Pedro pointed out that I had some incomplete clock
entries in my Emacs configuration.
org-resolve-clocks prompts you for what to do
with each open clock entry in your Org agenda
files and whatever Org Mode files you have open.
If you don't feel like cancelling each clock with
C, I also wrote this function to delete all open
clocks in the current file.
Sometimes I want to get the URL from a string
whether the string contains a bare URL
(https://example.com) or an Org bracketed link
([[https://example.com]] or
[[https://example.com][Example]], ignoring any
extra non-link text (blah https://example.com
blah blah). org-link-any-re seemed like the
right regular expression to use, but I started to
get a little dizzy looking at all the parenthesis
and I couldn't figure out which matching group to
use. I tried using re-builder. That highlighted
the groups in different colours, but I didn't know
what the colours meant. All the matching
information is in (match-data), but integer pairs
can be a little hard to translate back to
substrings. So I wrote an Emacs Lisp function to
gave me the matching groups:
(defunmy-match-groups (&optional object)
"Return the matching groups, good for debugging regexps."
(seq-map-indexed (lambda (entry i)
(list i entry
(and (car entry)
(if object
(substring object (car entry) (cadr entry))
(buffer-substring (car entry) (cadr entry))))))
(seq-partition
(match-data t)
2)))
There's probably a standard way to do this, but I
couldn't figure out how to find it.
Anyway, if I give it a string with a bracketed
link, I can tell that the URL ends up in group 2:
This makes it so much easier to refer to the right
capture group. So now I can use those groups to
extract the URL from a string:
(defunmy-org-link-url-from-string (s)
"Return the link URL from S."
(when (string-match org-link-any-re s)
(or
(match-string 7 s)
(match-string 2 s))))
This is handy when I summarize Emacs News links
from Mastodon or from my inbox. Sometimes I add
extra text after a link that I've captured from my
phone, and I don't want that included in the URL.
Sometimes I have a bracketed link that I've copied
from org-capture note. Now I don't have to worry
about the format. I can just grab the link I want.
I write my blog posts in Org Mode and export them
to Eleventy with ox-11ty, which is derived from
the ox-html backend.
Sometimes I want to link to something in a
different blog post. This lets me build on
thoughts that are part of a post instead of being
a whole post on their own.
If I haven't added an anchor to the blog post yet,
I can add one so that I can link to that section.
For really old posts where I don't have an Org
source file, I can edit the HTML file directly and
add an id="some-id" so that I can link to it
with /url/to/post#some-id. Most of my new posts
have Org source, though. I have a
my-blog-edit-org function and a
my-blog-edit-html function in my Emacs
configuration to make it easier to jump to the Org
file or HTML for a blog post.
If the section has a heading, then it's easy to
make that linkable with a custom name. I can use
org-set-property to set the CUSTOM_ID property
to the anchor name. For example, this voice access
section has a heading that has CUSTOM_ID, as you
can see in the . If I don't mind having
long anchor names, I can use the
my-assign-custom-ids function from my config to
automatically set them based on the outline path.
#+ATTR_HTML: :id interest-development
That reminds me a little of another reflection
I've been noodling around on interest development...
Anchor links
It might be fun to have a little margin note with
🔗 to indicate that that's a specially-linkable
section, which could be handy when I want to link
when mobile. It feels like that would be a left
margin thing on a large screen, so it'll just have
to squeeze in there with the sticky table of
contents. I've been meaning to add link icons to
sub-headings with IDs, anyway, so I can probably solve
both with a bit of Javascript.
Text fragments are even more powerful, because I
can link to a specific part of a paragraph. I can
link to one segment with something like
#::text=text+to+highlight~. I can specify
multiple text fragments to highlight by using
#::text=first+text+to+highlight&text=second+text~,
and the browser will automatically scroll to the
first highlighted section. I can specify a longer
section by using text=textStart,textEnd. Example:
#:~:text=That%20is%20the%20gap,described The text
fragments documentation has more options,
including using prefixes and suffixes to
disambiguate matches.
[2025-01-12 Sun]: u/dr-timeous posted a treemap_org.py · GitHub that makes a coloured treemap that displays the body on hover. (Reddit) Also, I think librsvg doesn't support wrapped text, so that might mean manually wrapping if I want to figure out the kind of text density that webtreemap has.
One of the challenges with digital notes is that
it's hard to get a sense of volume, of mass, of
accumulation. Especially with Org Mode, everything
gets folded away so neatly and I can jump around
so readily with C-c j (org-goto) or C-u C-c
C-w (org-refile) that I often don't stumble
across the sorts of things I might encounter in a
physical notebook.
