The next shift in our household will be when W- returns to work in a little over a month. It’ll be just me and A- most of the day. What will change in our daily routines, and what do we want to do now to make that easier? I’ve been reading Reddit posts to get a sense of what to expect, what kinds of friction points might come up, and what helps. There are some things to watch out for, but I think it’ll be manageable.
I won’t be able to pass A- to him during the day. That means we should have leftovers or a quick meal ready for lunch, so I don’t have to try to cook something with A- underfoot. If there’s laundry to fold, we should probably take it upstairs the night before. A- will become more independent over time, so I’ll be able to do more and more things.
W- will need work lunches,too. We’ll free up some space in our chest freezer and go back to preparing individual portions. It might be good to prepare most of the week’s food as well, so that dinner is easier.
I might have to take A- to her medical appointments by myself. We can meet the cardiologist at North York instead of Scarborough. Going to the Sick Kids Hospital is a bit harder by myself (bringing gear, going to the bathroom, comforting A- when she needs to be sedated for an exam), so we might save W-‘s days off for that, or I can tough it out. We survived long-haul flights, and we can deal with this too.
W- can’t easily rescue us if we get sick or need a lift when we’re out and about, but that’s why I have a transportation budget. If necessary, I can call a cab. It probably needs to be a public taxi so that I can carry A- without a car seat – I’m not sure Uber qualifies for that exception.
We’ll keep nights flexible so that W- can work if he wants to or hang out with A- if he wants to. He can play with her while I do the evening routines. I’ll let W- decompress from work and settle in before passing her over.
I’ll try to get groceries and do other errands in the afternoon so that we can free up evening time. It’ll also be good to take A- to centres for socialization.
Weekends will be mostly the same as now, I think: laundry, cooking, cleanup, errands, play, and a bit of hobby time.
Many people find it difficult and isolating to go without adult conversation or external validation for long stretches. Based on my experience with hermit mode and with my 5-year experiment, I’ll probably be okay. Writing is a good opportunity to string words together and think about stuff, and I can do that during A-‘s nursing sessions and naps. My blog, my journal, consulting, and the Emacs community help with validation and a sense of accomplishment.
I have my own savings and I contribute to the household, so I don’t feel financially dependent. I can even invest for the long term.
It’s also good to make sure W- and I stay in sync even if we’re moving in different worlds. Cooking is an obvious touchpoint. Keeping up with tech helps me relate to his stories and interests, and observing A- will probably give me plenty of stories to share. I can use some of my late-night discretionary time to play video games with him, and I can read about woodworking and other DIY pursuits. Duplo would be good to explore, too – we can have fun with the build of the day. If I pay close attention, the minutiae of everyday life is actually quite fascinating, and I can share what I learn.
The next shift after this will probably be when A- starts walking around. I might need to keep a closer eye on her to make sure she doesn’t get into too much trouble, and we might also modify our routines so that she gets lots of practice. As she learns how to ask questions, we’ll add more field trips, too.
One of the nice things about minor oopses is that they let you see all sorts of little experiments to try. =)
It took me a little over 4,400 steps to reach the Jane/Dundas library, where I found two of the new videos I'd been looking forward to borrowing (too new to request through the system, so you have to catch them at your library branch). As I went to check them out, I realized I had left my belt bag at home. I'd been using my belt bag as a purse organizer, actually, tucking the bag into whichever tote I was going to use for a walk. This time, however, I'd remembered to add two folded-up tote bags, a water bottle, my e-reader, and my keys to my main bag, but I forgot the belt bag on the kitchen table. I'd forgotten to do my usual pre-flight verbal checklist, so I hadn't caught the error as I headed out the door. So there I was at the library: no library card, no other forms of identification, nothing. No point in going to the grocery store without cash or a credit card, either. Oh well!
Still, it turns out that a walk passes by pretty quickly when there's something I can read. The e-reader works out well for this because I can page through it with gloves on. Better than my smartphone, which is finicky even with touchscreen gloves. Better than a paper book, even, since the pages can be hard to turn with gloves on. Four winters after I bought my Kindle, I've finally found its niche, so there's that.
I rarely forget my cards like this. It's been more than a year since the last time, I think. Maybe even two or three. No big deal. =) There's always another walk, another opportunity to get some exercise. In the meantime, there are lots of small changes I can play with if I think this situation might come up more often. I could:
Keep an extra copy of the barcode on my library card: I could photocopy a set of cards and keep that copy in my winter hat (along with a little bit of cash), since I usually wear that when I go for a day-time walk.
Keep the belt bag in my favourite canvas bag.
Switch to my vest of many pockets, since leaving that behind is slightly more obvious than leaving behind a small belt bag. The extra layer might be more comfortable in winter, too.
Strengthen the practice of doing a verbal pre-flight checklist as I head out the door.
