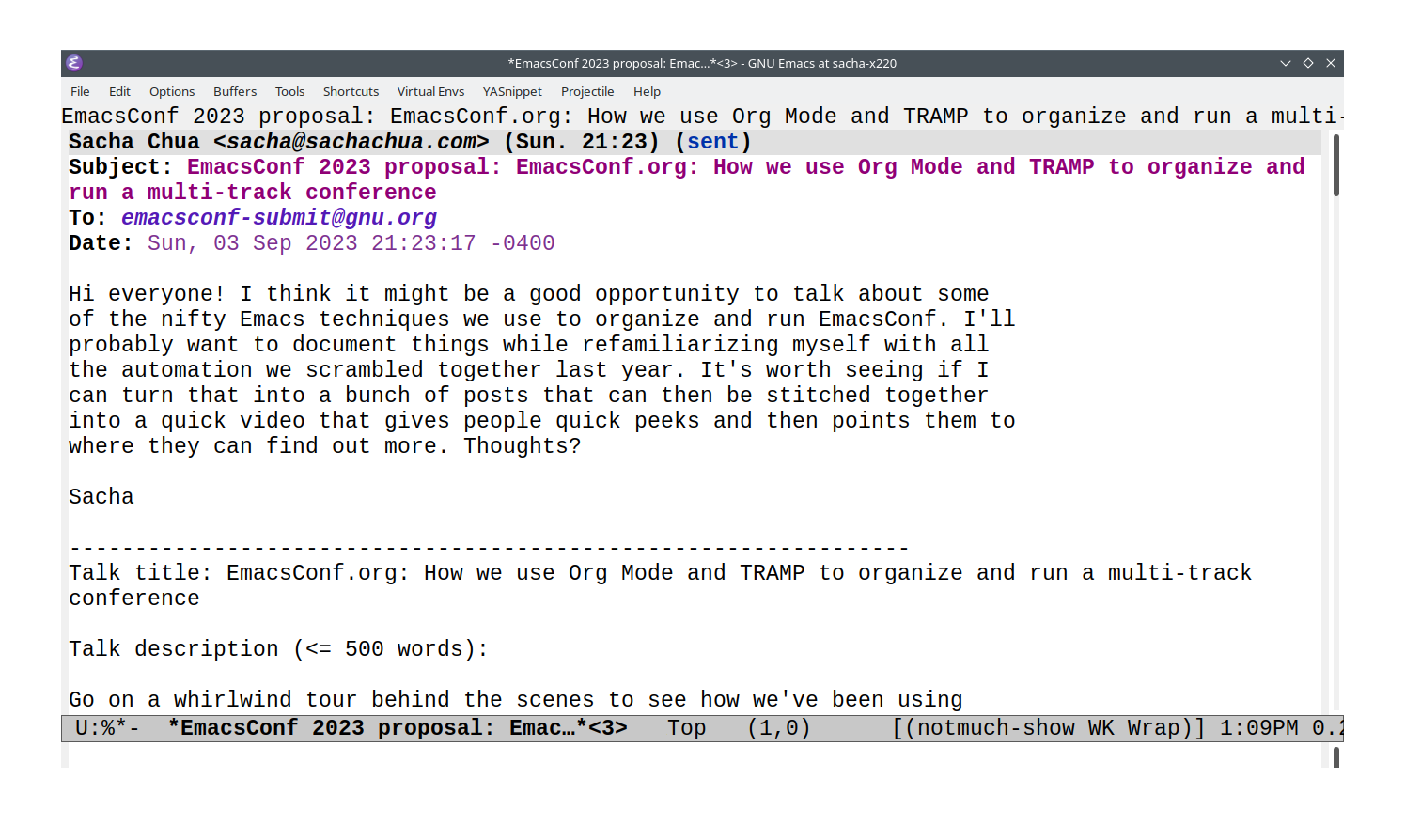
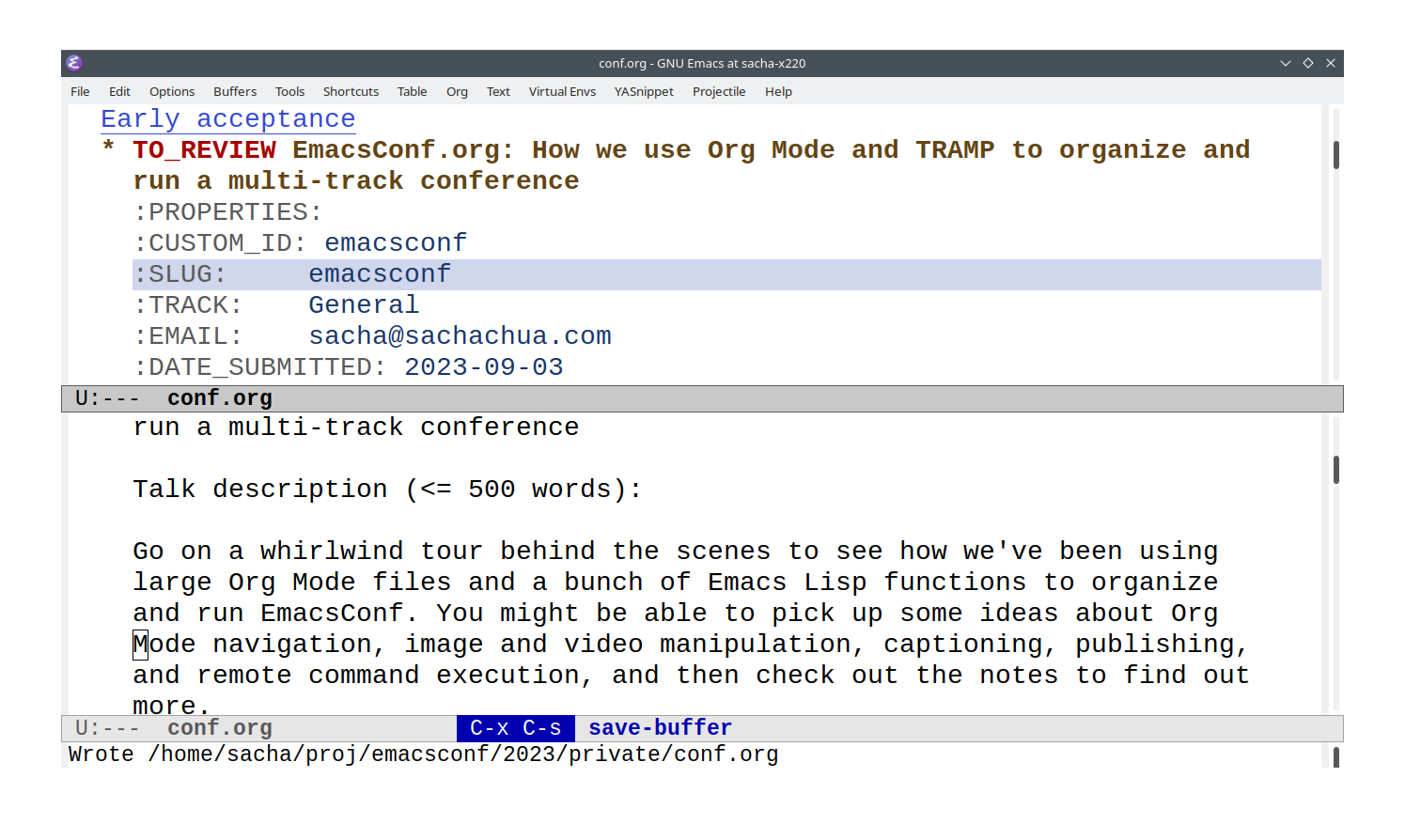
EmacsConf backstage: converting timezones
| emacsconf, emacs- : Update screenshots to use the overlay talk
- : Updated translation schedule to use
emacsconf-mail-format-talk-schedule. - 2023-09-07: It looks like I can use Etc/GMT-2 to mean GMT+2 - note the reversed sign.
