Using subed-record in Emacs to edit audio and clean up oopses
| emacs, subedFinding enough quiet focused time to record audio is a challenge. I often have to re-record segments in order to correct brain hiccups or to restart after interruptions. It's also hard for me to sit still and listen to my recordings looking for mistakes to edit out. I'm not familiar enough with Audacity to zip around with keyboard shortcuts, and I don't like listening to myself again and again in order to find my way around an audio file.
Sure, I could take the transcript, align it with subed-align and
Aeneas to get the timestamps, and then use subed-convert to get a CSV (actually a TSV since it uses tabs)
that I can import into Audacity as labels, but it still feels a little
awkward to navigate. I have to zoom in a lot for the text to be
readable.
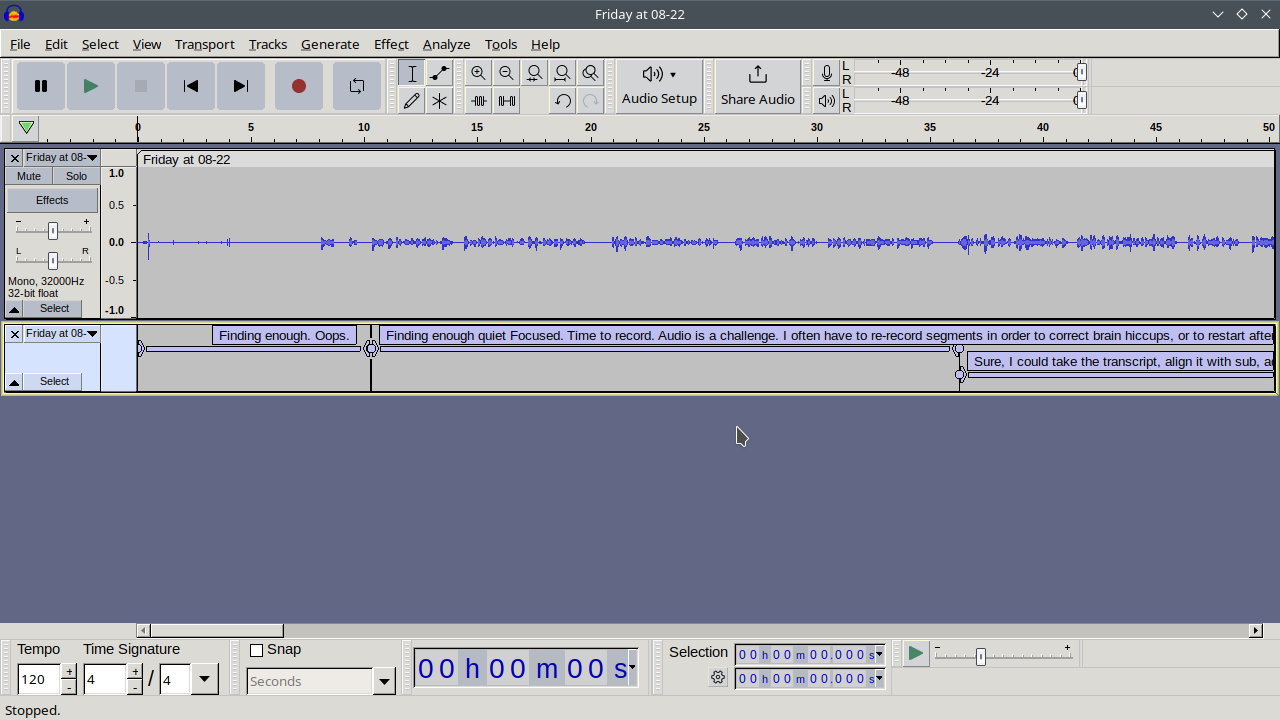
So here's a workflow I've been experimenting with for cleaning up my recorded audio.
Just like with my audio braindumps, I use Google Recorder on my phone
because I can get the audio file and a rough transcript, and because
the microphone on it is better than on my laptop. For narration
recordings, I hide in the closet because the clothes muffle echoes. I
don't feel as self-conscious there as I might be if I recorded in the
kitchen, where my computer usually is. I used to record in Emacs using
subed-record by pressing left to redo a segment and right to
move on to the next one, but using my phone means I don't have to deal
with the computer's noises or get the good mic from downstairs.
