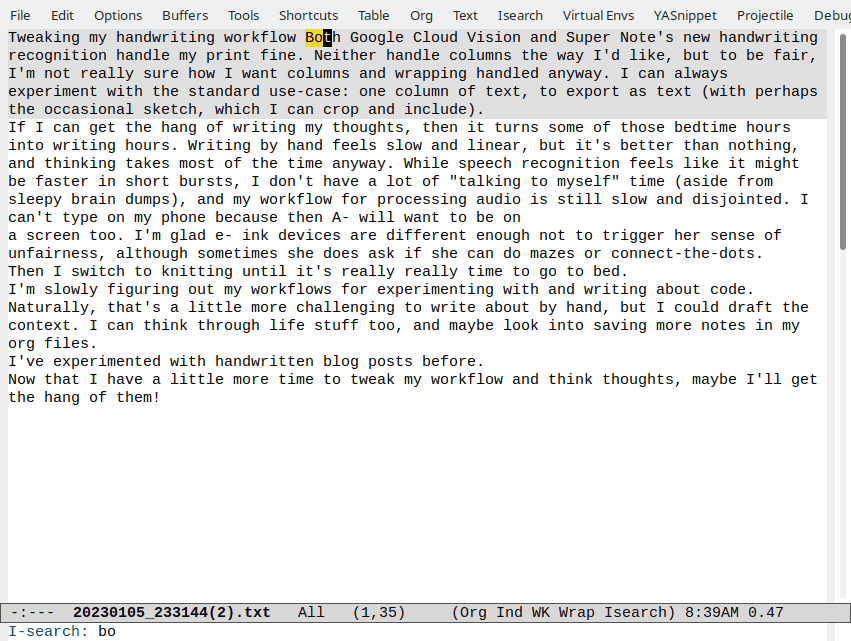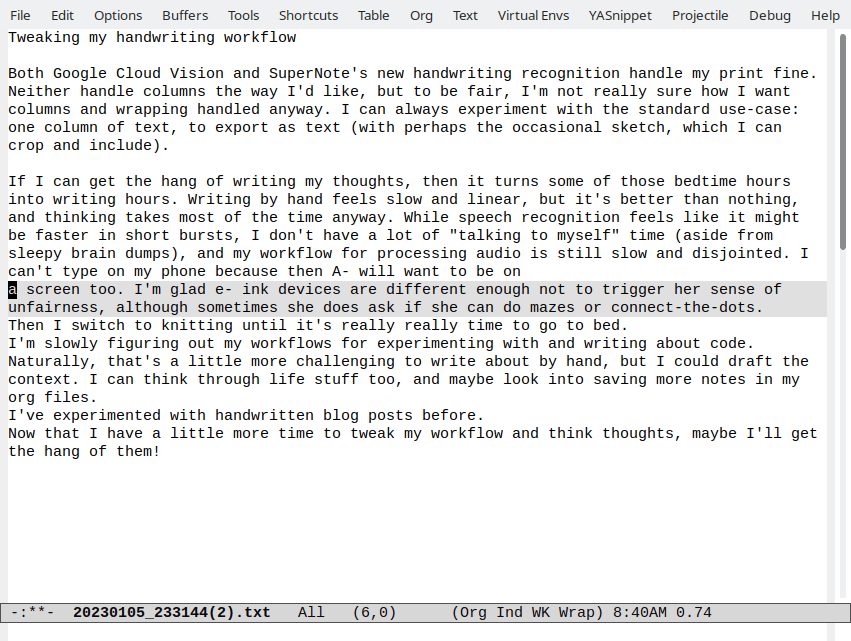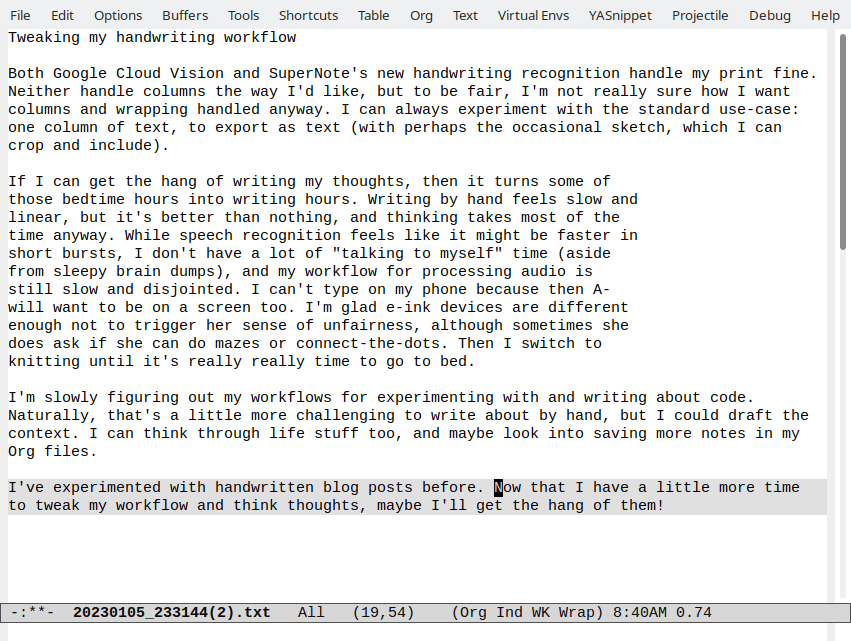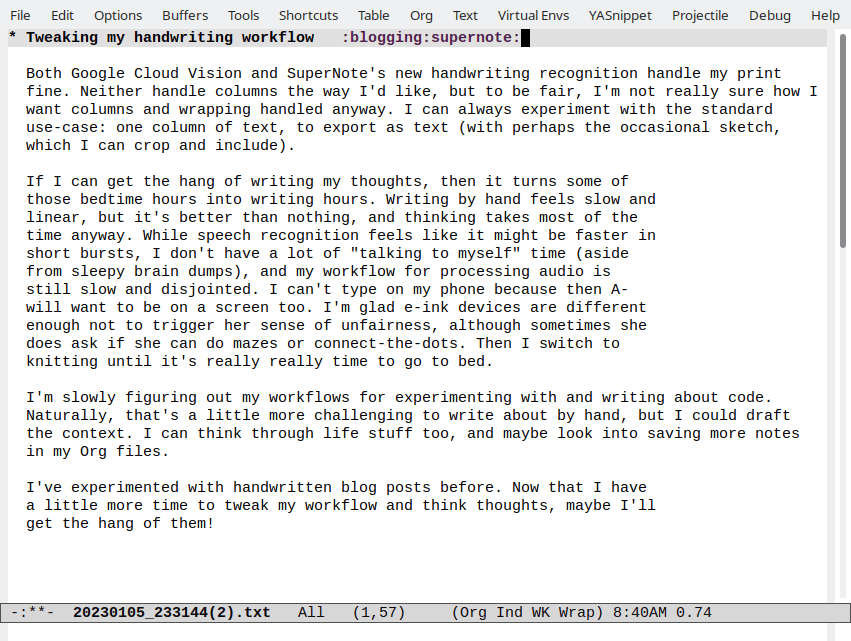
Adding an XSL stylesheet for my RSS and Atom feeds
| 11ty, geek, bloggingInspired by the styling on Susam's blog feed, I followed this tutorial on using XML stylesheets and added XSL stylesheets for my RSS and Atom feeds. I have RSS and Atom feeds for all my posts as well as for each category or tag (ex: emacs).

To make that happen, I added a line like this to my RSS template:
<?xml-stylesheet href="/assets/rss.xsl" type="text/xsl"?>
and for my Atom template:
<?xml-stylesheet href="/assets/atom.xsl" type="text/xsl"?>
and those refer to:
rss.xsl
<?xml version="1.0" encoding="utf-8"?> <xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:atom="http://www.w3.org/2005/Atom"> <xsl:output method="html" version="1.0" encoding="UTF-8" indent="yes"/> <xsl:template match="/"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en"> <head> <title> RSS Feed | <xsl:value-of select="/rss/channel/title"/> </title> <link rel="stylesheet" href="/assets/style.css"/> </head> <body> <h1 style="margin-bottom:0">Recent posts: <xsl:value-of select="/rss/channel/title"/></h1> <p> This is an RSS feed. You can subscribe to <a href=" {/rss/channel/link}"><xsl:value-of select="/rss/channel/link"/></a> in a feed reader such as <a href="https://github.com/skeeto/elfeed">Elfeed</a> for Emacs, <a href="https://www.inoreader.com/">Inoreader</a>, or <a href="https://newsblur.com/">NewsBlur</a>, or you can use tools like <a href="https://github.com/rss2email/rss2email">rss2email</a>. The feed includes the full blog posts. You can also view the posts on the website at <a href="{/rss/channel/atom:link[contains(@rel,'alternate')]/@href}"><xsl:value-of select="/rss/channel/atom:link[contains(@rel,'alternate')]/@href" /></a> . </p> <xsl:for-each select="/rss/channel/item"> <div