Categorizing Emacs News items by voice in Org Mode
| speech, speech-recognition, emacs, orgI'm having fun exploring which things might actually be easier to do by voice than by typing. For example, after I wrote some code to expand yasnippets by voice, I realized that it was easier to:
- press my shortcut,
- say "okay, define interactive function",
- and then press my shortcut again,
than to:
- mentally say it,
- get the first initials,
- type in "dfi",
- and press Tab to expand.
Another area where I do this kind of mental translation for keyboard shortcuts is when I categorize dozens of Emacs-related links each week for Emacs News. I used to do this by hand. Then I wrote a function to try to guess the category based on regular expressions (my-emacs-news-guess-category in emacs-news/index.org, which is large). Then I set up a menu that lets me press numbers corresponding to the most frequent categories and use tab completion for the rest. 1 is Emacs Lisp, 2 is Emacs development, 3 is Emacs configuration, 4 is appearance, 5 is navigation, and so on. It's not very efficient, but some of it has at least gotten into muscle memory, which is also part of why it's hard to change the mapping. I don't come across that many links for Emacs development or Spacemacs, and I could probably change them to something else, but… Anyway.

I wanted to see if I could categorize links by voice instead. I might not always be able to count on being able to type a lot, and it's always fun to experiment with other modes of input. Here's a demonstration showing how Emacs can automatically open the URLs, wait for voice input, and categorize the links using a reasonably close match. The *Messages* buffer displays the recognized output to help with debugging.
This is how it works:
- It starts an
ffmpegrecording process. - It starts Silero voice activity detection.
- When it detects that speech has ended, it use
curlto send the WAV to an OpenAI-compatible server (in my case, Speaches with theSystran/faster-whisper-base.enmodel) for transcription, along with a prompt to try to influence the recognition. - It compares the result with the candidates using
string-distancefor an approximate match. It calls the code to move the current item to the right category, creating the category if needed.
Since this doesn't always result in the right match, I added an Undo command. I also have a Delete command for removing the current item, Scroll Up and Scroll Down, and a way to quit.
Initial thoughts
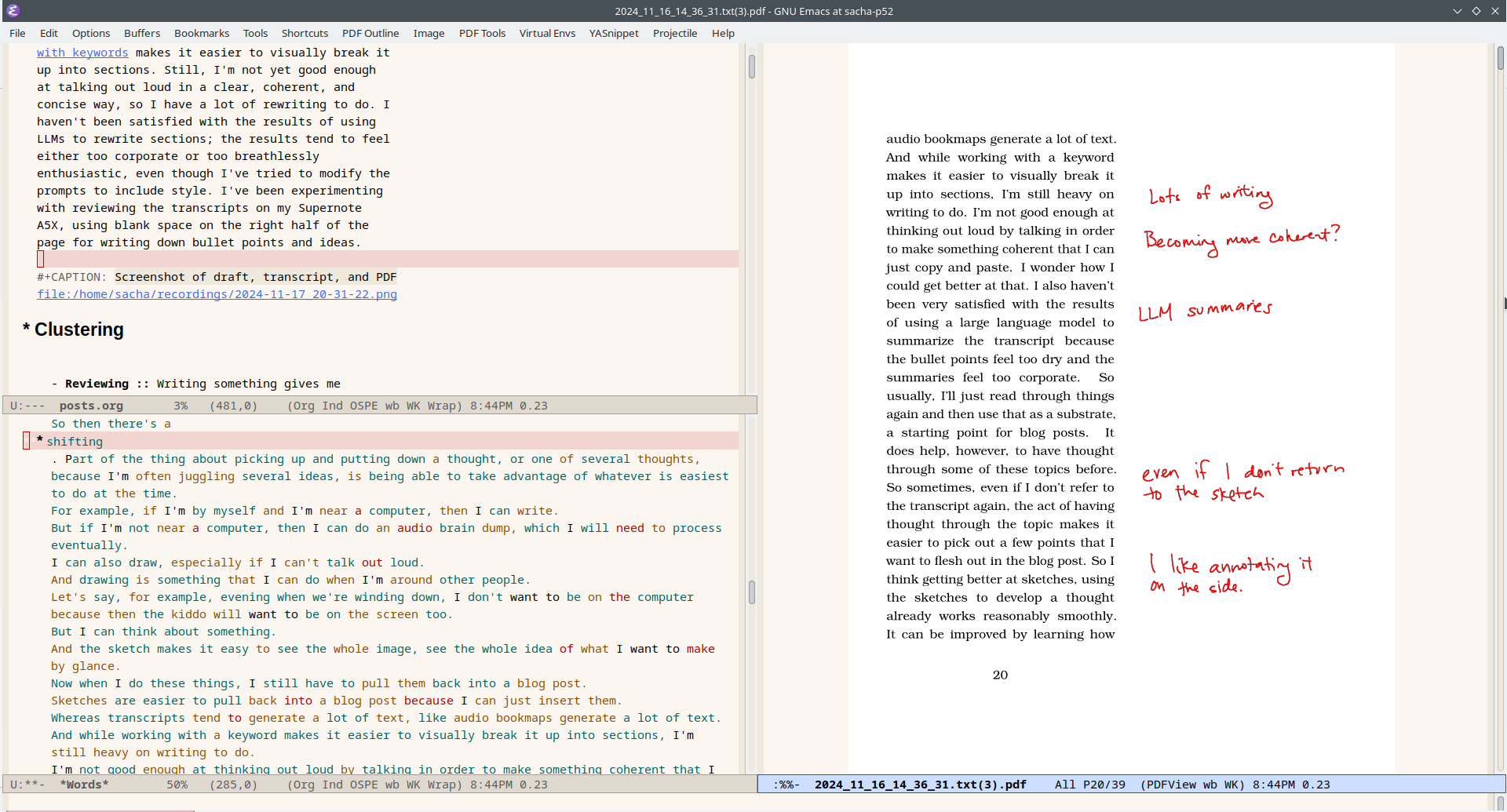
I used it to categorize lots of links in this week's Emacs News, and I think it's promising. I loved the way my hands didn't have to hover over the number keys or move between those and the characters. Using voice activity detection meant that I could just keep dictating categories instead of pressing keyboard shortcuts or using the foot pedal I recently dusted off. There's a slight delay, of course, but I think it's worth it. If this settles down and becomes a solid part of my workflow, I might even be able to knit or hand-sew while doing this step, or simply do some stretching exercises.