There and back was an hour and a half of walking at the leisurely pace of about 3.5km/h. Although there were some points when I might have liked to have thicker gloves, it was pleasant enough without strong winds and with only a slight scattering of snow. I might go for another long walk tomorrow, perhaps to a different library. The walk fits my life nicely, and it feels good to move a bit.
It's nice to have the buffer of time so that I don't have to worry about little mistakes, and it's nice to live in such a walkable neighbourhood that oopses like these still give me the benefit of exercise. =)
UPDATE 2015-11-27: Here's the video of my hackathon pitch:
UPDATE 2015-11-18: I figured out how to make this entirely client-side, so you don't have to run a separate server. First, install either Tampermonkey (Chrome) or Greasemonkey (Firefox). Then install the user script insert-visualize-link.user.js , and the Visualize link should appear next to the library branch options on Toronto Public Library search result pages. See the Github repository for more details.
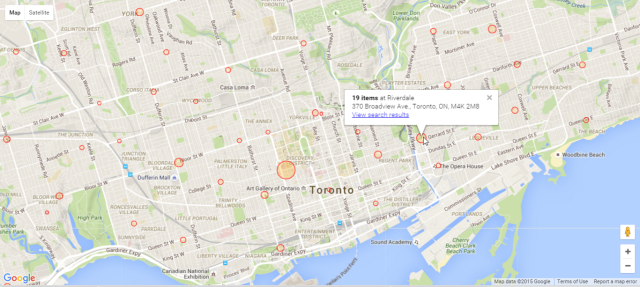
Yay! My neighbourhood library visualization won at the Toronto Public Library hackathon. It added a Visualize link to the search results page which mapped the number of search results by branch. For example, here's a visualization of a search that shows items matching "Avengers comics".
It's a handy way to see which branches you might want to go to so that you can browse through what's there in person.
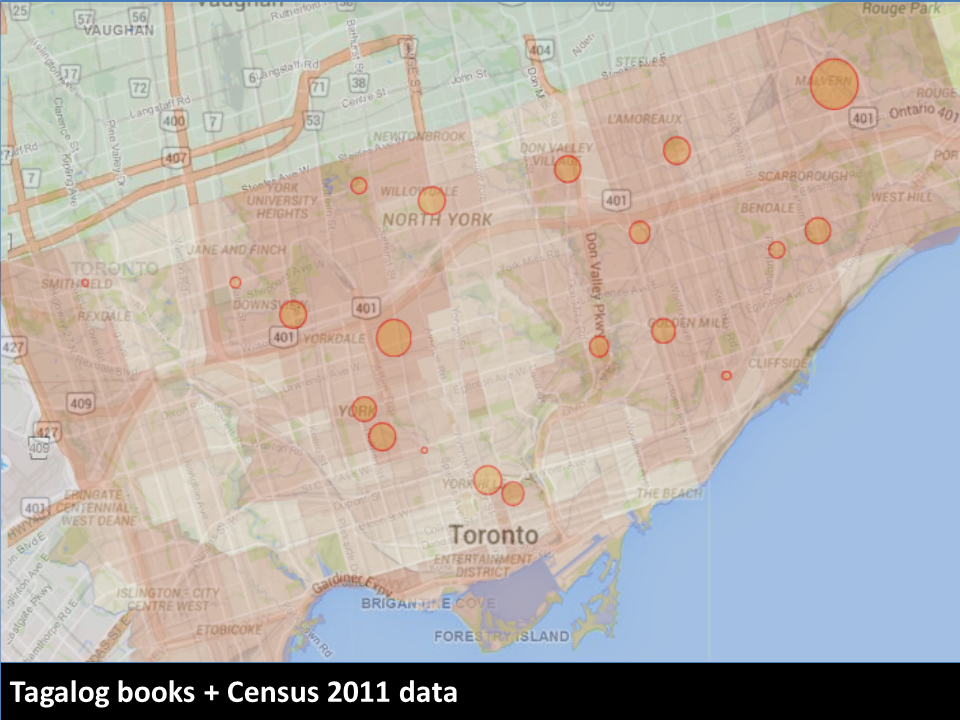
Librarians could also use it to help them plan their selections, since it's easy to see the distribution across branches. For example, here's the visualization for books in Tagalog.
The collections roughly match up with Wellbeing Toronto's data on Tagalog as the home language, although there are some areas that could probably use collections of their own.
Incidentally, I was delighted to learn that Von Totanes had done a detailed analysis of the library's Filipino collections in the chapter he wrote in Filipinos in Canada: Disturbing Invisibility (Coloma, McElhinny, and Tungohan, 1992). Von sent me the chapter after I mentioned the hackathon on Facebook; yay people bumping into other people online!