EmacsConf is a virtual conference with speakers from all over the world. We like to plan the schedule so that the speakers can come for live Q&A sessions without having to wake up too early or stay up too late.
Timezones are tricky for me. Sometimes I mess up timezone names (like the time I misspelled Tbilisi and ended up with UTC conversion) or get the timezone conversion wrong because of daylight savings time, and it's annoying to go to a website to convert the timezones.
Fortunately, the tzc package provides a way to convert times
from one timeone to another in Emacs, and it includes a list of
timezones in tzc-time-zones loaded from /usr/share/zoneinfo.
Here's how I use it to make organizing EmacsConf easier.
Setting the timeone with completion
To reduce data entry errors, I use completion when setting the timezone.
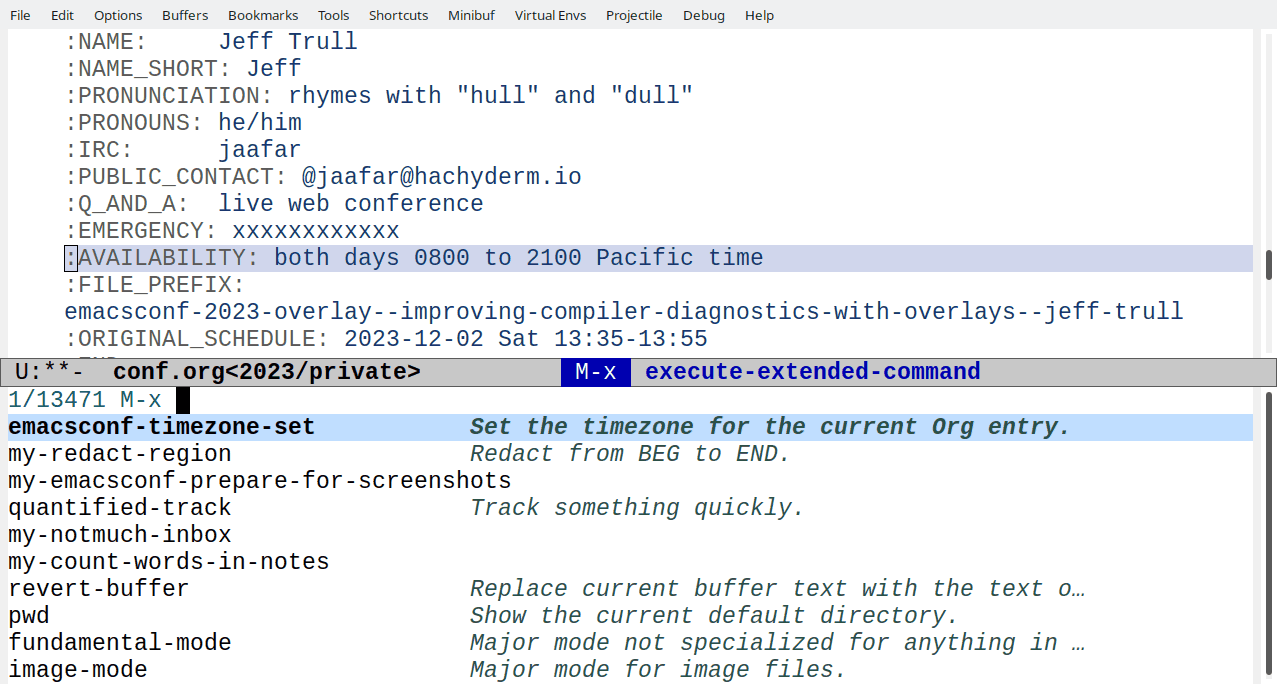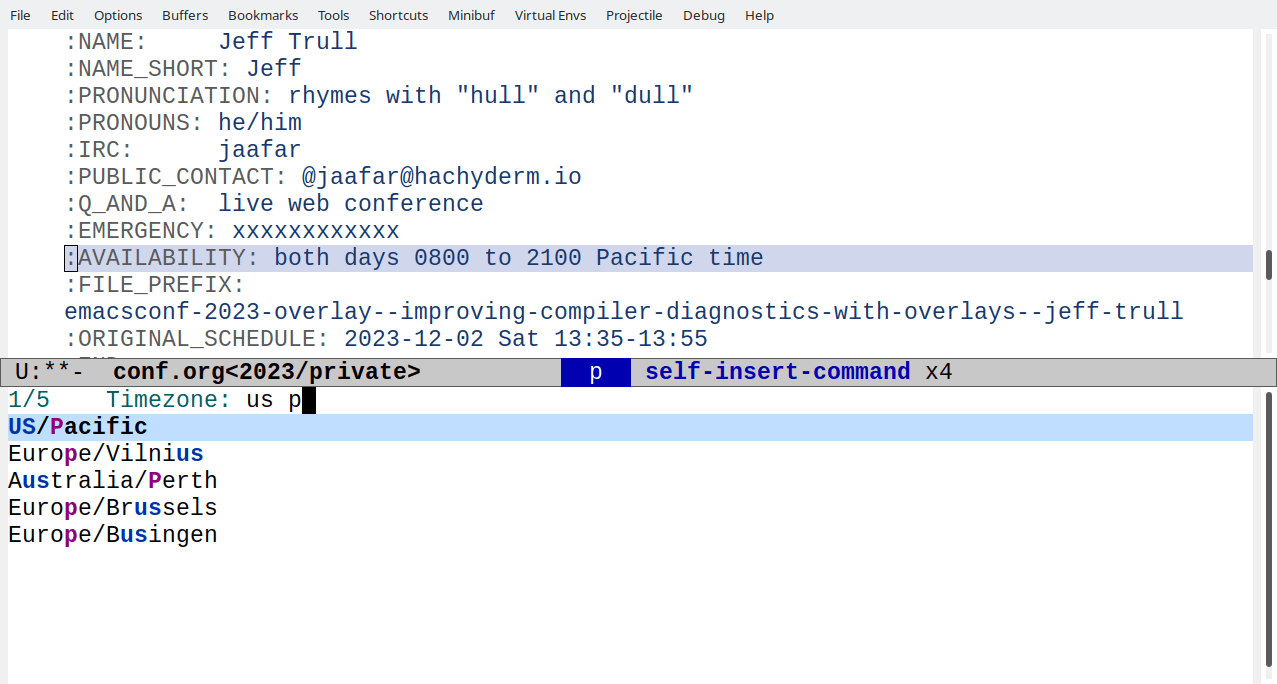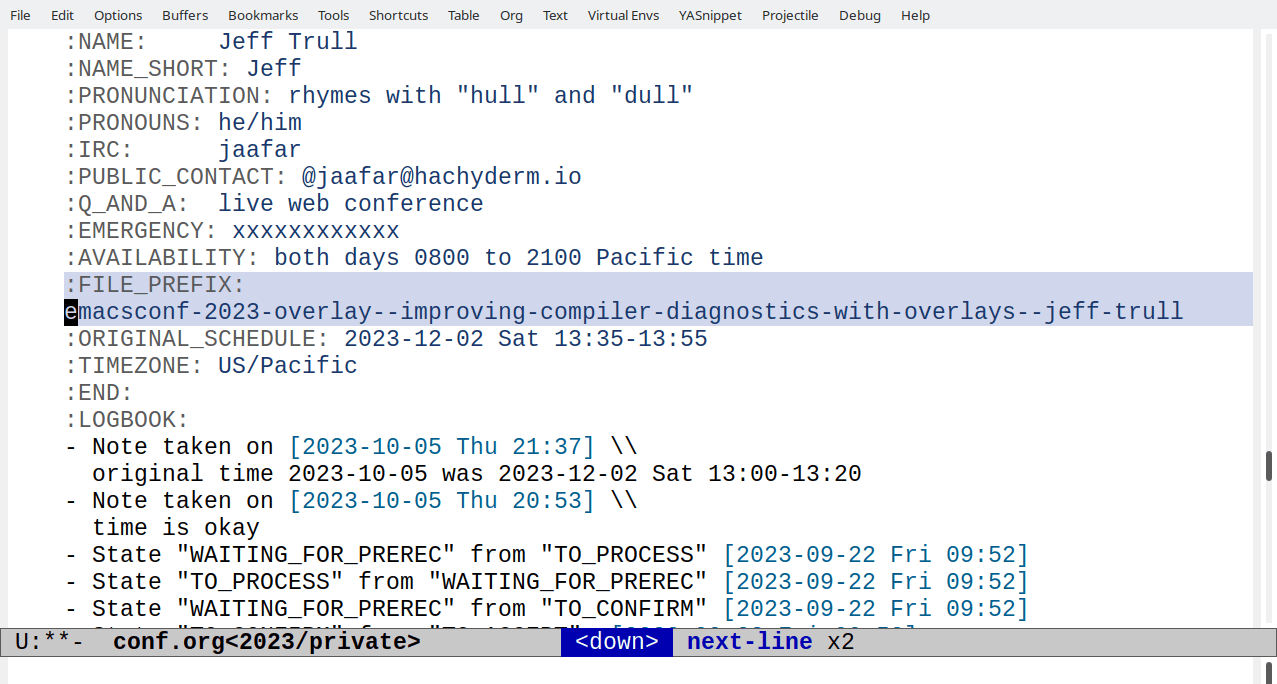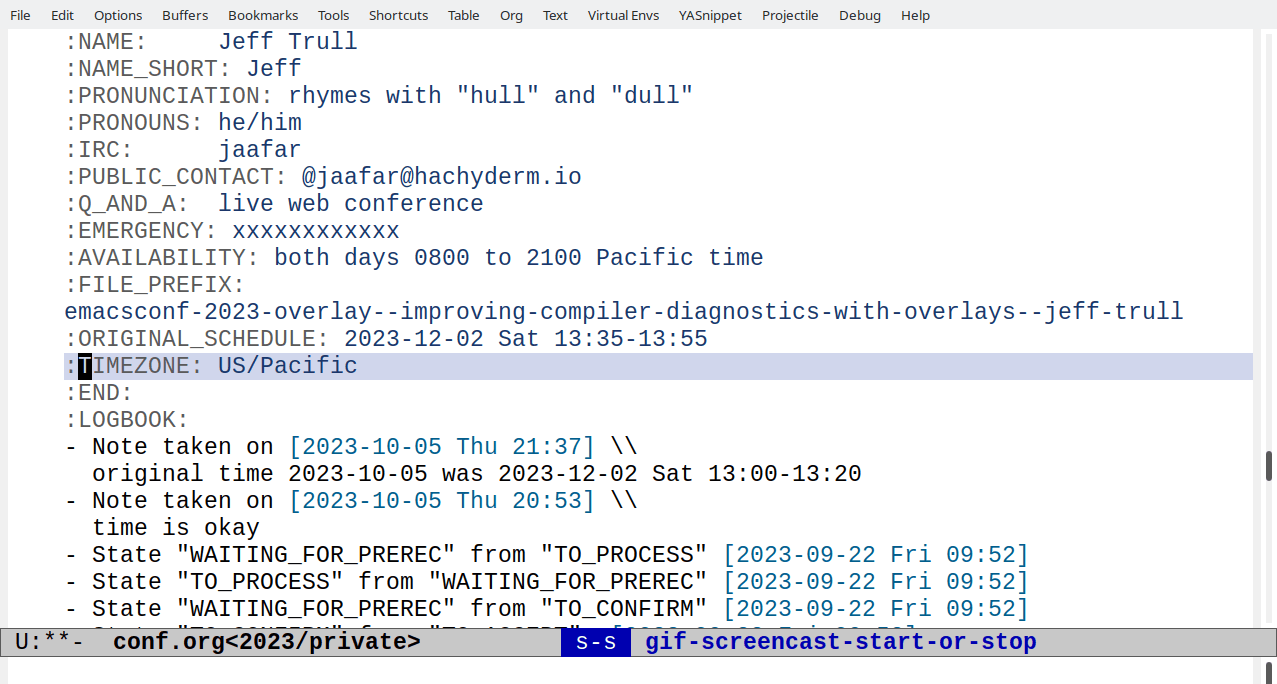
emacsconf-timezone-set: Set the timezone for the current Org entry.
