2025-06-30 Emacs news
| emacs, emacs-news- Call for Proposals open for EmacsConf 2025 (Reddit, lobste.rs)
- Emacs Carvival writing themes:
- Upcoming events (iCal file, Org):
- Emacs Paris: S: Emacs workshop in Paris (online) https://emacs-doctor.com/ Tue Jul 1 0830 America/Vancouver - 1030 America/Chicago - 1130 America/Toronto - 1530 Etc/GMT - 1730 Europe/Berlin - 2100 Asia/Kolkata - 2330 Asia/Singapore
- EmacsATX: Emacs Social https://www.meetup.com/emacsatx/events/307923518/ Wed Jul 2 1600 America/Vancouver - 1800 America/Chicago - 1900 America/Toronto - 2300 Etc/GMT – Thu Jul 3 0100 Europe/Berlin - 0430 Asia/Kolkata - 0700 Asia/Singapore
- M-x Research: TBA https://m-x-research.github.io/ Fri Jul 4 0800 America/Vancouver - 1000 America/Chicago - 1100 America/Toronto - 1500 Etc/GMT - 1700 Europe/Berlin - 2030 Asia/Kolkata - 2300 Asia/Singapore
- Emacs.si (in person): Emacs.si meetup #7 2025 (v #živo) https://dogodki.kompot.si/events/0fb2dc00-8cea-4365-a6ca-ab1a3e76f0ee Tue Jul 8 1900 CET
- OrgMeetup (virtual) https://orgmode.org/worg/orgmeetup.html Wed Jul 9 0900 America/Vancouver - 1100 America/Chicago - 1200 America/Toronto - 1600 Etc/GMT - 1800 Europe/Berlin - 2130 Asia/Kolkata – Thu Jul 10 0000 Asia/Singapore
- Atelier Emacs Montpellier (in person) https://lebib.org/date/atelier-emacs Fri Jul 11 1800 Europe/Paris
- Beginner:
- Emacs configuration:
- Emacs Lisp:
- Appearance:
- Navigation:
- TRAMP:
- Writing:
- Org Mode:
- Emacs Org Mode Date Range Calculated 2025_06_26_08:31:09 - YouTube (@unixbhaskar@mastodon.social)
- How I Use Org Mode Part One · 🌀 bledleys blog (@bledley@mastodon.social)
- Guix and Org mode tutorial (@civodul@toot.aquilenet.fr)
- Using Emacs Org-Babel instead of Jupyter(Lab) Notebooks (32:57)
- Built a simple Emacs package to sync Quip docs with Org-mode - looking for feedback!
- Emacs org mode changelog for your github repositories (37:36)
- Worg Org protocol page updated for 2025 (Reddit)
- orgfetcher: Use Python to fetch data from any external source and track it in an Org file
- Show HN: Ten Dollar Adventure, an interactive kids' book on entrepreneurship | Hacker News - Org Mode to Twinery (interactive fiction) and back again
- Completion:
- Coding:
- Shells:
- Charles Choi: Take Two: Eshell
- Irreal: How To Stop Emacs From Asking For Aliases change eshell-bad-command-tolerance or eshell-alternate-command-hook
- AI:
- Community:
- Multimedia:
- Other:
- Announcing Casual Man & Help (Reddit, Irreal)
- View and Annotate Your PDFS in Emacs – Pdf-tools and Org-noter (04:53)
- Emacs Reader 0.3.0 (Lambdex) (@divyaranjan@mathstodon.xyz) - refactoring, bugfixes, removed mupdf submodule
- Peter Tillemans: Consolidating Secrets in Pass
- Emacs trial & editor configuration (05:05:19)
- How to Install Emacs on Windows 11 (02:39)
- GNU Emacs【※音無し】 (03:17)
- Emacs development:
- New packages:
- conventional: Enable conventional syntax (MELPA)
- deflate: The DEFLATE compression algorithm in pure Emacs LISP (MELPA)
- easy-find: Simple file searching like Nemo (MELPA)
- elisp-dev-mcp: MCP server for agentic Elisp development (MELPA)
- gptel-commit: Generate commit message with gptel (MELPA)
- greger: Agentic coding environment with tool use, using Claude (MELPA)
- hdf5-viewer: Major mode for viewing HDF5 files (MELPA)
- helix: A minor mode emulating Helix keybindings (MELPA)
- nerd-icons-xref: Add nerd-icons to xref buffers (MELPA)
- simply-annotate: Enhanced annotation system with threading (MELPA)
- slothbar: Emacs X window manager status bar (MELPA)
- virtual-ring: Fixed size rings with virtual rotation (MELPA)
- wilson-ng-theme: A modernized version of the Wilson theme (MELPA)
Links from reddit.com/r/emacs, r/orgmode, r/spacemacs, r/planetemacs, Mastodon #emacs, Bluesky #emacs, Hacker News, lobste.rs, programming.dev, lemmy.world, lemmy.ml, planet.emacslife.com, YouTube, the Emacs NEWS file, Emacs Calendar, and emacs-devel. Thanks to Andrés Ramírez for emacs-devel links. Do you have an Emacs-related link or announcement? Please e-mail me at sacha@sachachua.com. Thank you!
