0:00 Getting set up with Zoom, chatting
Sacha: Recorded. There you go. Fantastic. Karthik was just telling me that you and Karthik have been having cozy chats on Discord about all the cool things you've been doing on the road. John: That's right. Sacha: Here we are. Karthik: Okay. Hi, John. John: Hey there, Karthik. Sacha: Okay, I'm going to figure this out. There's probably a gallery view that I can use to show everybody on screen. Sorry, Zoom is— John: That little nine-boxes icon in the upper right should give you that option. Sacha: Nine boxes. I'm not seeing it. Nine boxes. John: Oh, you might be on a Linux machine. I don't know how it works. Karthik: It says "view." For me, it's a button on the top right that says "view." Sacha: I'm just on the little screen and I'm in the web browser, so I don't see it. But I'm going to leave and I'll come right back. John: Okay. It's been a while since we've seen each other in person, Karthik. How's the new job? Karthik: Oh, it's busy. It's getting busier and busier. Just managing this two hours in the afternoon today was quite a deal. John: Oh, I'm sorry to have been late. I did not mean to. Karthik: Oh, no, no, it's fine. I'm glad we can finally capture your amazeballs Org setup. John: We'll see what we can cover. Karthik: So yeah, roughly speaking, I want to spend half an hour where you just show the various things you do with Org and how you use it to track your life. The other half hour, I'm going to badger you with philosophical questions about what it means to track your life. John: Okay, that sounds fair. Karthik: Right? Where Org will be a participant but not the focus. That's kind of my plan, but I'm going to let Sacha take it away because she's the consummate interviewer here. I will pipe in with questions. That's the plan. Okay, can we check if you can share your screen, your Emacs window, because I imagine we'll be seeing that a lot. Let me see here. My Emacs window. Okay. 2:34 Increasing font size globally with C-x C-M-=
Karthik:
John, could you increase the font size by a little bit? Because I'm imagining people watching this on YouTube. I'm going to end up having to do that a lot. John: I don't know how to do it globally. Karthik: I can tell you. Get your fingers warmed up because it's C-x C-M-=. John: Yeah. Sacha: And then—okay. Yes, all right. John: Wow, look at that. Karthik: And then you can just keep pressing equals to keep increasing it. John: So which size? Is this size good? Karthik: Yeah, this size. Sacha, do you think this is big enough? Sacha: It looks great. It looks fine to me. Let's give it a try. John: It's going to be a lot of text to blur out, Karthik. Sacha: Do you want it bigger? Karthik: I can draw big windows in the video editor. 3:47 Redacting information when sharing Org demos