What about using streaming speech recognition? I've written some code to use streaming speech recognition, but the performance wasn't good enough when I tried it on my laptop (Lenovo P52 released in 2018, no configured GPU under Linux). The streaming server dropped audio segments in order to try to catch up. I'd rather have everything transcribed at the level of the model I want, even if I have to wait a little while. I also tried using the Web Speech API in Google Chrome for real-time speech transcription, but it's a little finicky. I'm happy with the performance I get from either manually queueing speech segments or using VAD and then using batch speech recognition with a model that's kept in memory (which is why I use a local server instead of a command-line tool). Come to think of it, I should try this with a higher-quality model like medium or large, just in case the latency turns out to be not that much more for this use case.
What about external voice control systems like Talon Voice or Cursorless? They seem like neat ideas and lots of people use them. I think hacking something into Emacs with full access to its internals could be lots of fun too.
A lot of people have experimented with voice input for Emacs over the years. It could be fun to pick up ideas for commands and grammars. Some examples:
- Using Python to Code by Voice - YouTube (2013)
- jgarvin/mandimus: Use speech recognition to command your computer and Emacs. · GitHub
- ErikPrantare/cursorfree.el: Edit and navigate from anywhere in the buffer · GitHub
- ~lepisma/emacs-speech-input - uses the idea of a voice cursor, uses an LLM to execute editing instructions
What about automating myself out of this loop? I've considered training a classifier or sending the list to a large language model to categorize links in order to set more reasonable defaults, but I think I'd still want manual control, since the fun is in getting a sense of all the cool things that people are tinkering around with in the Emacs community. I found that with voice control, it was easier for me to say the category than to look for the category it suggested and then say "Okay" to accept the default. If I display the suggested category in a buffer with very large text (and possibly category-specific background colours), then I can quickly glance at it or use my peripheral vision. But yeah, it's probably easier to look at a page and say "Org Mode" than to look at the page, look at the default text, see if it matches Org Mode, and then say okay if it is.
Ideas for next steps
I wonder how to line up several categories. I could probably rattle off a few without waiting for the next one to load, and just pause when I'm not sure. Maybe while there's a reasonably good match within the first 1-3 words, I'll take candidates from the front of the queue. Or I could delimit it with another easily-recognized word, like "next".
I want to make a more synchronous version of this idea so that I can have a speech-enabled drop-in replacement that I can use as my y-or-n-p while still being able to type y or n. This probably involves using sit-for and polling to see if it's done. And then I can use that to play Twenty Questions, but also to do more serious stuff. It would also be nice to have replacements for read-string and completing-read, since those block Emacs until the user enters something.
I might take a side-trip into a conversational interface for M-x doctor and M-x dunnet, because why not. Naturally, it also makes sense to voice-enable agent-shell and gptel interactions.
I'd like to figure out a number- or word-based completion mechanism so that I can control Reddit link replacement as well, since I want to select from a list of links from the page. Maybe something similar to the way voicemacs adds numbers to helm and company or how flexi-choose.el works.
I'm also thinking about how I can shift seamlessly between typing and speaking, like when I want to edit a link title. Maybe I can check if I'm in the minibuffer and what kind of minibuffer I'm in, perhaps like the way Embark does.
It would be really cool to define speech commands by reusing the keymap structure that menus also use. This is how to define a menu in Emacs Lisp:
(easy-menu-define words-menu global-map
"Menu for word navigation commands."
'("Words"
["Forward word" forward-word]
["Backward word" backward-word]))
and this is how to set just one binding:
(keymap-set-after my-menu "<drink>"
'("Drink" . drink-command) 'eat)
That makes sense to reuse for speech commands. I'd also like to be able to specify aliases while hiding them or collapsing them for a "What can I say" help view… Also, if keymaps work, then maybe minor modes or transient maps could work? This sort of feels like it should be the voice equivalent of a transient map.