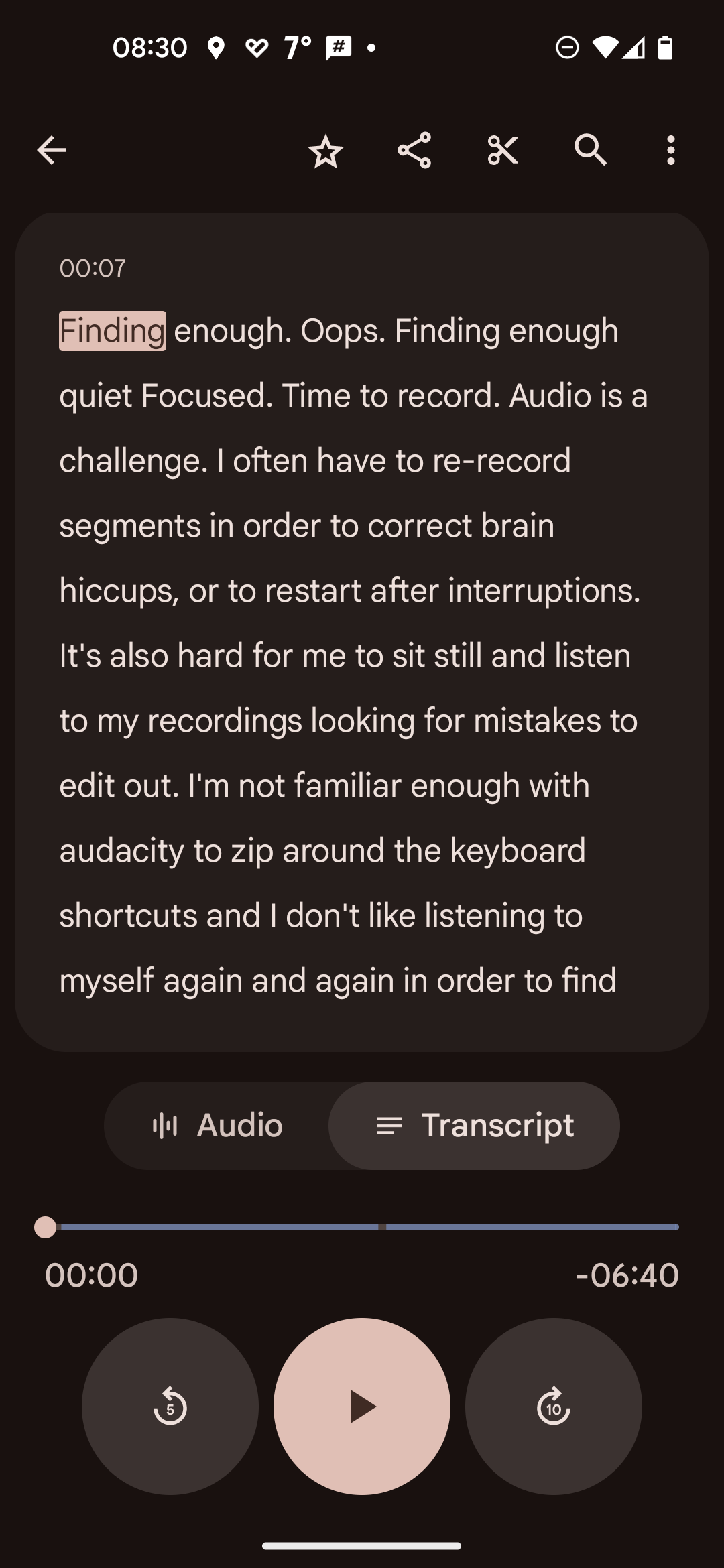
I start the recorder on my phone and then switch to my Org file in Orgzly Revived, where I've added my script. I read it as far as I can go. If I want to redo a segment, I say "Oops" and then just redo the last phrase or so.
Screenshot of Google Recorder on my phone
I export the transcript and the M4A audio file using Syncthing, which
copies them to my computer. I have a function that copies the latest
recording and even sets things up for removing oops segments
(my-subed-copy-latest-phone-recording, which calls my-split-oops).
If I want to process several files, I can copy them over with
my-subed-copy-recording.
my-subed-copy-latest-phone-recording: Copy the latest recording transcript and audio to DESTINATION.
(defun my-subed-copy-latest-phone-recording (destination) "Copy the latest recording transcript and audio to DESTINATION." (interactive (list (file-name-directory (read-file-name (format "Move %s to: " (file-name-base (my-latest-file my-phone-recording-dir ".txt"))) nil nil nil nil #'file-directory-p)))) (let ((base (file-name-base (my-latest-file my-phone-recording-dir ".txt")))) (rename-file (expand-file-name (concat base ".txt") my-phone-recording-dir) destination) (rename-file (expand-file-name (concat base ".m4a") my-phone-recording-dir) destination) (find-file (expand-file-name (concat base ".txt") destination)) (save-excursion (my-split-oops)) (goto-char (point-min)) (flush-lines "^$") (goto-char (point-min)) (subed-forward-subtitle-id) (subed-set-subtitle-comment (concat "#+OUTPUT: " (file-name-base (buffer-file-name)) "-cleaned.opus"))))
my-subed-copy-recording
(defun my-subed-copy-recording (filename destination) (interactive (list (buffer-file-name) (file-name-directory (read-file-name (format "Copy %s to: " (file-name-base (buffer-file-name))) nil nil nil nil #'file-directory-p)))) (dolist (ext '("m4a" "txt" "json" "vtt")) (when (file-exists-p (concat (file-name-sans-extension filename) "." ext)) (copy-file (concat (file-name-sans-extension filename) "." ext) destination t))) (when (get-file-buffer filename) (kill-buffer (get-file-buffer filename)) (dired destination)))
I'll use Aeneas to get the timestamps for each line of text, so a
little bit of text processing will let me identify the segments that I
want to remove. The way my-split-oops works is that it looks for
"oops" in the transcript. Whenever it finds "oops", it adds a newline
afterwards. Then it takes the next five words and sees if it can
search backward for them within 300 characters. If it finds the words,
then that's the start of my repeated segment, and we can add a newline
before that. If it doesn't find the words, we try again with four
words, then three, then two, then one. I can also manually review the
file and see if the oopses are well lined up. When they're detected
properly, I should see partially duplicated lines.