You can comment on Mastodon or e-mail me at sacha@sachachua.com.
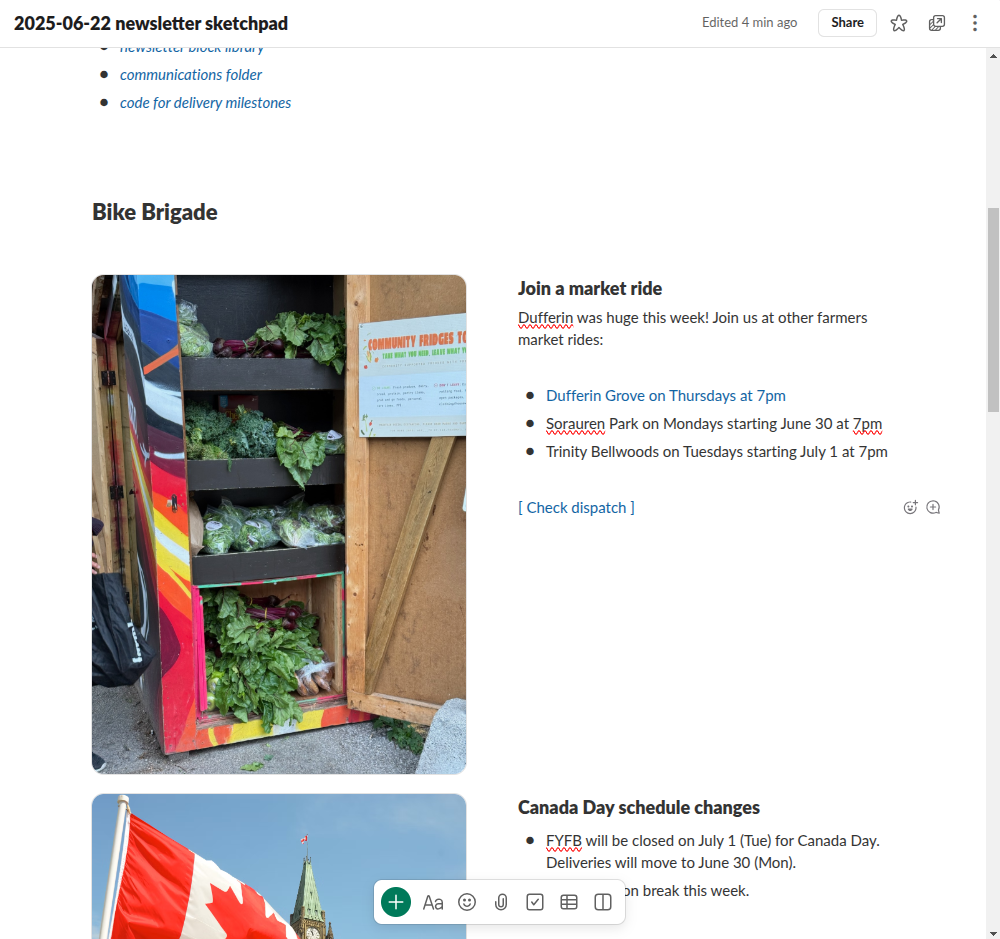



{kind=link}
{kind=link}
{kind=link}
{kind=link}