(defun emacsconf-timezone-set (timezone) "Set the timezone for the current Org entry." (interactive (list (progn (require 'tzc) (completing-read "Timezone: " tzc-time-zones)))) (org-entry-put (point) "TIMEZONE" timezone))
Sometimes speakers specify their timezone as an offset from GMT or
UTC, such as GMT+2. It turns out that I can use timezones like
Etc/GMT-2 to capture that, although it's important to note that the sign for Etc/GMT timezones is reversed (so Etc/GMT-2 = GMT+2).
Converting timezones
In Toronto, we switch from daylight savings time to standard time
sometime in November, so I need to make sure that my time conversions
for speaker availability uses the date of the conference
(emacsconf-date, 2023-12-02 this year).
emacsconf-convert-from-timezone makes it easy to convert times on
emacsconf-date so that I don't have to keep re-entering the date
part.
emacsconf-convert-from-timezone
(defun emacsconf-convert-from-timezone (timezone time) (interactive (list (progn (require 'tzc) (if (and (derived-mode-p 'org-mode) (org-entry-get (point) "TIMEZONE")) (completing-read (format "From zone (%s): " (org-entry-get (point) "TIMEZONE")) tzc-time-zones nil nil nil nil (org-entry-get (point) "TIMEZONE")) (completing-read "From zone: " tzc-time-zones nil t))) (read-string "Time: "))) (let* ((from-offset (format-time-string "%z" (date-to-time emacsconf-date) timezone)) (time (date-to-time (concat emacsconf-date "T" (string-pad time 5 ?0 t) ":00.000" from-offset)))) (message "%s = %s" (format-time-string "%b %d %H:%M %z" time timezone) (format-time-string "%b %d %H:%M %z" time emacsconf-timezone))))
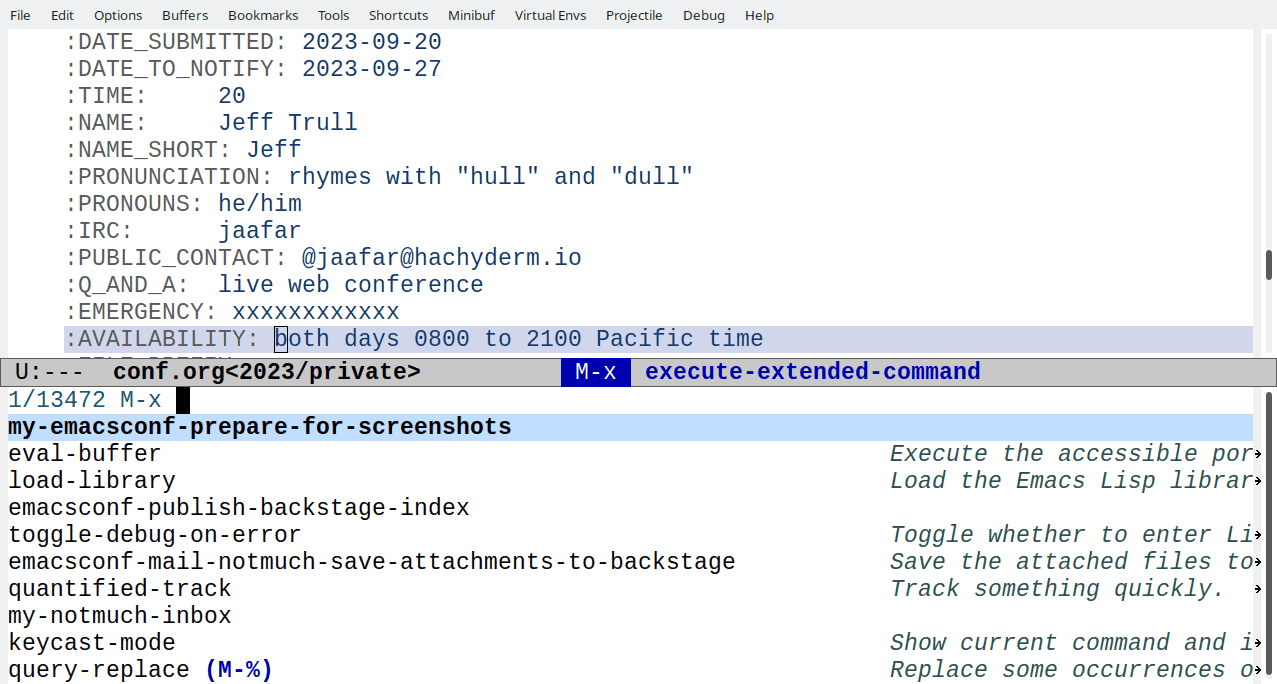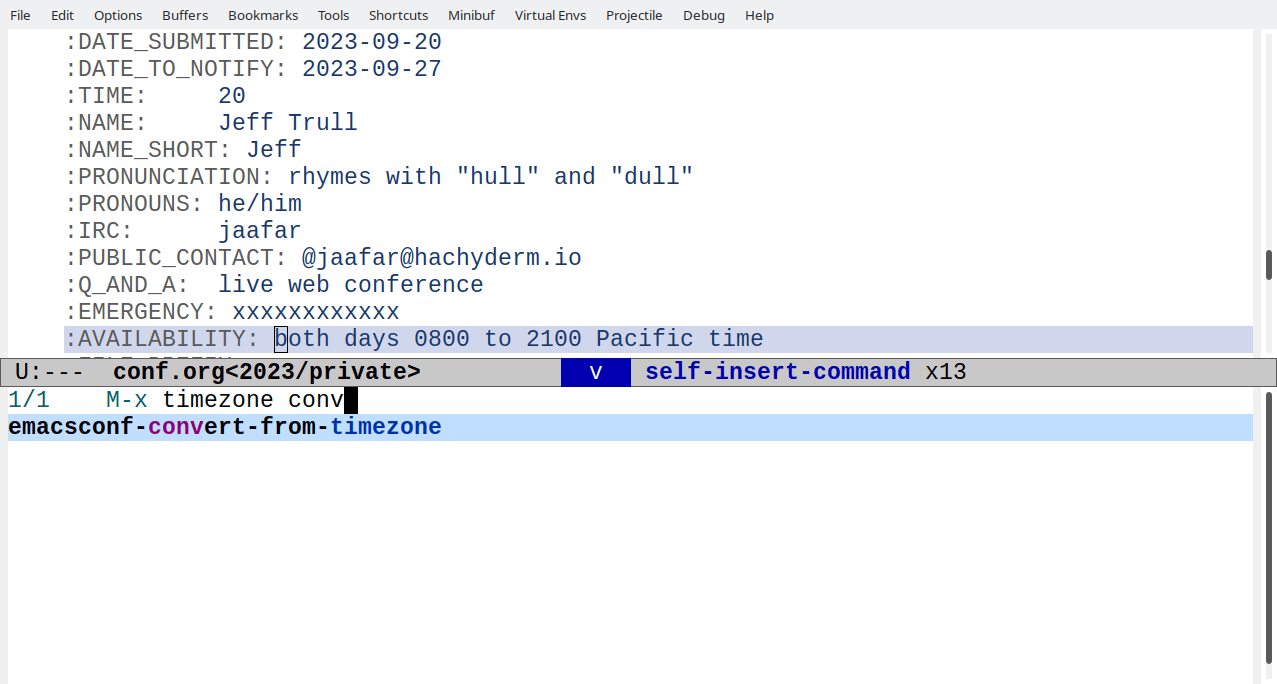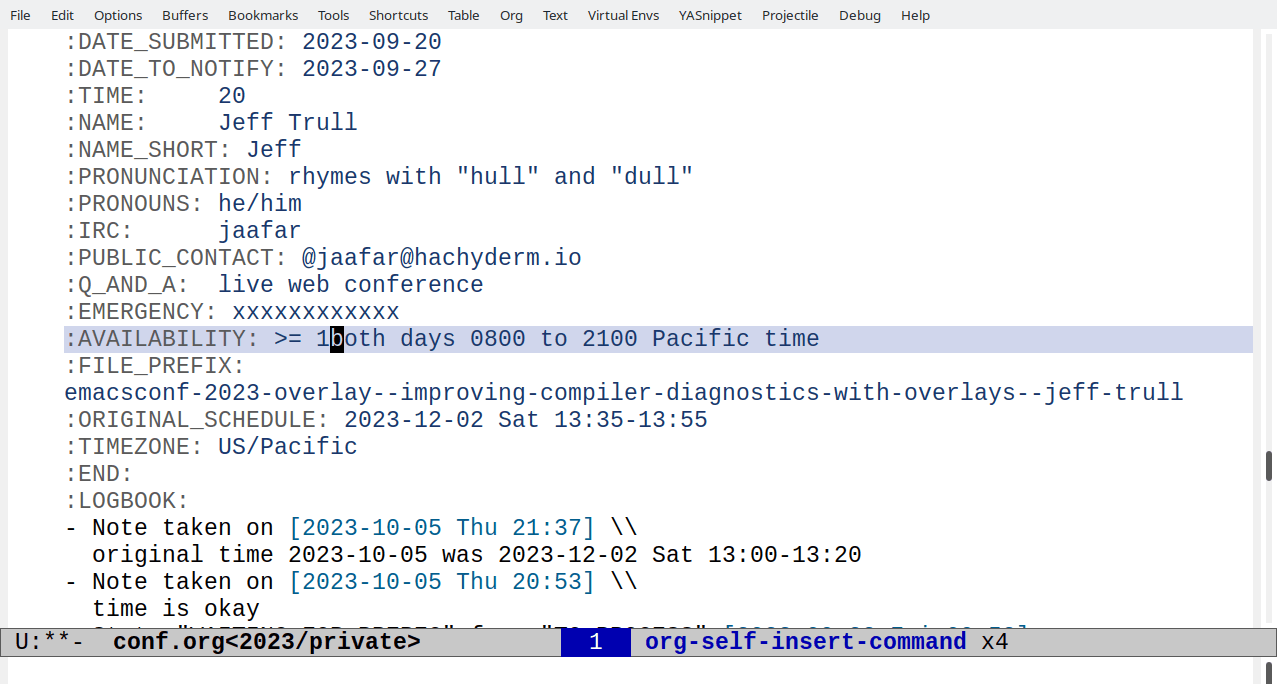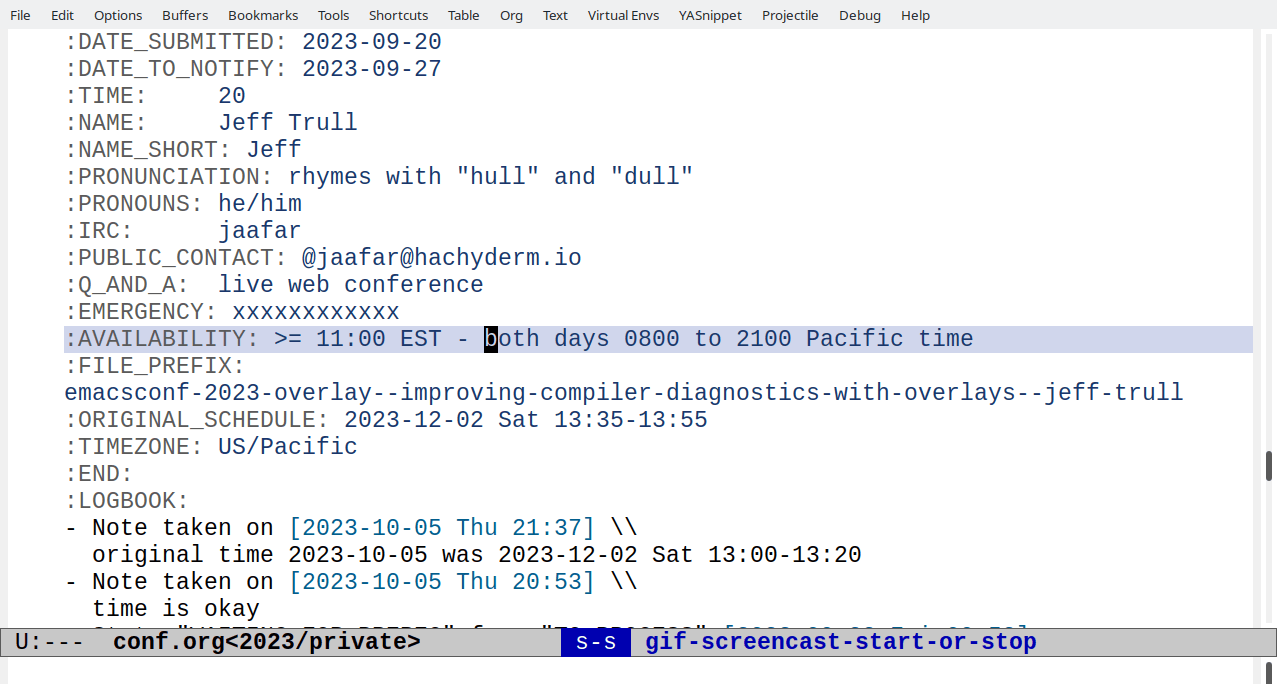
I can use this to convert times like 8:00 in US/Pacific to 11:00 EST.
