I’m curious about the internal citation of my blog. Which thoughts have been developed over a long chain of posts? Which posts do I often link to? Where are there big jumps in time? Where have I combined threads?
I’ll probably need to build my own data extractor so that it can:
- ignore weekly and monthly reviews, since I link to everything in those,
- reconcile short and long permalinks, redirection, and sneak previews,
- and maybe even index my sketches and look at follow-ups
and I’ll probably want to create something that I could eventually plot as an SVG or imagemap using Graphviz, or maybe analyze using Gephi.
It would be super-interesting to create some kind of output that I could fold into my blog outline or into individual posts. I would need a static dump for that one, I think.
How would I build something like this? One time, I used Ruby to analyze the text of my blog. That might work. I might be able to pull out all the link hrefs, do lookups…
As of Dec 3, 2014, there are 87 posts in 2014 that link to previous posts, out of 259 non-review posts (so roughly 34%). I used this SQL query to get that:
SELECT post_title FROM wp_posts WHERE post_content LIKE ‘%<a href=”https://sachachua.com/blog/20%’ AND post_date >= ‘2014-01-01’ AND post_title NOT LIKE ‘%review:%’ AND post_state=’publish’;
Hmm. I might even be able to do some preliminary explorations with Emacs and text processing instead of writing a script to analyze this, if I focus on 2014 and ignore the special cases (short permalinks, redirection, and sneak previews), just to see what the data looks like. Rough technical notes:
perl -i -p -e s/href/\nhref/gi 2014-manip.html
grep http://sachachua.com/blog/20 2013-manip.html > list-2013
perl -i -p -e "s/(<\/a>(<\/h2>)?).*/$1/gi" list-2013
(defun sacha/misc-clean-up-reviews ()
(interactive)
(while (re-search-forward "\\(Monthly\\|Weekly\\) review: .*</h2>" nil t)
(let ((start (line-beginning-position)))
(re-search-forward "</h2>")
(delete-region start (line-beginning-position))
(goto-char (line-beginning-position)))))
(defun sacha/org-tabulate-links ()
(interactive)
(goto-char (point-min))
(let (main-link edges nodes)
(while (not (eobp))
(if (looking-at "^href=\"\\(.*?\\)\".*?</a></h2>")
(progn
(setq nodes (cons (match-string 1) nodes))
(setq main-link (match-string 1)))
(if (looking-at "^href=\"\\(.*?\\)\"")
(setq edges (cons (concat
main-link
"\t"
(match-string 1)
) edges))))
(forward-line 1))
(kill-new (mapconcat 'identity edges "\n"))))
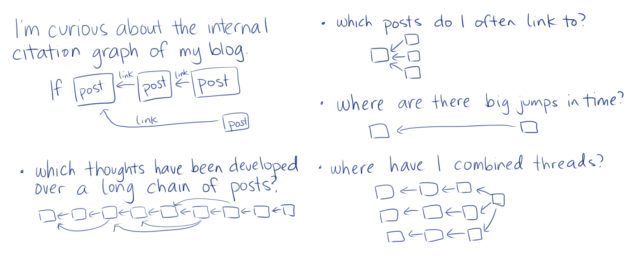
Ooooh. Pretty. Gephi visualization of the edge list formed by links, using the Yifan Hu layout. That big thread in the middle, that’s the one about taskmasters and choice and productivity, which is indeed the core theme running through this year of the experiment. The cluster on the right is a year in review. We see lots of little links too.
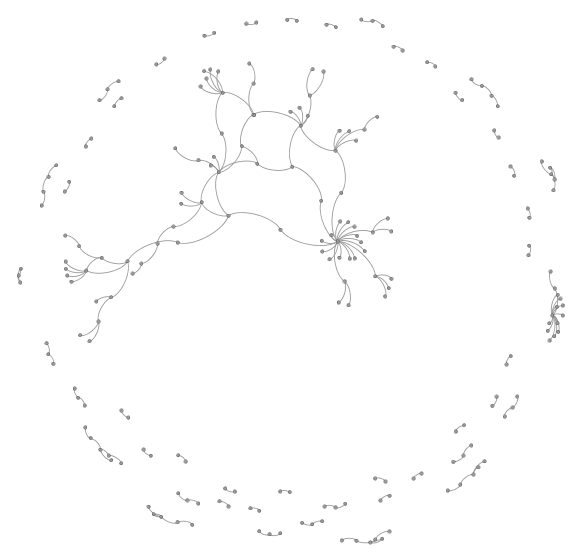
Internal links for entries posted in 2014
Now I’m curious about what happens when we add the posts and links from 2013 and 2012, too. I’ve colour-coded this by year, with It ties together posts on sketchnoting, blogging, choice, learning, writing, plans… Neat.
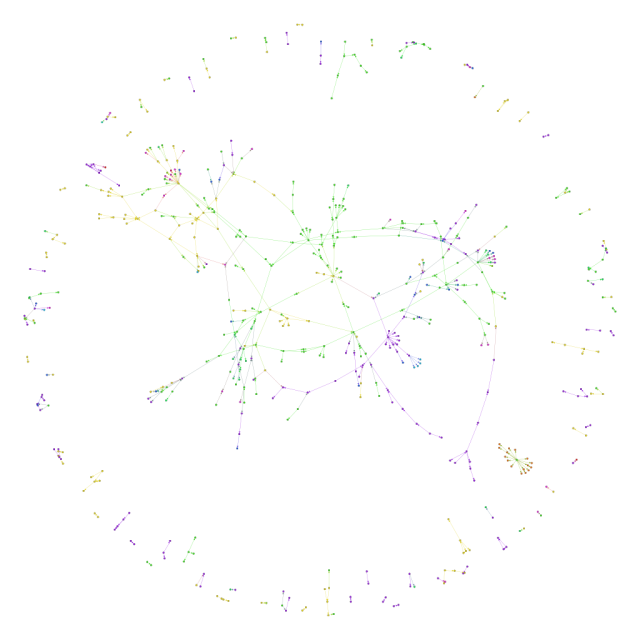
What does this say? It says that even though I write about lots of different things, there are connections between the different topics, and the biggest tangle in the middle has more than 320 nodes. I have lots of blog posts that build on an idea for three or four posts, sometimes spanning several years, even if I don’t think about it in advance. There are 90 such clumps, and it might be good to revisit some of these 2- and 3-post chains to see if I can link them up even further.
Also, it could be interesting to do this analysis with tags, not just year. Hmm… Also, I should dust off my data structures and algorithms, and make my own connected-component analyzer so that I can get a list of the clumps of topics. Good ideas to save for another day!