Treemaps are a quick way to visualize hierarchical
data using nested rectangles or squares, giving a
sense of relative sizes. I was curious about what
my main organizer.org file would look like as a
treemap, so I wrote some code to transform it into
the kind of data that
https://github.com/danvk/webtreemap wants as
input. webtreemap creates an HTML file that uses
Javascript to let me click on nodes to navigate
within them.
For this treemap prototype, I used
org-map-entries to go over all the headings and
make a report with the outline path and the size
of the heading. To keep the tree visualization
manageable, I excluded done/cancelled tasks and
archived headings. I also wanted to exclude some
headings from the visualization, like the way my
Parenting subheading has lots of personal
information underneath it. I added a :notree:
tag to indicate that a tree should not be
included.
Screencast of exploring a treemap
Reflections
Figure 1: Screenshot of the treemap for my organizer.org
The video and the screenshot above show the
treemap for my main Org Mode file,
organizer.org. I feel like the treemap makes it
easier to see projects and clusters where I'd
accumulated notes, both in terms of length and
quantity. (I've omitted some trees like
"Parenting" which take up a fairly large chunk of
space.)
To no one's surprise, Emacs takes up a large part
of my notes and ideas. =)
When I look at this treemap, I notice a bunch of
nodes I need to mark as DONE or CANCELLED
because I forgot to update my organizer.org. That
usually happens when I come up with an idea, don't
remember that I'd come up with it before, put it
in my inbox.org file, and do it from there or from
the organizer.org location I've refiled it to
without bumping into the first idea. Once in a
blue moon, I go through my whole organizer.org
file and clean out the cruft. Maybe a treemap like
this will make it easier to quickly scan things.
Interestingly, "Explore AI" takes up a
disproportionately large chunk of my "Inactive
Projects" visualization, even though I spend more
time and attention on other things. Large language
models make it easy to generate a lot of text, but
I haven't really done the work to process those.
I've also collected a lot of links that I haven't
done much with.
It might be neat to filter the headings by
timestamp so that I can see things I've touched in
the last 6 months.
Hmm, looking at this treemap reminds me that I've
got "organizer.org/Areas/Ideas for things to do
with focused time/Writing/", which probably should
get moved to the posts.org file that I tend to
use for drafts. Let's take look at the treemap for
that file. (Updated: cleared it out!)
Figure 2: Drafts in my posts.org
Unlike my organizer.org file, my posts.org
file tends to be fairly flat in terms of
hierarchy. It's just a staging ground for ideas
before I put them on my blog. I usually try to
keep posts short, but a few of my posts have
sub-headings. Since the treemap makes it easy to
see nodes that are larger or more complex, that
could be a good nudge to focus on getting those
out the door. Looking at this treemap reminds me
that I've got a bunch of EmacsConf posts that I
want to finish so that I can document more of our
processes and tools.
Figure 3: Treemap of my inbox
My inbox.org is pretty flat too, since it's
really just captured top-level notes that I'll
either mark as done or move somewhere else
(usually organizer.org). Because the treemap
visualization tool uses / as a path separator,
the treemap groups headings that are plain URLs
together, grouped by domain and path.
Figure 4: Treemap of my Emacs configuration
My Emacs configuration is organized as a
hierarchy. I usually embed the explanatory blog
posts in it, which explains the larger nodes. I
like how the treemap makes it easy to see the
major components of my configuration and where I
might have a lot of notes/custom code. For
example, my config has a surprising amount to do
with multimedia considering Emacs is a text
editor, and that's mostly because I like to tinker
with my workflow for sketchnotes and subtitles.
This treemap would be interesting to colour based
on whether something has been described in a blog
post, and it would be great to link the nodes in a
published SVG to the blog post URLs. That way, I
can more easily spot things that might be fun to
write about.
There's another treemap visualization tool that
can produce squarified treemaps as coloured SVGs,
so that style might be interesting to explore too.
Next steps
I think there's some value in being able to look
at and think about my outline headings with a
sense of scale. I can imagine a command that shows
the treemap for the current subtree and allows
people to click on a node to jump to it (or maybe
shift-click to mark something for bulk action), or
one that shows subtrees summing up :EFFORT:
estimates or maybe clock times from the logbook,
or one limited by a timestamp range, or one that
highlights matching entries as you type in a
query, or one that visualizes s-exps or JSON or
project files or test coverage.
It would probably be more helpful if the treemap
were in Emacs itself, so I could quickly jump to
the Org nodes and read more or mark something as
done when I notice it. boxy-headings uses text to
show the spatial relationships of nested headings,
which is neat but probably not up to handling this
kind of information density. Emacs can also
display SVG images in a buffer, animate them, and
handle mouse-clicks, so it could be interesting to
implement a general treemap visualization which
could then be used for all sorts of things like
disk space usage, files in project modules, etc.