Sacha: I guess someday we will fix this with some kind of redaction global minor mode that just replaces everything with plausible-sounding text. I have something like that locally—it just replaces email addresses and phone numbers and stuff. But yes. John: I wonder if Sora could do that actually to the whole video. Karthik: You would be sharing all your data. John: Oh, that's true. Never mind. Sacha: One thing that we were talking about before is you could also consider sharing the transcript and then either screenshots or short clips, because that way we can just focus on the parts that demonstrate the workflow that you've developed without necessarily having to edit every single frame to make sure that everything is always covered. John: Sure. Yes. 4:41 Daily Org Mode workflow for handling 40,000 entries
Sacha: So thank you for joining me and Karthik. I'm looking forward to finding out about all the cool things that you've been developing in your Org-mode workflow over the past two years since our last conversation about Org and personal information management. So what does your daily Org workflow look like now? John: I've actually evolved several different tools on top of Org-mode itself. Now that we're in 2026, I have just under 40,000 Org-mode entries in my system. About 9,700 of those are tasks, and right now there are something like 1,200 of those tasks that are open. So my whole system is meant now to help me pay attention to what I need to pay attention to, because there's too much information. I could never, even if I wanted to, review it all or even just browse through it all. So Org-mode has to be the one to really condense everything into lists that are appropriate for when I'm working and what I'm working on. That's kind of the object of all the different things that I have: how do I make use of this sea of data? And I'm sure there's a whole bunch of stuff in my life that isn't even captured yet. That's the real rub here— despite this complexity, it's not that there's too much complexity, it's that there's not even enough yet. There are still things that live only in my mind, and as much as I can, I try to move them from my mind into Org-mode. But then I need to have Org-mode show it to me when I need to see it. Otherwise, it's no better than my memory. 6:24 Outlines for Focus and Home
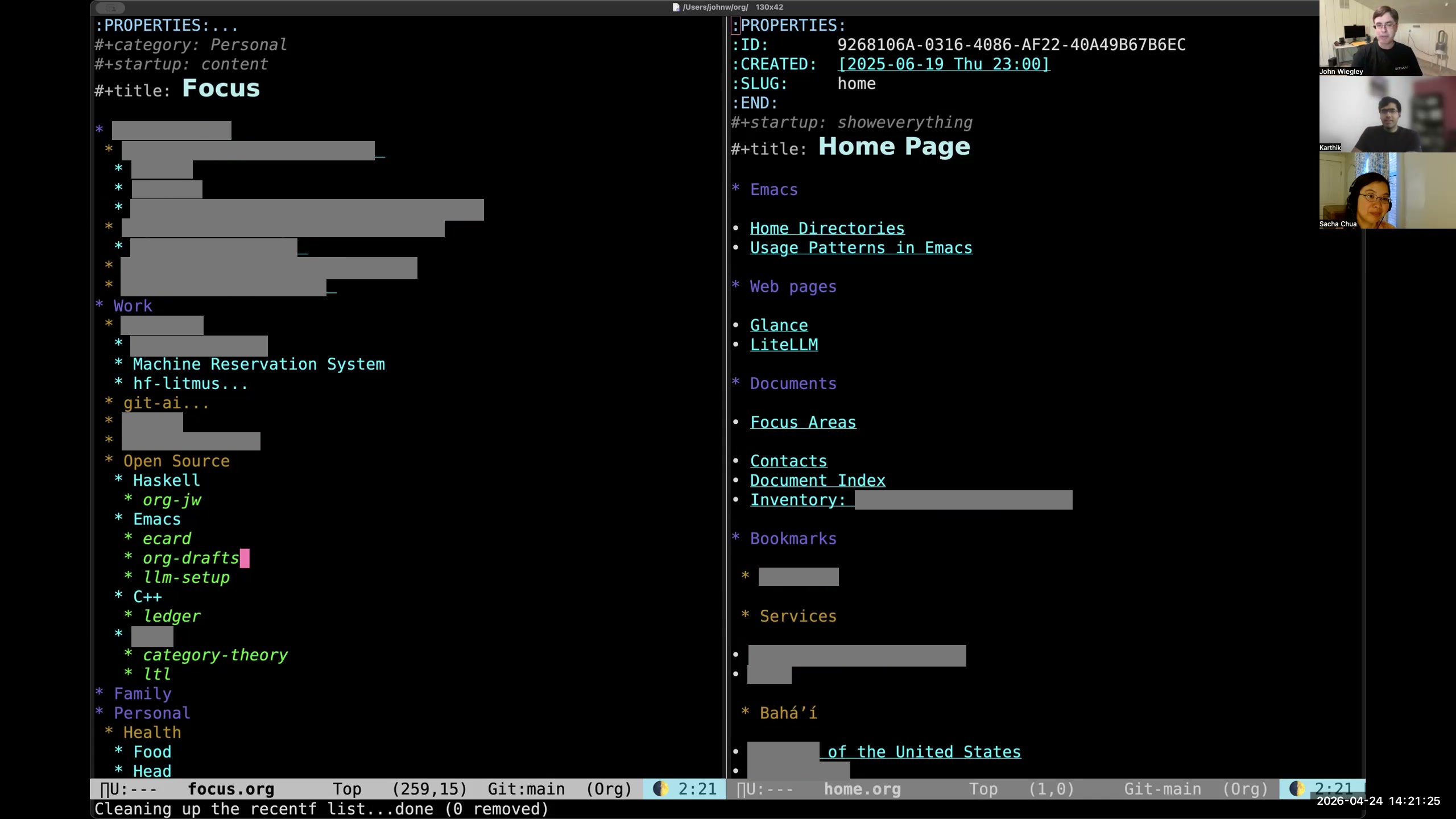 John: When I first go into Emacs, I always see these two pages. I use Org-roam on top of Org-mode in order to move tasks and notes into separate Org-mode files and have those be interlinked and organized well. I interlink everything by ID, which is sort of an Org-roam philosophy, and I've taken that on. I come into the focus page on the left, which is all of the stuff that I want to focus on project-wise right now. Every heading should either be a link to the project that the focus is about, or if I go ahead and look at the body of one of these entries, it will be a column view that pulls in a report— basically an embedded report for that category. I use categories a lot, and I use projects a lot, where projects are hierarchies that contain tasks, and categories are just names that might cut across many, many tasks. I also use tags, but tags are a whole separate thing that doesn't have to do with this.