style="margin-bottom:20px"> <div> <xsl:value-of select="pubDate" /> </div> <div> <a> <xsl:attribute name="href"> <xsl:value-of select="link/@href"/> </xsl:attribute> <xsl:value-of select="title"/> </a></div></div> </xsl:for-each> </body> </html> </xsl:template> </xsl:stylesheet>
atom.xsl
<?xml version="1.0" encoding="utf-8"?> <xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:atom="http://www.w3.org/2005/Atom"> <xsl:output method="html" version="1.0" encoding="UTF-8" indent="yes"/> <xsl:template match="/"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en"> <head> <title> Atom Feed | <xsl:value-of select="/atom:feed/atom:title"/> </title> <link rel="stylesheet" href="/assets/style.css"/> </head> <body> <h1 style="margin-bottom:0">Recent posts: <xsl:value-of select="/atom:feed/atom:title"/></h1> <p> This is an Atom feed. You can subscribe to <a href=" {/atom:feed/atom:link/@href}"><xsl:value-of select="/atom:feed/atom:link/@href"/></a> in a feed reader such as <a href="https://github.com/skeeto/elfeed">Elfeed</a> for Emacs, <a href="https://www.inoreader.com/">Inoreader</a>, or <a href="https://newsblur.com/">NewsBlur</a>, or you can use tools like <a href="https://github.com/rss2email/rss2email">rss2email</a>. The feed includes the full blog posts. You can also view the posts on the website at <a href="{/atom:feed/atom:link[contains(@rel,'alternate')]/@href}"><xsl:value-of select="/atom:feed/atom:link[contains(@rel,'alternate')]/@href" /></a> . </p> <xsl:for-each select="/atom:feed/atom:entry"> <div style="margin-bottom:20px"> <div> <xsl:value-of select="substring(atom:updated, 0, 11)" /></div> <div><a> <xsl:attribute name="href"> <xsl:value-of select="atom:link/@href"/> </xsl:attribute> <xsl:value-of select="atom:title"/> </a></div></div> </xsl:for-each> </body> </html> </xsl:template> </xsl:stylesheet>
View or add comments (Disqus), or e-mail me at sacha@sachachua.com