Personally, I'm looking forward to using this visualization to see things like which branches have new videos. Videos released in the past year can only be borrowed in person – you can't request them online – so it's good to check branches regularly to see if they're there. It would be even better if the library search engine had a filter for "On the shelf right now", but in the meantime, this visualization tool gives me a good idea of our chances of picking up something new to watch while we're folding laundry. =)
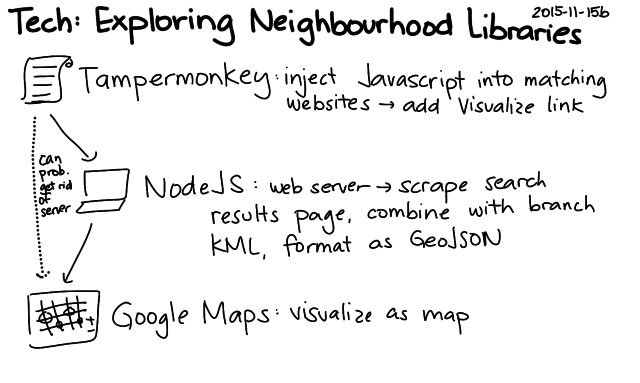
The code works by extracting the branch names and totals on the left side of search pages and combining those with the locations of the branches (KML). I don't really need the server component, so I'm thinking of rewriting the script so that it runs entirely client-side – maybe as a Chrome extension or as a user script. That way, other people can play with the idea without running their own server (and without my having to keep a server around), and we can try it out without waiting for the library to integrate it into their website. That said, it would be totally awesome to get it into the interface of the Toronto Public Library! We'll just have to see if it can happen. =) Happy to chat with library geeks to get this sorted out.
It was fun working on this. W- decided to join me at the last minute, so it turned into a fun weekend of hanging out with my husband at the library. I wanted to keep my weekend flexible and low-key, so I decided not to go through the team matchmaking thing. W- found some comfy chairs in the corner of the area, I plugged in the long extension cord I brought, and we settled in.
I learned a lot from the hackathon mentors. In particular, I picked up some excellent search and RSS tips from Alan Harnum. You can't search with a blank query, but he showed me how you can start with a text string, narrow the results using the facets on the left side, and then remove the text string from the query in order to end up with a search that uses only the facets. He also showed me that the RSS feed had extra information that wasn't in the HTML source and that it could be paginated with URL parameters. Most of the RSS feeds I'd explored in the past were nonpaginated subsets of the information presented on the websites, so it was great to learn about the possibilities I had overlooked.
The faceted search was exactly what I needed to list recent videos even if I didn't know what they were called, so I started thinking of fun tools that would make hunting for popular new videos easier. (There have been quite a few times when I've gone to a library at opening time so that I could snag a video that was marked as available the night before!) In addition to checking the specific item's branch details to see where it was on the shelf and which copies were out on loan, I was also curious about whether we were checking the right library, or if other libraries were getting more new videos than our neighbourhood library was.
W- was curious about the Z39.50 protocol that lets you query a library catalogue. I showed him the little bits I'd figured out last week using yaz-client from the yaz package, and he started digging into the protocol reference. He figured out how to get it to output XML (format xml) and how to search by different attributes. I'm looking forward to reading his notes on that.
Me, I figured that there might be something interesting in the visualization of new videos and other items. I hadn't played around a lot with geographic visualization, so it was a good excuse to pick up some skills. First, I needed to get the data into the right shape.
Step 1: Extract the data and test that I was reading it correctly
I usually find it easier to start with the data rather than visualizations. I like writing small data transformation functions and tests, since they don't involve complex external libraries. (If you miss something important when coding a visualization, often nothing happens!)
I wrote a function to extract information from the branch CSV on the hackathon data page, using fast-csv to read it as an array of objects. I tested that with jasmine-node. Tiny, quick accomplishment.
Then I worked on extracting the branch result count from the search results page. This was just a matter of finding the right section, extracting the text, and converting the numbers. I saved a sample results page to my project and used cheerio to parse it. I decided not to hook it up to live search results until I figured out the visualization aspect. No sense in hitting the library website repeatedly or dealing with network delays.
Step 2: Make a simple map that shows library branches
I started with the Google Maps earthquake tutorial. The data I'd extracted had addresses but not coordinates. I tried using the Google geocoder, but with my rapid tests, I ran into rate limits pretty early. Then it occurred to me that with their interest in open data, the library was the sort of place that would probably have a file with branch coordinates in terms of latitude and longitude. The hackathon data page didn't list any obvious matches, but a search for Toronto Public Library KML (an extension I remembered from W-'s explorations with GPS and OpenStreetMap) turned up the file I wanted. I wrote a test to make sure this worked as I expected.
Step 3: Combine the data
At first I tried to combine the data on the client side, making one request for the branch information and another request for the results information. It got a bit confusing, though – I need to get the hang of using require in a from-scratch webpage. I decided the easiest way to try my idea out was to just make the server combine the data and return the GeoJSON that the tutorial showed how to visualize. That way, my client-side HTML and JS could stay simple.
Step 4: Fiddle with the visualization options
Decisions, decisions… Red was too negative. Blue and green were hard to see. W- suggested orange, and that worked out well with Google Maps' colours. Logarithmic scale or linear scale? Based on a maximum? After experimenting with a bunch of options, I decided to go with a linear scale (calculated on the server), since it made sense for the marker for a branch with a thousand items to be significantly bigger than a branch with five hundred items. I played with this a bit until I came up with maximum and minimum sizes that made sense to me.
