I wanted to use Mermaid to make diagrams, but I ran into this issue when trying to run it:
Error: Could not find Chromium (rev. 1108766). This can occur if either
1. you did not perform an installation before running the script (e.g. `npm install`) or
2. your cache path is incorrectly configured (which is: /home/sacha/.cache/puppeteer).
For (2), check out our guide on configuring puppeteer at https://pptr.dev/guides/configuration.
It turns out that I needed to do the following:
sudo npm install -g puppeteer mermaid @mermaid-js/mermaid-cli --unsafe-perm
# Cache Chromium for my own user
node /usr/lib/node_modules/puppeteer/install.js --unsafe-perm
sudo npm install -g mermaid @mermaid-js/mermaid-cli
ln -s ~/.cache/puppeteer/chrome/linux-117.0.5938.149 ~/.cache/puppeteer/chrome/linux-1108766
ln -s ~/.cache/puppeteer/chrome/linux-117.0.5938.149/chrome-linux64 ~/.cache/puppeteer/chrome/linux-117.0.5938.149/chrome-linux
(The exact versions might be different for your installation.)
Then I could make a Mermaid file and try it out with mmdc -i input.mmd -o output.svg,
and then I could confirm that it works directly from Org with ob-mermaid:
[2023-01-04 Wed] Added a screenshot showing annotation.
I was thinking about how to prepare for my next 10-year review, since
I'll turn 40 this year. I've been writing yearly reviews with some
regularity and monthly reviews sporadically, and I figured it would be
nice to have those posts in an EPUB so that I can read them on my
e-reader and annotate them as I do my review.
I use the 11ty static site generator to publish my blog as HTML files,
since I currently can't keep more than Emacs Lisp, Javascript, and
Python in my brain. (No Hugo or Jekyll for me at the moment.) I
briefly thought about getting 11ty to create that archive for me, but
I realized it might be easier to just write it as an external script
instead of trying to figure out how to get 11ty to export one thing
conditionally.
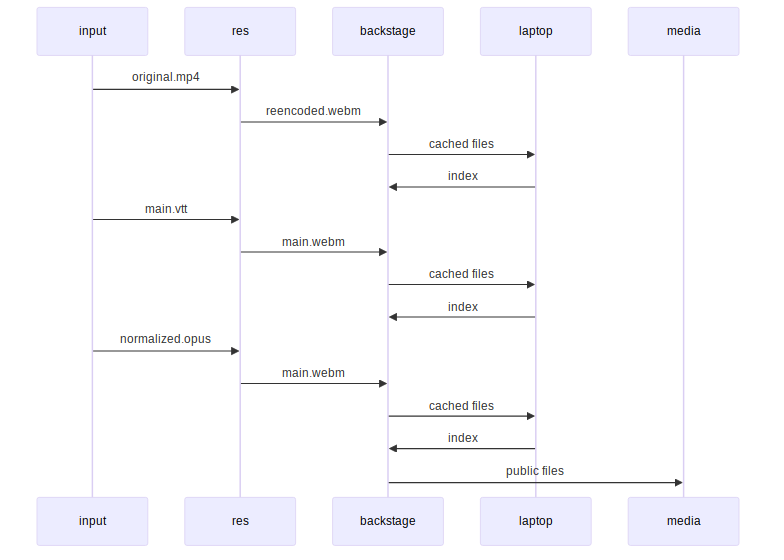
One of the things I've configured 11ty to make is a JSON file that
includes all of my posts with dates, titles, permalinks, and categories. It
was easy to then parse this list and filter it to get the posts I
wanted. I parsed the HTML out of the _site directory that 11ty
produces instead of fetching the pages from my webserver. I got the
images from my webserver, though, and I made a local cache and rewrote
the URLs. That way, the EPUB conversion could include the images.
This created an archive.html with my posts, using the images/
directory for the images. Then I used my shell script for converting
and copying files to convert it to EPUB and copy it over.
On the SuperNote, I can highlight text by drawing square brackets
around it. If I tap that text, I can write or draw underneath it.