Validating schedule constraints
Once I get the availability into a standard format, I can use that to
validate that sessions are scheduled during the times that speakers
have indicated that they're available. So far, I've been using text
like >= 10:00 EST at the beginning of the talk's AVAILABILITY
property, since that's easy to parse and validate. I can use that to
colour invalid talks red in an SVG, and I can make a list of invalid
talks as well.
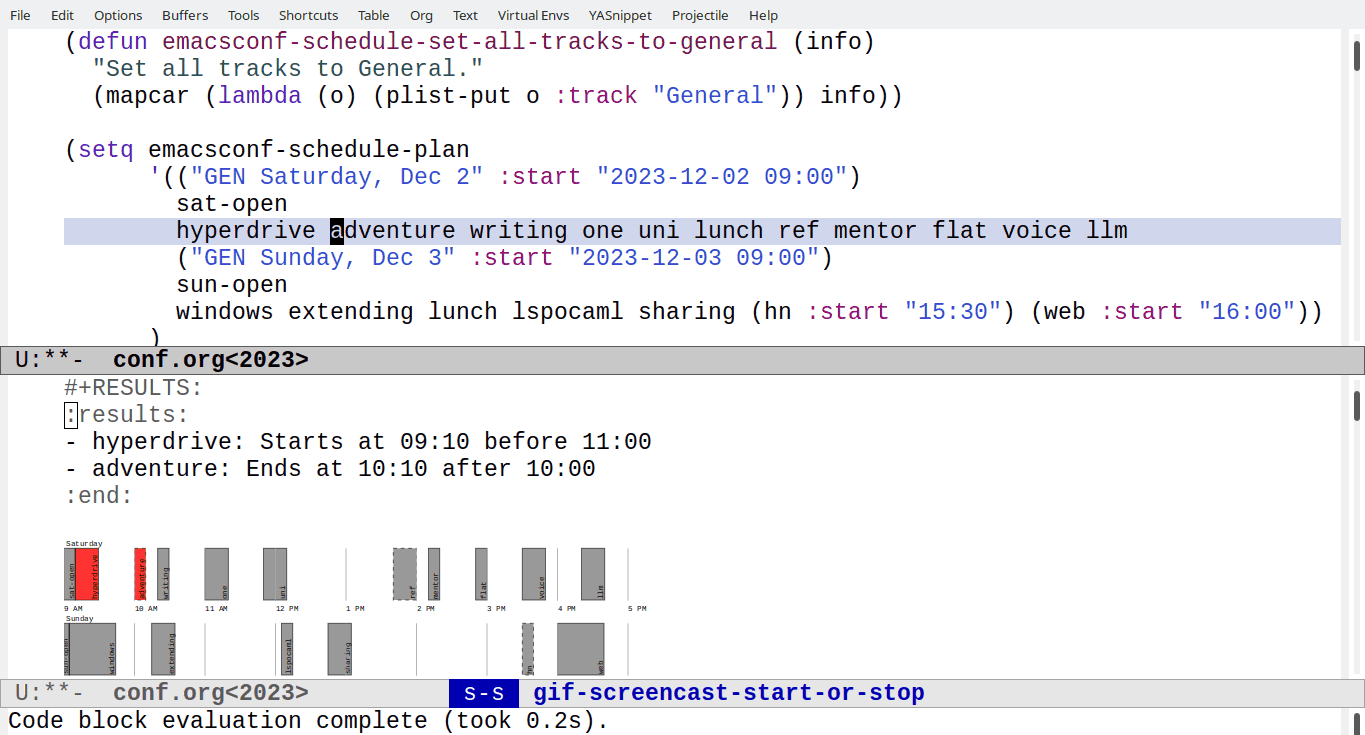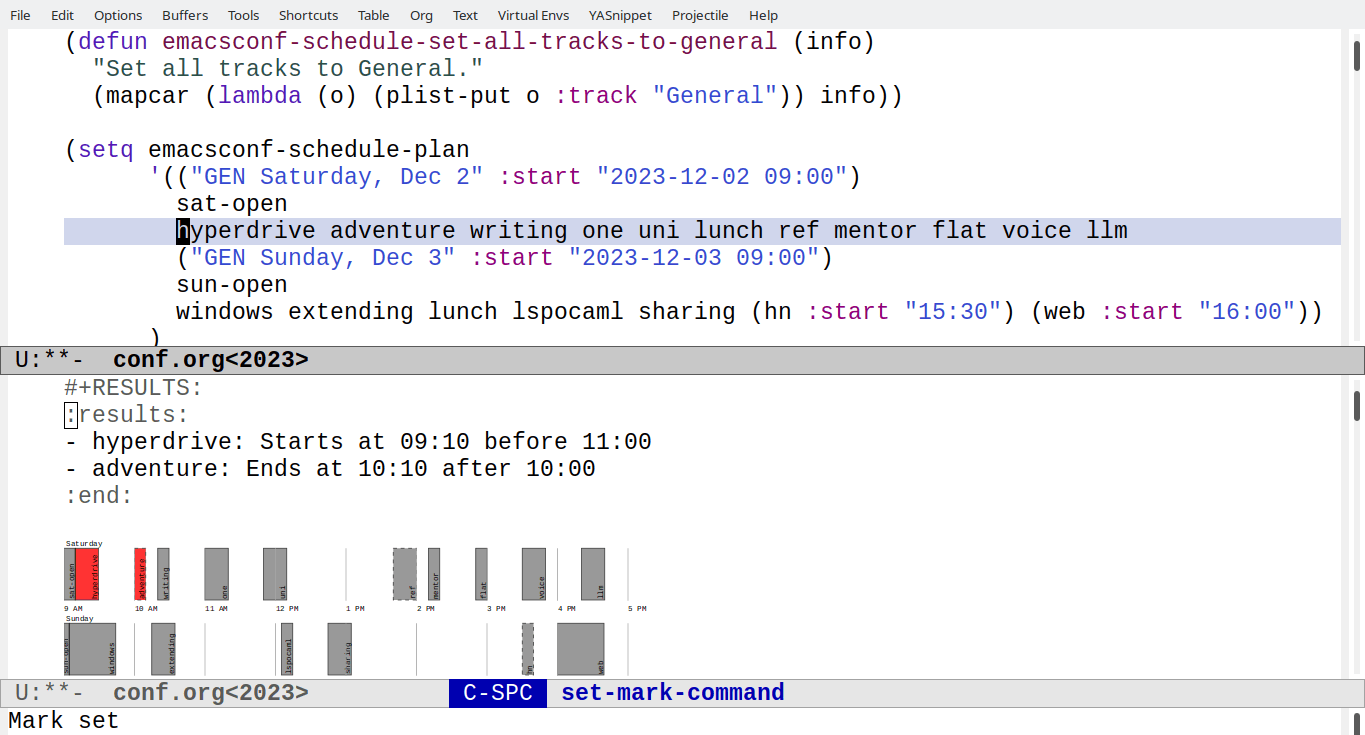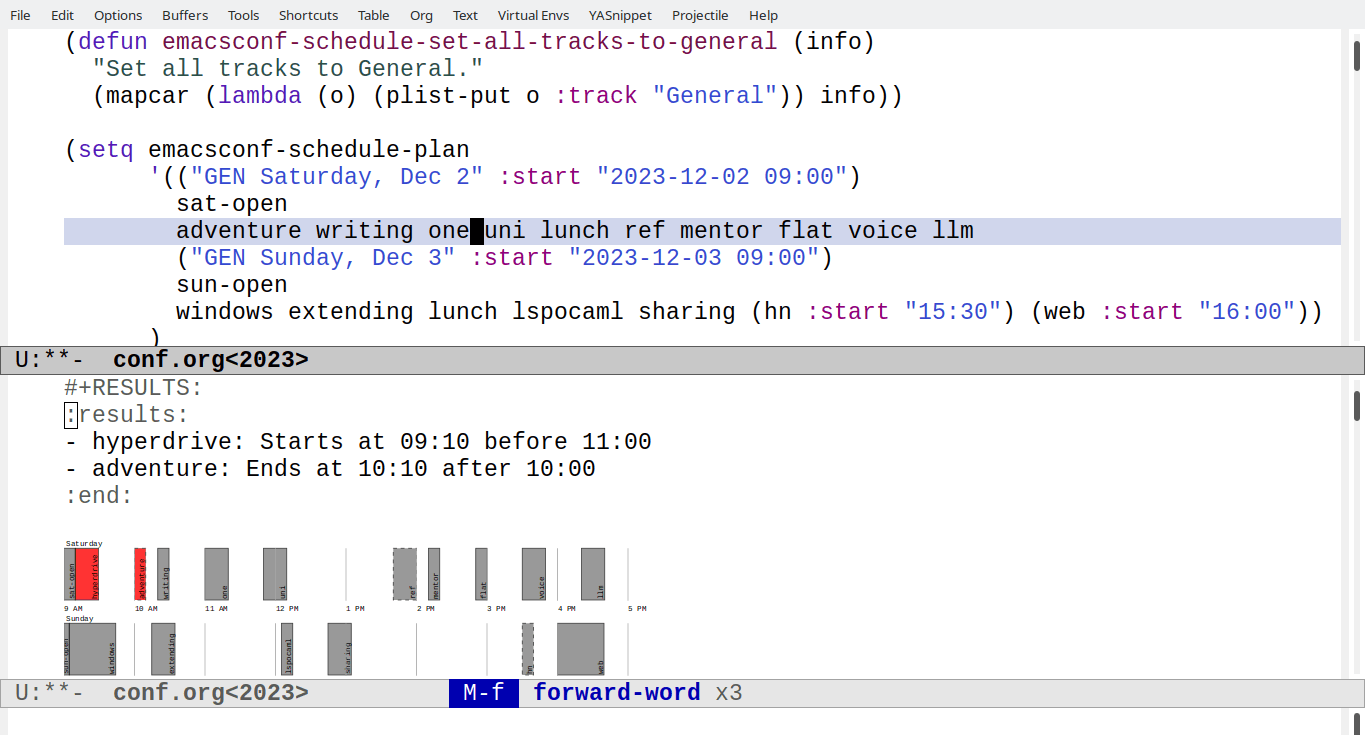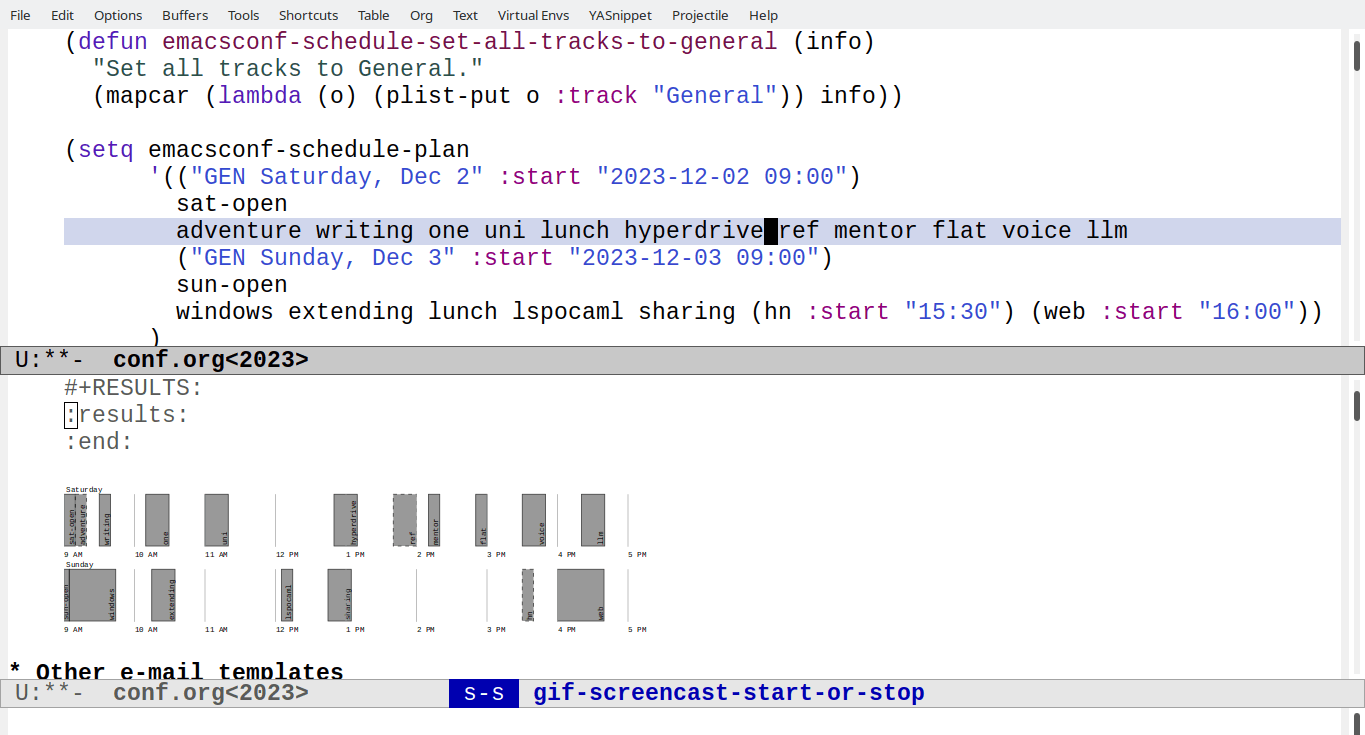
How does that work? First, we get the time constraint out of the
AVAILABILITY property with emacsconf-schedule-get-time-constraint.