Step 5: Hook it up to live search data
I needed to pass the URL of the search results, and I knew I wanted to be able to call the visualization from the search results page itself. I used TamperMonkey to inject some Javascript into the Toronto Public Library webpage. The library website didn't use JQuery, so I looked up the plain-vanilla Javascript way of selecting and modifying elements.
I wanted to display information on hover and filter search results on click. Most of the tutorials I saw focused on how to add event listeners to individual markers, but I eventually found an example that showed how to add a listener to map.data and get the information from the event object. I also found out that you could add a title attribute and get a simple tooltip to display, which was great for confirming that I had the data all lined up properly.
Step 7: Cache the results
Testing with live data was a bit inconvenient because of occasional timeouts from the library website, so I decided to cache search results to the filesystem. I didn't bother writing code for checking last modification time, since I knew it was just for demos and testing.
Step 8: Prettify the hover
The tooltip provided by title was a little bare, so I decided to spend some time figuring out how to make better information displays before taking screenshots for the presentation. I found an example that showed how to create and move an InfoWindow based on the event's location instead of relying on marker information, so I used that to show the information with better formatting.
Step 9: Make the presentation
Here's how I usually plan short presentations:
Figure out the key message and the flow.
Pick a target words-per-minute rate and come up with a word budget.
Draft the script, checking it against my word budget.
Read the script out loud a few times, checking for time, tone, and hard-to-say phrases.
Annotate the script with notes on visual aids.
Make visuals, take screenshots, etc.
Record and edit short videos, splitting them up in Camtasia Studio by using markers so that I can control the pace of the video.
Copy the script (or keywords) into the presenter's notes.
Test the script for time and flow, and revise as needed.
I considered two options for the flow. I could start with the personal use case (looking for new videos) and then expand from there, tying it into the library's wider goals. That would be close to how I developed it. Or I could start with one of the hackathon challenges, establish that connection with the library's goals, and then toss in my personal use case as a possibly amusing conclusion. After chatting about it with W- on the subway ride home from the library, I decided to start with the second approach. I figured that would make it easier for people to connect the dots in terms of relevance.
I used ~140wpm as my target, minus a bit of a buffer for demos and other things that could come up, so roughly 350 words for 3 minutes. I ran through the presentation a few times at home, clocking in at about 2:30. I tend to speak more quickly when I'm nervous, so I rehearsed with a slightly slower pace. That way, I could get a sense of what the pace should sound like. During the actual presentation, though, I was a teensy bit over time – there was a bit of unexpected applause. Also, even though I remembered to slow down, I didn't breathe as well as I probalby should've; I still tend to breathe a little shallowly when I'm on stage. Maybe I should pick a lower WPM for presentations and add explicit breathing reminders. =)
I normally try to start with less material and then add details to fit the time. That way, I can easily adjust if I need to compress my talk, since I've added details in terms of priority. I initially had a hard time concisely expressing the problem statement and tying together the three examples I wanted to use, though. It took me a few tries to get things to fit into my word budget and flow in a way that made me happy.
Anyway, once I sorted out the script, I came up with some ideas for the visuals. I didn't want a lot of words on the screen, since it's hard to read and listen at the same time. Doodles work well for me. I sketched a few images and created a simple sequence. I took screenshots for the key parts I wanted to demonstrate, just in case I didn't get around to doing a live demo or recording video. That way, I didn't have to worry about scrambling to finish my presentation. I could start with something simple but presentable, and then I could add more frills if I had time.
Once the static slides were in place, I recorded and edited videos demonstrating the capabilities. Video is a nice way to give people a more real sense of how something works without risking as many technical issues as a live demo would.
I had started with just my regular resolution (1366×768 on my laptop) and a regular browser window, but the resulting video was not as sharp as it could have been. Since the presentation template had 4:3 aspect ratio, I redid the video with 1024×768 resolution and a full-screen browser in order to minimize the need for resizing.
I sped up boring parts of the video and added markers where I wanted to split it into slides. Camtasia Studio rendered the video into separate files based on my markers. I added the videos to individual slides, setting them to play automatically. I like the approach of splitting up videos onto separate slides because it allows me to narrate at my own pace instead of speeding up or slowing down to match the animation.
I copied the segments of my script to the presenter notes for each slide, and I used Presenter View to run through it a few more times so that I could check whether the pace worked and whether the visuals made sense. Seemed all right, yay!
Just in time, too. I had a quick lunch and headed off to the library for the conclusion of the hackathon.
There wsa a bit of time before the presentations started. I talked to Alan again to show him what I'd made, hear about what he had been working on, and pick his brain to figure out which terms might resonate with the internal jargon of the library – little things, like what they call the people who decide what kinds of books should be in which libraries, or what they call the things that libraries lend. (Items? Resources? Items.) Based on his feedback, I edited my script to change "library administrators" to "selection committees". I don't know if it made a difference, but it was a good excuse to learn more about the language people used.