Here's what that looks like:
Figure 1: Writing an annotation
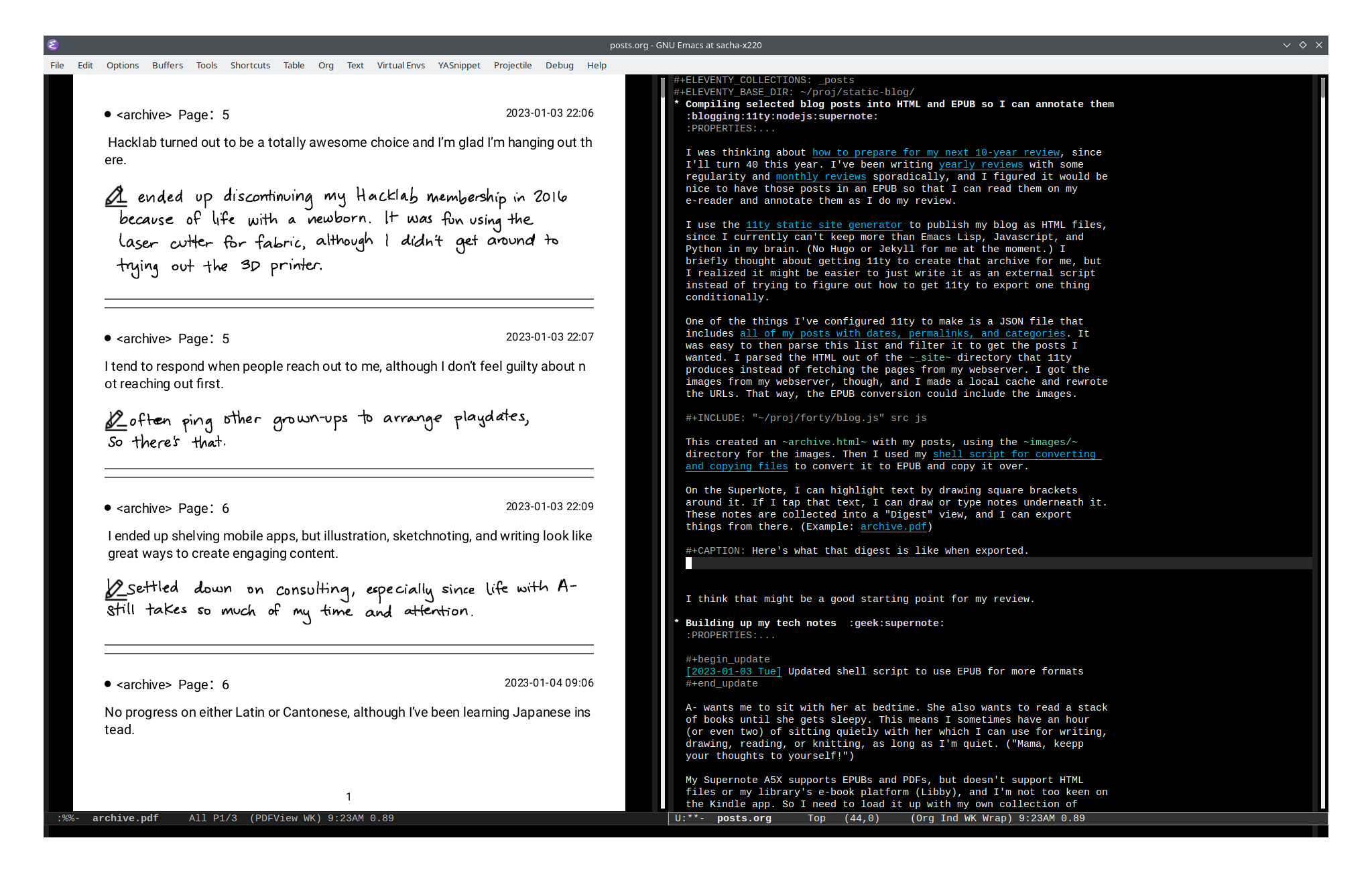
These notes are collected into a "Digest" view, and I can export
things from there. (Example: archive.pdf)
Figure 2: Here's what that digest is like when exported.
(Hmm, maybe I should ask them about hiding the pencil icon…)
Anyway, I think that might be a good starting point for my review.

{kind=link}