Adding subheadings and sketches to my blog page navigation
Posted: - Modified: | 11ty, blogging: Fixed link to onThisPage.cjs. Thanks to John Rakestraw for pointing it out!
Assumed audience:
- My future self, when I'm trying to figure out where to change things if I want to implement something similar
- People who like tweaking their blog's CSS, especially if they also use Org Mode or 11ty
Headings help us make sense of longer blog posts. Heading links are like signposts letting you know what's ahead and where you can take a shortcut to get to what you're interested in.
Headings are useful for me too. Sometimes I browse my blog and come across things I've completely forgotten writing about, so the headings can help me remember without having to reread long posts. If I use headings more often, I might be able to work with bigger chunks of thoughts. If I can work with bigger chunks of thoughts, then maybe I can think about more things that are hard to fit within the limits of my working memory. Making headings more navigable also means I might not have to worry about the tangents I go on and the number of different thoughts I try to smoosh together, if people can jump straight to the parts that sound relevant to them.
I particularly like the way Karthik uses a sticky table of contents for long blog posts like The Emacs Window Management Almanac | Karthinks. I also like the way the Read the Docs Sphinx Theme displays a nested table of contents on the left side on wide screens. I use org-html-themes to export Org Mode files with that theme when I want to be fancy, like my Emacs configuration (usually works, although sometimes my config is broken).
The last time I tinkered with my webpage margins, I put my "On this page" list on the left side and the blog post headings (if any) on the right side, mostly because it was easy to do. I just changed the margin and float attributes of the element with the subheadings. I'd like to clear up more space for potential sidenotes or doodles, though. This time, I experimented with nesting the blog navigation inside the "On this page" navigation on the left side.
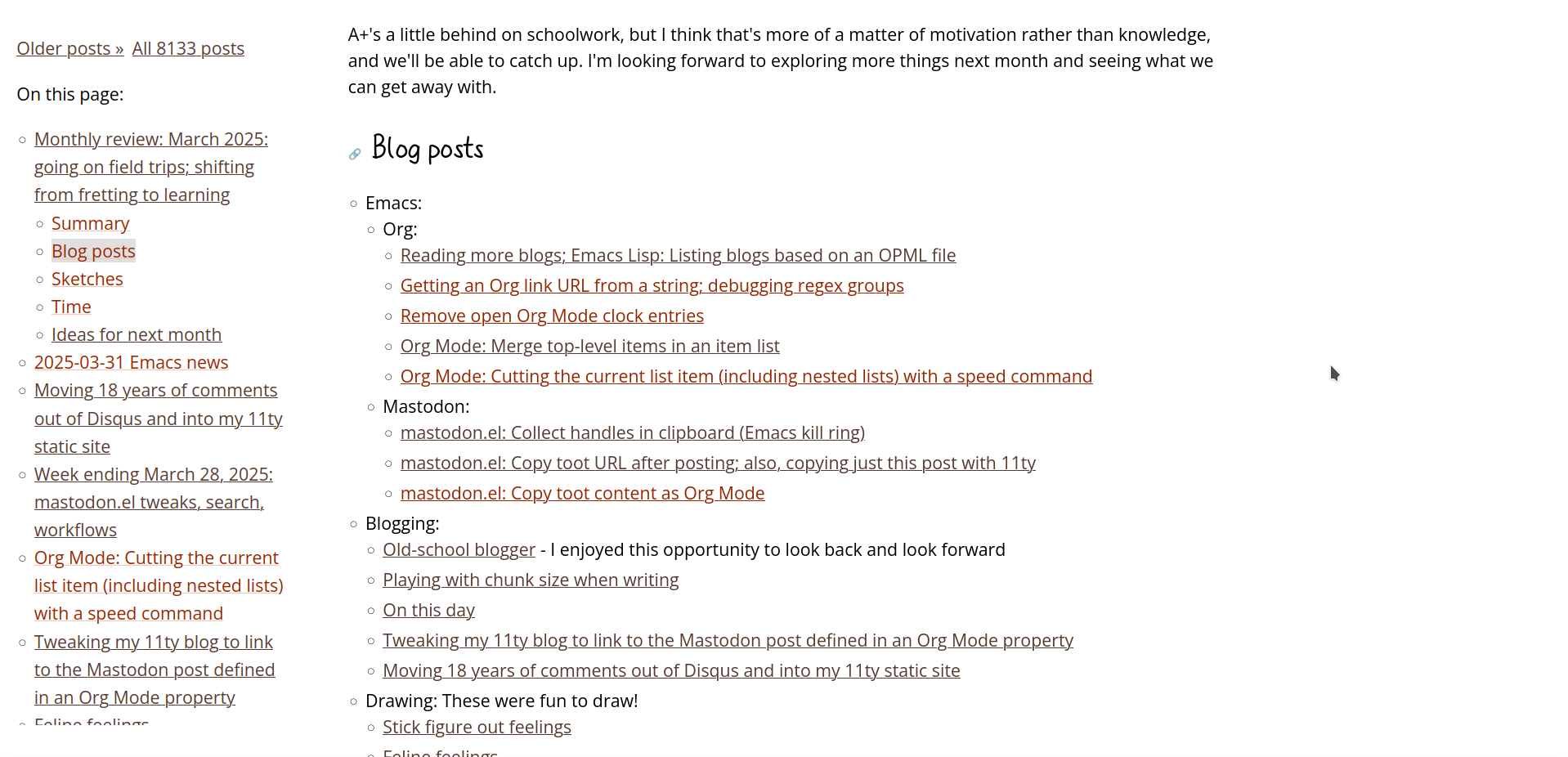
Here's how I did it:
I can use a sketch as a map, too
I sometimes want to use sketchnotes as overviews, especially if I've added hyperlinks to them. I used to make the images show up on the right side, but now I want them to show up in the left-side navigation instead. Also, I wanted any links to headings to automatically get recoloured as I scroll to that heading.

I added a special case to the
handleActiveTOCLink function to handle anchor
hyperlinks (just #anchor) in the SVG. It
probably makes sense to make those absolute URLs,
which means slightly changing my workflows for
hyperlinking SVGs and writing about sketches.
So on both the category page (ex: the Hyperlinking
SVGs entry in category - drawing, which might have
moved off the first page of results if you're
reading this far in the future) and the
single-post page (ex: Hyperlinking SVGs), there's
a full-sized version of the image in the main blog
post, and then a small copy of it in the margin on
the left. The sidebar copy is probably too small
to read, but it might be enough to get a sense of
spatial relationships, and the links also have
title attributes that are displayed as tooltips
when you hover.
I use Javascript to duplicate the image and make a small, sticky version because I haven't quite figured out how to properly make it sticky when off-screen with just CSS. Even my JS feels a little tangled. Maybe this would be a good excuse to learn about web components; someone's probably figured out something polished.
I'm curious about using more drawings to anchor my thinking and structure my blog posts.