SVGs would probably be a better fit for this
because that allows increased text density and
more layout flexibility.
It would be useful to browse the treemap within
Emacs, export it as an SVG so that I can include
it in a webpage or blog post, and add some
Javascript for web-based navigation.
The Emacs community being what it is (which is
awesome!), I wouldn't be surprised if someone's
already figured it out. Since a quick search
for treemap in the package archives and various
places doesn't seem to turn anything up, I thought
I'd share these quick experiments in case they
resonate with other people. I guess I (or someone)
could figure out the squarified treemapping
algorithm or the ordered treemap algorithm in
Emacs Lisp, and then we can see what we can do
with it.
I've also thought about other visualizations that
can help me see my Org files a different way.
Network graphs are pretty popular among the
org-roam crew because org-roam-ui makes them.
Aside from a few process checklists that link to
headings that go into step-by-step detail and
things that are meant to graph connections between
concepts, most of my Org Mode notes don't
intentionally link to other Org Mode notes. (There
are also a bunch of random org-capture context
annotations I haven't bothered removing.) I tend
to link to my public blog posts, sketches, and
source code rather than to other headings, so
that's a layer of indirection that I'd have to
custom-code. Treemaps might be a good start,
though, as they take advantage of the built-in
hierarchy. Hmm…
I put together a pull request to modify
ob-mermaid-cli-path so that it doesn't get quoted
and can therefore have the aa-exec command needed
to work around that. With that modified
org-babel-execute:mermaid, I can then configure
ob-mermaid like this:
(use-package ob-mermaid
:load-path"~/vendor/ob-mermaid")
;; I need to override this so that the executable isn't quoted
(setq ob-mermaid-cli-path "aa-exec --profile chrome mmdc -c ~/.config/mermaid/config.json")
I also ran into a problem where the library that
Emacs uses to display SVGs could not handle the
foreignObject elements used for the labels.
mermaid missing text in svg · Issue #112 ·
mermaid-js/mermaid-cli . Using the following
~/.config/mermaid/config.json fixed it, and I
put the option in the ob-mermaid-cli-path above
so that it always gets loaded.
[2025-01-06 Mon]: Patch in progress, Stefan Kangas is looking into it.
Since A+ and I play lots of Minecraft together, I
figured it's a good opportunity to slowly get her
into the idea of documenting learning. Besides, I
can always practise it myself. Screenshots are
handy for that. In Minecraft Java, F1 hides the
usual heads-up display, and F2 takes the
screenshot. Usually, when I start taking
screenshots. A+ starts taking screenshots too. I
want to build on her enthusiasm by including her
screenshots in notes. To make it easy to
incorporate her pictures into our notes, I've