I used to record using sub-record by using by. Oops, I used to record. Oops, I used to record an emacs using subhead record, by pressing left to reduce segment, and write to move on to the next one. But using my phone means, I don't have to deal with them. Oops. But using my phone means, I don't have to deal with the computer's noises or get the good mic from downstairs. I started recorder on my phone
my-split-oops: Look for oops and make it easier to split.
(defun my-split-oops () "Look for oops and make it easier to split." (interactive) (let ((scan-window 300)) (while (re-search-forward "oops[,\.]?[ \n]+" nil t) (let ((start (min (line-beginning-position) (- (point) scan-window))) start-search found search-for) (if (bolp) (progn (backward-char) (setq start (min (line-beginning-position) (- (point) scan-window)))) (insert "\n")) (save-excursion (setq start-search (point)) ;; look for 1..5 words back (goto-char (or (cl-loop for n downfrom 5 downto 1 do (save-excursion (dotimes (_ n) (forward-word)) (setq search-for (downcase (string-trim (buffer-substring start-search (point))))) (goto-char start-search) (when (re-search-backward (regexp-quote search-for) start t) (goto-char (match-beginning 0)) (cl-return (point))))) (and (call-interactively 'isearch-backward) (point)))) (insert "\n"))))))
Once the lines are split up, I use subed-align and get a VTT file.
The oops segments will be in their own subtitles.
The timestamps still need a bit of tweaking sometimes, so I use
subed-waveform-show-current or subed-waveform-show-all. I can use
the following bindings:
- middle-click to play a sample
- M-left-click to set the start and copy to the previous subtitle
- left-click to set the start without changing the previous one
- M-right-click to set the end and copy to the next subtitle
- right-click to set the end without changing the next one
- M-j to jump to the current subtitle and play it again in MPV
- M-J to jump to close to the end of the current subtitle and play it in MPV
I use my-subed-delete-oops to delete the oops segments. I can also
just mark them for skipping by calling C-u M-x my-subed-delete-oops
instead.
Then I add a #+OUTPUT: filename-cleaned.opus comment under a NOTE
near the beginning of the file. This tells
subed-record~compile-audio where to put the output.
WEBVTT NOTE #+SKIP 00:00:00.000 --> 00:00:10.319 Finding enough. Oops. NOTE #+OUTPUT: 2023-12-subed-record-cleaned.opus 00:00:10.320 --> 00:00:36.319 Finding enough quiet Focused. Time to record. Audio is a challenge. I often have to re-record segments in order to correct brain hiccups, or to restart after interruptions.
I can test short segments by marking the region with C-SPC and using
subed-record-compile-try-flow. This lets me check if the transitions
between segments make sense.
When I'm happy with everything, I can use subed-record-compile-audio
to extract the segments specified by the start and end times of each
subtitle and concatenate them one after the other in the audio file
specified by the output. The result should be a clean audio file.
If I need to compile an audio file from several takes, I process each
take separately. Once I've adjusted the timestamps and deleted or
skipped the oops segments, I add #+AUDIO: input-filename.opus to a
NOTE at the beginning of the file.
subed-record-insert-audio-source-note makes this easier. Then I copy
the file's subtitles into my main file. subed-record-compile-audio will take
the audio from whichever file was specified by the #+AUDIO: comment,
so I can use audio from different files.
Example VTT segment with multiple audio files
NOTE #+AUDIO: 2023-11-11-emacsconf.m4a 00:10:55.617 --> 00:10:58.136 Sometimes we send emails one at a time. NOTE #+AUDIO: 2023-11-15-emacsconf.m4a 00:10:55.625 --> 00:11:03.539 Like when you let a speaker know that we've received a proposal That's mostly a matter of plugging the talks properties into the right places in the template.
Now I have a clean audio file that corresponds to my script. I can use
subed-align on my script to get the timestamps for each line using
the cleaned audio. Once I have a subtitle file, I can use
emacsconf-subed-split (in emacsconf-subed.el - which I
probably should add to subed-mode sometime) to quickly split the
captions up to fit the line lengths. Then I redo the timestamps with
subed-align and adjust timestamps with
subed-waveform-show-current.
So that's how I go from rough recordings with stutters and oopses to a clean audio file with captions based on my script. People can probably edit faster with Audacity wizardry or the AI audio editors that are in vogue these days, but this little workflow gets around my impatience with audio by turning it into (mostly) text, so that's cool. Let's see if I can make more presentations now that I've gotten the audio side figured out!
Links:
- https://github.com/sachac/subed
- https://github.com/sachac/subed-record
- https://github.com/sachac/compile-media (which subed-record uses to make ffmpeg commands)
- https://readbeyond.it/aeneas - forced alignment tool