emacsconf-schedule-get-time-constraint
(defun emacsconf-schedule-get-time-constraint (o) (when (emacsconf-schedule-q-and-a-p o) (let ((avail (or (plist-get o :availability) "")) hours start (pos 0) (result (list nil nil nil))) (while (string-match "\\([<>]\\)=? *\\([0-9]+:[0-9]+\\) *EST" avail pos) (setf (elt result (if (string= (match-string 1 avail) ">") 0 1)) (match-string 2 avail)) (setq pos (match-end 0))) (when (string-match "[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]" avail) (setf (elt result 2) (match-string 0 avail))) result)))
Then we can return a warning if a talk is scheduled outside those time constraints.
emacsconf-schedule-check-time: FROM-TIME and TO-TIME should be nil strings like HH:MM in EST.
(defun emacsconf-schedule-check-time (label o &optional from-time to-time day) "FROM-TIME and TO-TIME should be nil strings like HH:MM in EST. DAY should be YYYY-MM-DD if specified. Both start and end time are tested." (let* ((start-time (format-time-string "%H:%M" (plist-get o :start-time))) (end-time (format-time-string "%H:%M" (plist-get o :end-time))) result) (setq result (or (and (null o) (format "%s: Not found" label)) (and from-time (string< start-time from-time) (format "%s: Starts at %s before %s" label start-time from-time)) (and to-time (string< to-time end-time) (format "%s: Ends at %s after %s" label end-time to-time)) (and day (not (string= (format-time-string "%Y-%m-%d" (plist-get o :start-time)) day)) (format "%s: On %s instead of %s" label (format-time-string "%Y-%m-%d" (plist-get o :start-time)) day)))) (when result (plist-put o :invalid result)) result))
So then we can check all the talks as scheduled, and set the
:invalid property if it's outside the availability constraints.
emacsconf-schedule-validate-time-constraints
(defun emacsconf-schedule-validate-time-constraints (info &rest _) (interactive) (let* ((info (or info (emacsconf-get-talk-info))) (results (delq nil (append (mapcar (lambda (o) (apply #'emacsconf-schedule-check-time (car o) (emacsconf-search-talk-info (car o) info) (cdr o))) emacsconf-time-constraints) (mapcar (lambda (o) (let (result (constraint (emacsconf-schedule-get-time-constraint o))) (when constraint (setq result (apply #'emacsconf-schedule-check-time (plist-get o :slug) o constraint)) (when result (plist-put o :invalid result)) result))) info))))) (if (called-interactively-p 'any) (message "%s" (string-join results "\n")) results)))
Here are more details on how I made the schedule SVG. It's handy to have a quick way to check availability in both text and graphical format.
Translating schedules into local times
When we e-mail speakers their schedules, we also include a translation to their local time if we know it.

That's handled by the emacsconf-mail-format-talk-schedule, which
handles three cases:
- timezone is the same as the conference: show just that time
- UTC offset is the same as the conferenc, just a different timezone: mention that
- UTC offset is different: translate to local time and make it clear that this is a translation, not a second event
(If we haven't noted the timezone for the talk, we ask the speaker.)
emacsconf-mail-format-talk-schedule: Format the schedule for O for inclusion in mail messages etc.
(defun emacsconf-mail-format-talk-schedule (o) "Format the schedule for O for inclusion in mail messages etc." (interactive (list (emacsconf-complete-talk))) (when (stringp o) (setq o (emacsconf-resolve-talk (emacsconf-get-slug-from-string o) (or emacsconf-schedule-draft (emacsconf-get-talk-info))))) (let ((result (concat (plist-get o :title) "\n" (format-time-string "%b %-e %a %-I:%M %#p %Z" (plist-get o :start-time) emacsconf-timezone) "\n" (if (and (plist-get o :timezone) (not (string= (plist-get o :timezone) emacsconf-timezone))) (if (string= (format-time-string "%z" (plist-get o :start-time) (plist-get o :timezone)) (format-time-string "%z" (plist-get o :start-time) emacsconf-timezone)) (format "which is the same time in your local timezone %s\n" (emacsconf-schedule-rename-etc-timezone (plist-get o :timezone))) (format "translated to your local timezone %s: %s\n" (emacsconf-schedule-rename-etc-timezone (plist-get o :timezone)) (format-time-string "%b %-e %a %-I:%M %#p %Z" (plist-get o :start-time) (plist-get o :timezone)))) "")))) (when (called-interactively-p 'any) (insert result)) result))
The Etc/GMT... timezones are a little confusing, because the signs
are opposite from what you'd expect (GMT-3 = UTC+0300). So we have a
little function that turns those into regular UTC offsets.
emacsconf-schedule-rename-etc-timezone: Change Etc/GMT-3 etc. to UTC+3 etc., since Etc uses negative signs and this is confusing.
(defun emacsconf-schedule-rename-etc-timezone (s) "Change Etc/GMT-3 etc. to UTC+3 etc., since Etc uses negative signs and this is confusing." (cond ((string-match "Etc/GMT-\\(.*\\)" s) (concat "UTC+" (match-string 1 s))) ((string-match "Etc/GMT\\+\\(.*\\)" s) (concat "UTC-" (match-string 1 s))) (t s)))
So that's how we work with timezones in EmacsConf!