John: When I first go into Emacs, I always see these two pages. I use Org-roam on top of Org-mode in order to move tasks and notes into separate Org-mode files and have those be interlinked and organized well. I interlink everything by ID, which is sort of an Org-roam philosophy, and I've taken that on. I come into the focus page on the left, which is all of the stuff that I want to focus on project-wise right now. Every heading should either be a link to the project that the focus is about, or if I go ahead and look at the body of one of these entries, it will be a column view that pulls in a report— basically an embedded report for that category. I use categories a lot, and I use projects a lot, where projects are hierarchies that contain tasks, and categories are just names that might cut across many, many tasks. I also use tags, but tags are a whole separate thing that doesn't have to do with this. 7:34 Column view
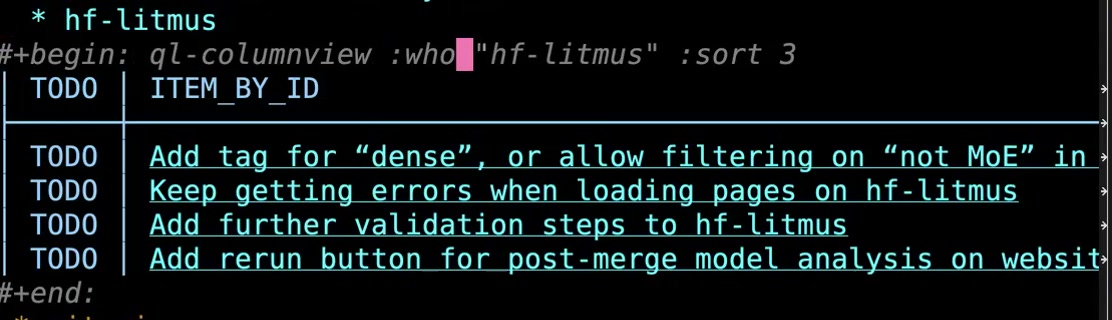 John: So anyway, you can see here a column view— this is a special version of column view. It's based on org-ql in order for it to be fast enough, but this column view doesn't exist out in the wild. This is in my own private dot-emacs repository. I wrote an org-ql column view function. Of course, it's very customized to my data format, but I have a
John: So anyway, you can see here a column view— this is a special version of column view. It's based on org-ql in order for it to be fast enough, but this column view doesn't exist out in the wild. This is in my own private dot-emacs repository. I wrote an org-ql column view function. Of course, it's very customized to my data format, but I have a :who field, and if you put a word here, that means if