I tested that the presentation displayed fine on the big screen, too. It turned out that the display was capable of widescreen input at a higher resolution than what I'd set, but 1024×768 was pretty safe and didn't look too fuzzy, so I left it as it was. I used my presentation remote to flip through the slides while confirming that things looked okay from the back of the room (colours, size, important information not getting cut off by people's heads, etc.). The hover text was a bit small, but it gave the general idea.
And then it was presentation time. I was third, which was great because once I finished, I could focus on other people's presentations and learn from their ideas. Based on W-'s cellphone video, it looks like I remembered to use the microphone so that the library could record, and I remembered to look up from my presenter notes and gesture from time to time (hard when you're hidden behind the podium, but we do what we can!). I stayed pretty close to my script, but I hope I kept the script conversational enough that it sounded more like me instead of a book. I didn't have the mental bandwidth to keep an eye on the timer in the center of the presenter view, but fortunately the time worked out reasonably well. I concluded just as the organizer was getting up to nudge me along, and I'd managed to get to all the points I wanted to along the way. Whew!
Anyway, that's a quick braindump of the project and what it was like to hack it together. I'll probably write some more about following up on ideas and about other people's presentations, but I wanted to get this post out there while the experience was fresh in my head. It was fun. I hope the Toronto Public Library will take the hackathon ideas forward, and I hope they'll get enough out of the hackathon that they'll organize another one! =)
From time to time, I notice a spike in the number of small mistakes I make due to inattention. It's a good sign to slow things down, rejig systems and habits, and figure out how to make things better. For example, noticing that I often lost track of small things I was carrying around, I switched to a belt bag in summer and a vest in winter.
There are still quite a few slips I haven't figured out how to work around, like the occasional times I put the oven mitts on the opposite side of the stove from where they usually are (I must have absentmindedly thought "Aha! An empty hook!"), or the time I tucked the sesame oil into the fridge. ("I'm holding a bottle; many bottles go into the shelves on the fridge door; this probably goes into the shelves on the fridge door.")
It turns out that there are lots of forms of absent-mindedness. Cheyne, Carierre, and Smilek (2005) defined a scale for attention-related cognitive errors (ARCES) that goes like this:
I have absent-mindedly placed things in unintended locations (e.g., putting milk in the pantry or sugar in the fridge).
When reading I find that I have read several paragraphs without being able to recall what I read.
I have misplaced frequently used objects, such as keys, pens, glasses, etc.
I have found myself wearing mismatched socks or other apparel.
I have gone into a room to get something, got distracted, and left without what I went there for.
I fail to see what I am looking for even though I am looking right at it.
I begin one task and get distracted into doing something else.
I have absent-mindedly mixed up targets of my action (e.g. pouring or putting something into the wrong container).
I make mistakes because I am doing one thing and thinking about another.
I have gone to the fridge to get one thing (e.g., milk) and taken something else (e.g., juice).
I have to go back to check whether I have done something or not (e.g., turning out lights, locking doors).
I go into a room to do one thing (e.g., brush my teeth) and end up doing something else (e.g., brush my hair).
I find that I tend to be okay at broad strokes (intentions), but sometimes I miss finer details. I've walked out of the house in inside-out or back-to-front clothing before (technical shirts feel the same either way!), although usually W- helps me catch those situations.
It's not that bad, though. Although I sometimes don't remember what I walked into a room for (especially if I get distracted by a conversation part way), I can almost always recall what I intended to do, and what was before that (if I hadn't finished that yet). It also helps to have the habit of writing down quick notes and consulting my agenda for tasks to work on, but mental rehearsal is usually enough for me to "pop the stack".
Fortunately, all this appears to be normal human experience. I might be a smidge more absent-minded than some folks, but it doesn't get in the way of life, and even W- forgets a mug of hot water in the microwave occasionally. Besides, I enjoy working around the limitations of my brain by taking notes and tweaking the way I live.
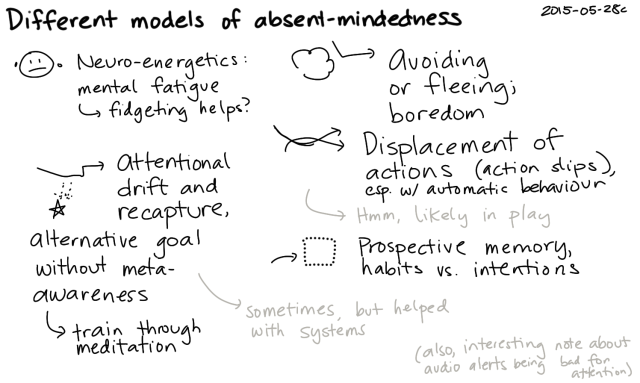
This is probably why I enjoy reading research into the brain. It turns out that there are many possible explanations for absent-mindedness. There are different ways to measure it, and even a few ways to play around with it.