The code so far
(defun my-emacs-news-categorize-with-voice (&optional skip-browse)
(interactive (list current-prefix-arg))
(unless skip-browse
(my-spookfox-browse))
(speech-input-cancel-recording)
(let ((default (if (fboundp 'my-emacs-news-guess-category) (my-emacs-news-guess-category))))
(speech-input-from-list
(if default
(format "Category (%s): " default)
"Category: ")
'(("Org Mode" "Org" "Org Mode")
"Other"
"Emacs Lisp"
"Coding"
("Emacs configuration" "Config" "Configuration")
("Appearance" "Appearance")
("Default" "Okay" "Default")
"Community"
"AI"
"Writing"
("Reddit" "Read it" "Reddit")
"Shells"
"Navigation"
"Fun"
("Dired" "Directory" "Dir ed")
("Mail, news, and chat" "News" "Mail" "Chat")
"Multimedia"
"Scroll down"
"Scroll up"
"Web"
"Delete"
"Skip"
"Undo"
("Quit" "Quit" "Cancel" "All done"))
(lambda (result text)
(message "Recognized %s original %s" result text)
(pcase result
("Undo"
(undo)
(my-emacs-news-categorize-with-voice t))
("Skip"
(forward-line)
(my-emacs-news-categorize-with-voice))
("Quit"
(message "All done.")
(speech-input-cancel-recording))
("Reddit"
(my-emacs-news-replace-reddit-link)
(my-emacs-news-categorize-with-voice t))
("Scroll down"
(my-spookfox-scroll-down)
(my-emacs-news-categorize-with-voice t))
("Scroll up"
(my-spookfox-scroll-up)
(my-emacs-news-categorize-with-voice t))
("Delete"
(delete-line)
(undo-boundary)
(my-emacs-news-categorize-with-voice))
("Default"
(my-org-move-current-item-to-category
(concat default ":"))
(undo-boundary)
(my-emacs-news-categorize-with-voice))
(_
(my-org-move-current-item-to-category
(concat result ":"))
(undo-boundary)
(my-emacs-news-categorize-with-voice))))
t)))
It uses Spookfox to control Firefox from Emacs:
(defun my-spookfox-scroll-down ()
(interactive)
(spookfox-js-injection-eval-in-active-tab "window.scrollBy(0, document.documentElement.clientHeight);" t))
(defun my-spookfox-scroll-up ()
(interactive)
(spookfox-js-injection-eval-in-active-tab "window.scrollBy(0, -document.documentElement.clientHeight);"))
(defun my-spookfox-background-tab (url &rest args)
"Open URL as a background tab."
(if spookfox--connected-clients
(spookfox-tabs--request (cl-first spookfox--connected-clients) "OPEN_TAB" `(:url ,url))
(browse-url url)))
It also uses these functions for categorizing Org Mode items:
(defun my-org-move-current-item-to-category (category)
"Move current list item under CATEGORY earlier in the list.
CATEGORY can be a string or a list of the form (text indent regexp).
Point should be on the next line to process, even if a new category
has been inserted."
(interactive (list (completing-read "Category: " (my-org-get-list-categories))))
(when category
(let* ((col (current-column))
(item (point-at-bol))
(struct (org-list-struct))
(category-text (if (stringp category) category (elt category 0)))
(category-indent (if (stringp category) 2 (+ 2 (elt category 1))))
(category-regexp (if (stringp category) category (elt category 2)))
(end (elt (car (last struct)) 6))
(pos (point))
s)
(setq s (org-remove-indentation (buffer-substring-no-properties item (org-list-get-item-end item struct))))
(save-excursion
(if (string= category-text "x")
(org-list-send-item item 'delete struct)
(goto-char (caar struct))
(if (re-search-forward (concat "^ *- +" category-regexp) end t)
(progn
;; needs a patch to ol.el to check if stringp
(org-list-send-item item (point-at-bol) struct)
(org-move-item-down)
(org-indent-item))
(goto-char end)
(org-list-insert-item
(point-at-bol)
struct (org-list-prevs-alist struct))
(let ((old-struct (copy-tree struct)))
(org-list-set-ind (point-at-bol) struct 0)
(org-list-struct-fix-bul struct (org-list-prevs-alist struct))
(org-list-struct-apply-struct struct old-struct))
(goto-char (point-at-eol))
(insert category-text)
(org-list-send-item item 'end struct)
(org-indent-item)
(org-indent-item))
(recenter))))))
(defun my-org-guess-list-category (&optional categories)
(interactive)
(require 'cl-lib)
(unless categories
(setq categories
(my-helm-org-list-categories-init-candidates)))
(let* ((beg (line-beginning-position))
(end (line-end-position))
(string (buffer-substring-no-properties beg end))
(found
(cl-member string
categories
:test
(lambda (string cat-entry)
(unless (string= (car cat-entry) "x")
(string-match (regexp-quote (downcase (car cat-entry)))
string))))))
(when (car found)
(my-org-move-current-item-to-category
(cdr (car found)))
t)))
For the speech-input functions, experimental code is at https://codeberg.org/sachac/speech-input .