9][0-9]\\.txt\\|^[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]T[0-9][0-9]\\.[0-9][0-9]\\.txt")))) (mapc (lambda (f) (my-transcript-make-todo f) (let ((start (my-transcript-get-file-start-time f))) (if (time-less-p my-transcript-last-processed-time start) (setq my-transcript-last-processed-time start)))) files)) (customize-save-variable 'my-transcript-last-processed-time my-transcript-last-processed-time)) (defun my-transcript-rename-files-based-on-time (text-file) "Rename TEXT-FILE based on date. Return the new text file." (interactive (list (if (derived-mode-p 'dired-mode) (dired-get-filename) (buffer-file-name)))) (if (string-match "^[0-9][0-9][0-9][0-9]" text-file) text-file ; no change, already uses date (let* ((start (my-transcript-get-file-start-time (file-name-base text-file))) (new-base (format-time-string "%Y-%m-%dT%H.%M" start))) (if (file-exists-p (expand-file-name (concat new-base ".txt") (file-name-directory text-file))) (error "%s already exists" new-base) (dolist (ext '(".txt" ".m4a" ".vtt")) (if (file-exists-p (concat (file-name-sans-extension text-file) ext)) (rename-file (concat (file-name-sans-extension text-file) ext) (expand-file-name (concat new-base ext) (file-name-directory text-file))))) (expand-file-name (concat new-base ".txt") (file-name-directory text-file))))))
Ideas for next steps
- Make the commands process things even more automatically.
- Experiment with just sending everything to OpenAI Whisper instead of conditionally sending it based on the keywords (which might not be recognized).
- See if I want to reuse more sentences or move them around.
- Find out where people who have thought about dictation keywords have their notes; probably don't have to reinvent the wheel here