When I read through the research, I feel oddly optimistic. Even though I know I'm likely to get more absent-minded as I grow older, I also know that experience, mindfulness, more deliberate responses, and good habits using external-memory systems can help a lot.
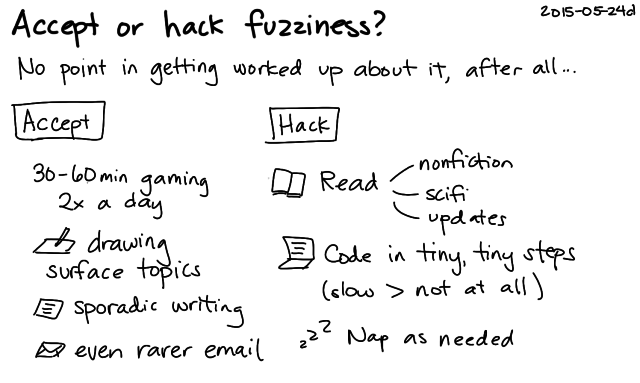
I notice that I respond to the fuzziness in my brain with curiosity instead of frustration. I like this attitude, and I hope to keep it as I go through life. Instead of getting frustrated with myself, I get a good laugh out of the little mishaps (oh hey, I've put the plates where the saucers usually go; I can see how that happened!), and I explore it to learn more. So a bit of both, I guess: accept the fuzziness and hack around it.
Besides, the incidents aren't that frequent. They're just more prominent in my memory because I pay attention to them. =)
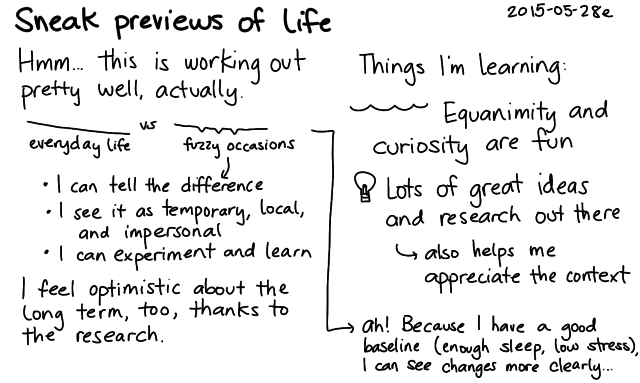
Actually, it works out really nicely that I'm thinking about this at this time. I know people around me also experience absent-mindedness, so I don't have to have a hypochrondiac's worry about early-onset diseases. (Although if we get to the point where this does actually get in the way of an awesome life, I'll be sure to ask for help.) Instead, since I keep my life relatively smooth (low stress, plenty of sleep), I have a baseline of feeling good. That lets me notice changes more clearly, instead of the changes getting obscured in the noise of perpetual sleep deprivation or constant background stress. It also means that I can think of fuzzy-brain moments as temporary, local, and impersonal, and I can use my non-fuzzy times to figure out how to make the fuzzy times even better.
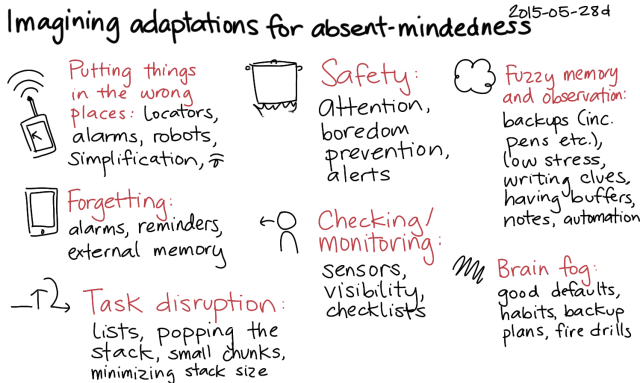
What are some things that could make absent-minded moments better?
I might need to wait for better technology for some of these ideas, but most of the ideas are ready to go. Putting things in the wrong places is a minor inconvenience, and safety hasn't been a big issue for me yet. I'll probably focus on fuzzy memory and observation, looking for ways to take notes on or automate the things I do. For example, I've added notes on how to find and deploy code to the TODO lists for my personal projects, since I might go a few months without thinking about them. Notes also help with checking and monitoring. As I gain more experience and develop those systems and habits, that will help with brain fog as well. I trust my lists to help me with task disruption, and I keep lots of buffers in my life to soften the impact of forgetting. It's a fascinating balance between taking things slowly and keeping things interesting enough so that my brain doesn't go into too much of an automatic mode.
It's odd how taking this kind of perspective changes how I experience forgetfulness. Instead of thinking to myself, "Where did I put those keys? I suck!", I find myself thinking, "Oh look! I wonder what I'll learn from this one…" We'll see!
Atul Gawande’s The Checklist Manifesto: How to Get Things Right (2009) emphasizes the power of checklists for improving reliability. Errors creep in when we forget things entirely or skip over things we should have done. In medicine, these errors can be fatal.