shared her GDLauncher folder and her Videos folder
with my computer using Syncthing so that I can
grab any screenshots or videos that she's taken.
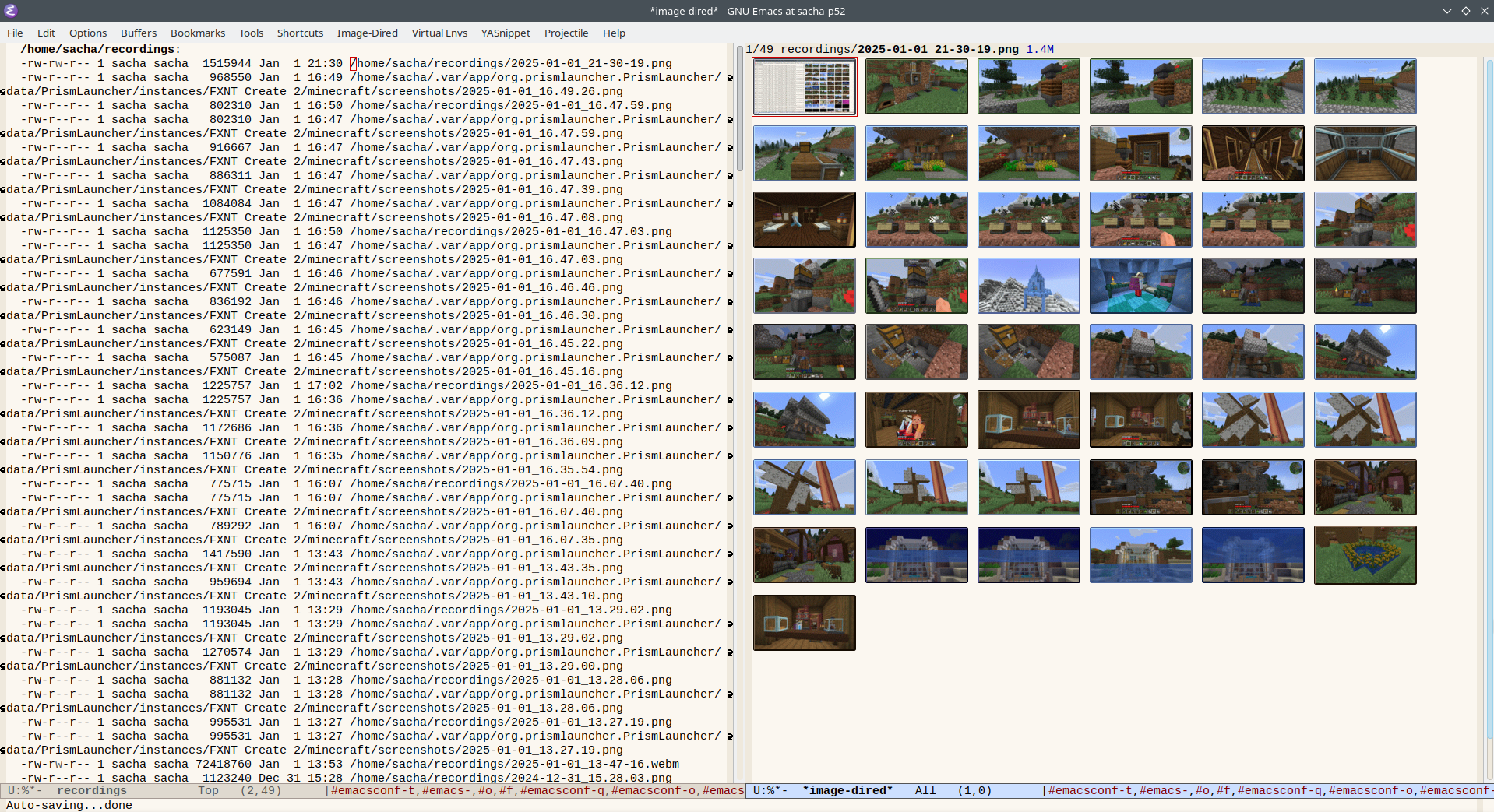
In Emacs, image-dired makes it easy to see
thumbnails. The neat thing is that it doesn't just
work with a single directory. Just like Dired, you
can give it a cons cell with a directory in the
first part and a list of files in the second part
as the first argument to the function, and it will
display those files. This means I can use
directory-files-recursively to make a list of
files, sort it to show most recent screenshots
first, limit it to the most recent items, and then
display a buffer with thumbnails.
image-dired-show-all-from-dir reports a small
error when you do this (I need to send a patch
upstream), so we hush it with condition-case in
my-show-combined-screenshots.
Figure 1: The result of my-show-combined-screenshots
In the *image-dired* buffer created by
my-show-combined-screenshots, I can use m
(image-dired-mark-thumb-original-file) to mark
images and C-u w
(image-dired-copy-filename-as-kill) to copy
their absolute paths.
To make it easier to create links to a file by
using org-store-link (which I've bound to C-c
l) and org-insert-link (C-c C-l in an Org
buffer), I can define a link-storing function that
takes the original filename:
I usually want to copy those files to another
directory anyway. I have a
my-org-copy-linked-files function in Copy linked
file and change link that copies the files and
rewrites the Org links. This means that I can copy
my notes to an index.org in a directory I share
with A+, save the images to an images
subdirectory, and export the index.html so that
she can read the notes any time she likes.
I've been experimenting with these default header
args for Org Babel source blocks.
(setq org-babel-default-header-args
'((:session . "none")
(:results . "drawer replace")
(:comments . "link") ;; add a link to the original source
(:exports . "both")
(:cache . "no")
(:eval . "never-export") ;; explicitly evaluate blocks instead of evaluating them during export
(:hlines . "no")
(:tangle . "no"))) ;; I have to explicitly set up blocks for tangling
In particular, :comments link adds a comment
before each source block with a link to the file
it came from. This allows me to quickly jump to
the actual definition. It also lets me use
org-babel-detangle to copy changes back to my
Org file.
I also have a custom link type to make it easier
to link to sections of my configuration file
(Links to my config). Org Mode prompts for the
link type to use when more than one function
returns a link for storing, so that was
interrupting my tangling with lots of interactive
prompts. The following piece of advice ignores all
the custom link types when tangling the link
reference. That way, the link reference always
uses the file: link instead of offering my
custom link types.