Gawande draws on his experience as a surgeon, the research he conducted with the World Health Organization, and insights from construction, finance, and other industries that take advantage of checklists to improve processes.
The book discusses ways to address the cultural resistance you might encounter when introducing a checklist. It recommends making sure that checklists are precise, efficient, short, easy to use, and practical. You need to develop a culture of teamwork where people feel that they can speak up as part of a team. You may even need to modify supporting systems to make the checklist doable.
I’ve sketched the key points of the book below to make it easier to remember and share. Click on the image for a larger version that you can print if you want.
I like the reminders that you should design your checklists around logical “pause points,” keep checklists focused on the essentials, and treat people as smart instead of making the checklist too rigid.
The book distinguishes between “Do-Confirm” checklists, which allow experienced people to work quickly and flexibly with a confirmation step that catches errors, and “Read-Do” checklists, which walk people step-by-step through what they need to do. I’m looking forward to applying the book’s tips towards systematizing my sharing. For example, I’m working on a YASnippets in Emacs that will not only display a “Read-Do” checklist for doing these sketched notes, but will also assemble the links and code to do the steps easily. Sure, no one will die if I miss a step, but I think discipline and thoroughness might yield dividends. I also want to develop a good “Do-Confirm” process for writing and committing code; that could probably save me from quite a few embarrassing mistakes.
I’m interested in the diffusion of ideas, so I was fascinated by the book’s coverage of the eight-hospital checklist experiment the WHO conducted. The book discussed the challenges of getting other people to adopt checklists, and adapting the checklists to local conditions. Here’s an excerpt:
… By the end, 80 percent reported that the checklist was easy to use, did not take a long time to complete, and had improved the safety of care. And 78 percent actually observed the checklist to have prevented an error in the operating room.
Nonetheless, some skepticism persisted. After all, 20 percent did not find it easy to use, thought it took too long, and felt it had not improved the safety of care.
Then we asked the staff one more qusetion. “If you were having an operation,” we asked, “would you want the checklist to be used?”
A full 93 percent said yes.
There’s a comparison to be made between the reluctance of doctors to accept checklists and the committed use of checklists by pilots and builders. I came across a quote from Lewis Schiff’s Business Brilliant in this comment by Rich Wellman:
The following quote sums up the essential difference between a checklist for a doctor and a checklist for a pilot.
“How can I put this delicately? Pilots are seated in the same planes as their passengers. Surgeons are not under the same knives as their patients. To paraphrase an old joke, surgeons may be interested in safety, but pilots are committed.”
So checklists are a good idea when you’re dealing with people’s lives, but what about the rest of us? Checklists are good for catching errors and building skills. They’re also great for reducing stress and distraction, because you know that the checklist is there to help you think. That’s why packing lists are useful when you travel.
Already a fan of checklists? Tell me what you have checklists for!
Let me think about how I organize my Org Mode files, and how I might improve that. =)
Separate files
You can put different things in different files, of course. I use a few large Org files instead of lots of small ones because I prefer searching within files rather than searching within directories. Separate files make sense when I want to define org-custom-agenda-commands that summarize a subset of my tasks. No sense in going through all my files if I only want the cooking-related ones.
What would help me make better use of lots of files? I can practise on my book notes, which I've split up into one file per book. It's easy enough to open files based on their titles (which I put in my filenames). But I don't have that overall sense of it yet. Maybe #+INDEX: entries, if I can get them to generate multiple hyperlinks and I have a shortcut to quickly grep across multiple files (maybe with a few lines of context)? Maybe a manual outline, an index like the one I've been building for my blog posts? I can work with that as a starter, I think.
Okay. So, coming at it from several directions here:
A manual map based on an outline with lots of links, with some links between topics as well – similar to my blog outline or to my evil plans document
Quick way to grep? helm-do-grep works, but my long filenames are hard to read.
Links between notes and to blog posts
TODOs, agenda views
Outlines
Within each file, outlines work really well. You can create any number of headings by using *, and you can use TAB to collapse or expand headings. You can promote or demote subtrees, move them around, or even sort them.
I generally have a few high-level headings, like this:
* Projects** One heading per current project*** TODO Project task* Reference
Information I need to keep track of
* Other notes* Tasks** TODO Lots of miscellaneous tasks go here** TODO Lots of miscellaneous tasks go here** TODO Lots of miscellaneous tasks go here
Every so often, I do some clean-up on my Org files, refiling or archiving headings as needed. This makes it easier to review my current list of projects. I keep this list separate from the grab-bag of miscellaneous tasks and notes that might not yet be related to particular projects.
I use org-refile with the C-u argument (so, C-u C-c C-w) to quickly jump to headings by typing in part of them. To make it easy to jump to the main headings in any of my agenda files, I set my org-refile-targets like this:
How can I get better at organizing things with outlines? My writing workflow is a natural place to practise. I've accumulated lots of small ideas in my writing file, so if I work on fleshing those out even when I don't have a lot of energy–breaking things down into points, and organizing several notes into larger chunks–that should help me become more used to outlines.
Tags
In addition to organizing notes in outlines, you can also use tags. Tags go on the ends of headings, like this:
** Heading title :tag:another-tag:
You can filter headings by tags using M-x org-match-sparse-tree (C-c \) or M-x org-tags-view (C-c a m).
Tags are interesting as a way to search for or filter out combinations. I used tags a lot more before, when I was using them for GTD contexts. I don't use them as much now, although I've started tagging recipes by main ingredient and cooking method. (Hmm, maybe I should try visualizing things as a table…) I also use tags to post entries under WordPress blog categories.
How can I get better at using tags? I can look for things that don't lend themselves well to outlines, but have several dimensions that I may want to browse or search by. That's probably going to be recipe management for now. If I figure out a neat way to add tags to my datetree journal notes and then visualize them, that might be cool too.
Links
Org Mode links allow me to refer not only to web pages, files, headings, and text searches, but to things like documentation or even executable code. When I find myself jumping between places a lot, I tend to build links so that I don't have to remember what to jump to. My evil plans Org Mode file uses links to create and visualize structure, so that's pretty cool, too. But there's still a lot more that I could probably do with this.
How can I use links more effectively? I can link to more types of things, such as Lisp code. I can go back over my book notes and fill in the citation graph out of curiosity. Come to think of it, I could do that with my writing as well. My writing ideas rarely fit in neat outlines. I often feel like I'm combining multiple threads, and links could help me see those connections.
In addition to explicit links, I can also define “radio targets” that turn any instance of that text into a hyperlink back to that location. Only seems to work within a single file, though, and I've never actually used this feature for something yet.
Properties
You can set various properties for your Org Mode subtrees and then display those properties in columns or filter your subtrees by those properties. I've used Effort to keep track of effort estimates and I have some agenda commands that use that. I also use a custom Quantified property to make it easier to clock into tasks using my Quantified Awesome system.
I could track energy level as either tags or properties. Properties allow for easier sorting, I think. Can I define a custom sort order, or do I have to stick with numeric codes? Yeah, I can sort by a custom function, so I can come up with my own thing. Okay. That suggests a way I can learn to use properties more effectively.
There are even more ways to organize Org Mode notes in Emacs (agenda views, exports, etc.), but the ones above look like good things to focus on. So much to try and learn!
I was thinking about how I can use these snippets of time to improve in programming, writing, and drawing. I realized that although I can easily imagine how other people can write or draw using fragmented time (writers scribbling in notebooks on top of washing machines, artists doodling on the subway), programming seems a lot less tractable. It doesn't feel like you can break it up and squeeze it into different parts of your day as much.
It is generally accepted that context switching is evil when it comes to programming. So I've been carrying around this idea that Real Programmers are people who can pull all-nighters hacking on tough problems, holding elaborate structures in their heads. Your standard hero programmer stereotype, with the pinnacle being someone either building complex, cool stuff, possibly maintaining large and useful open source software.
Hence this little mental disconnect. I'm pretty certain I can get there someday if I really want to, but probably not if I extrapolate from current circumstances. Even maintaining a tiny piece of software sounds like more commitment than I want at the moment. (Heck, I might go a few weeks without responding to e-mail.)
Fortunately, I spent my first few working years in a corporate environment, where mentors showed me that it's totally possible to be an Awesome Geek while still working a roughly 9-to-5 job, having families and hobbies, and getting plenty of sleep. Thank goodness. So I have this alternate model in my head, not of a Hero Programmer, but rather of solid contributors who keep making gradual progress, help teams of people become more productive, and who enjoy solving interesting challenges and expanding their skills.
So let's say that I want to play with my assumption that programming is the sort of thing that's hard to squeeze into the nooks and crannies of one's day, at least not the way writing and drawing can. I know that I can go through technical documentation and design resources even if my mind isn't completely awake, and I can still pick up useful things.
What is it about writing and drawing that make them suitable even in small doses, and how can I tweak programming? Writers can think about stuff during other activities. I can reflect on ideas while walking or cooking, for example. When I program, I still need more of that back-and-forth with a computer and an Internet connection, but maybe I'll need less of that as I develop more experience. I can set pen to paper during any spare moment, sketching a quick line and seeing where it takes me from there. I might not be able to do that with implementation, but I can use that same playfulness to explore design. Behavior-driven development makes it easier to break projects down into tiny, clear steps, and have a way of verifying progress (without too much backsliding!). Getting deeper into frameworks and tools will help me do more with less effort when I do sit down at a computer.
Okay. I can do this. Worst-case scenario, I just move slowly until I get past this particular phase. I've seen role models who've pulled that off well, so that's totally cool. Best-case scenario, I figure out how to hack around some of my current cognitive limitations, and maybe that might help other people who find themselves in the same situation too.