this shows up as either a category or a tag, then include that item in the report. Then I want it to sort by column three, and column three here ends up being the tags. That way I can see things sorted by tag. Anyway, each of these is linked to the corresponding issue by identity. So if I just do C-c C-o, then it will take me over to that item in that Org-mode file—that Org-roam file, sorry. So that's the purpose of the focus file: I can have a 10,000-foot overview of what I'm currently working on and what I want to focus on. 8:44 Home is a collection of links
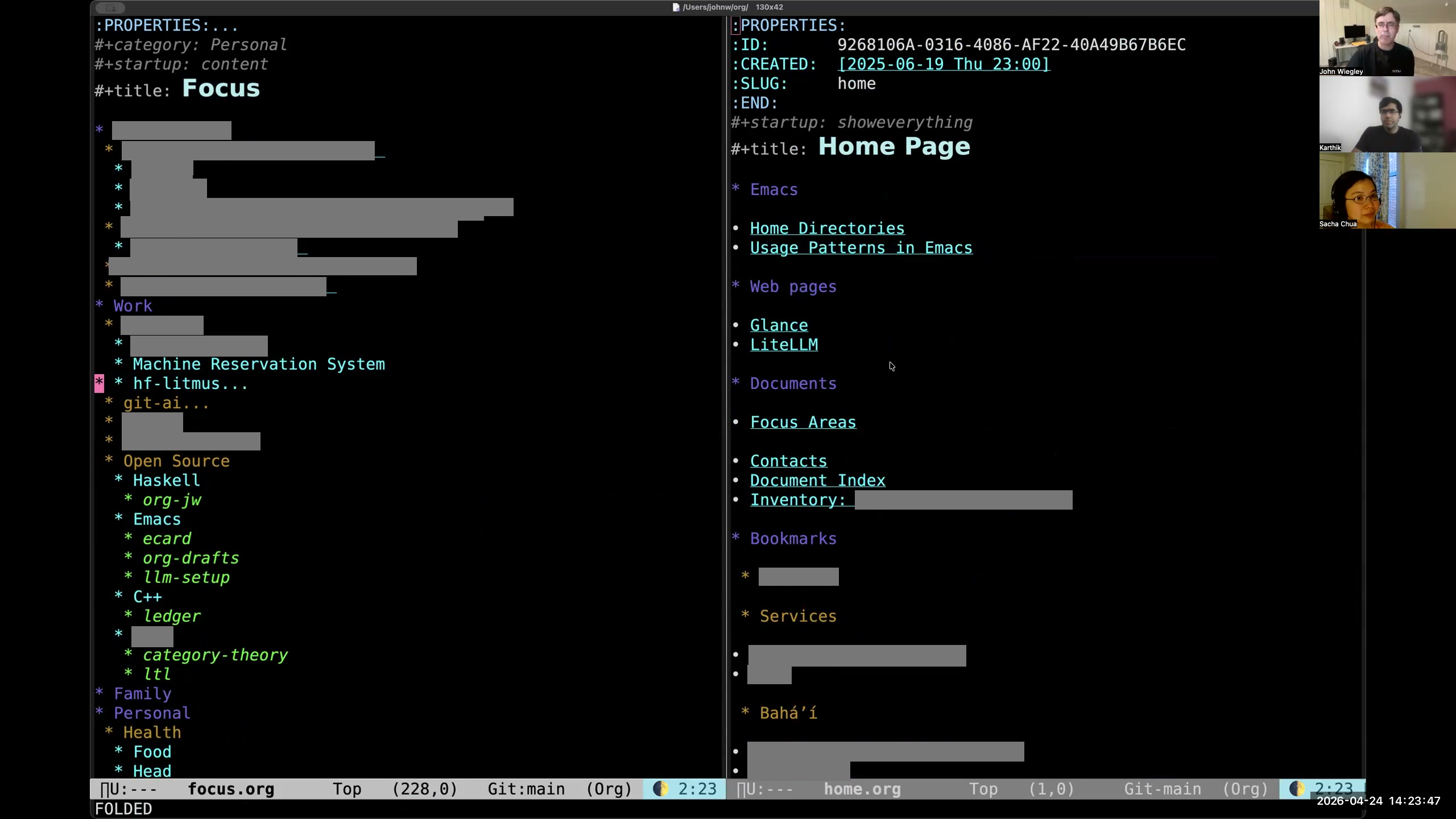 John: Then on the right is the homepage. This homepage basically is a collection of links, kind of like Linux utilities such as Glances or Cockpit— something that allows you to have one page that you jump to all kinds of different things from. This is my jumping-off page to a bunch of other pages that themselves serve as indexes within my Org-mode/Org-roam repository. This way I don't have to remember, "Oh yeah, how did I get to such-and-such a project?" I can just look in—it's a bookmarks list, but it's a meta-bookmarks list.
John: Then on the right is the homepage. This homepage basically is a collection of links, kind of like Linux utilities such as Glances or Cockpit— something that allows you to have one page that you jump to all kinds of different things from. This is my jumping-off page to a bunch of other pages that themselves serve as indexes within my Org-mode/Org-roam repository. This way I don't have to remember, "Oh yeah, how did I get to such-and-such a project?" I can just look in—it's a bookmarks list, but it's a meta-bookmarks list. 9:22 C-c C-o opens one or all links in the Org Mode entry
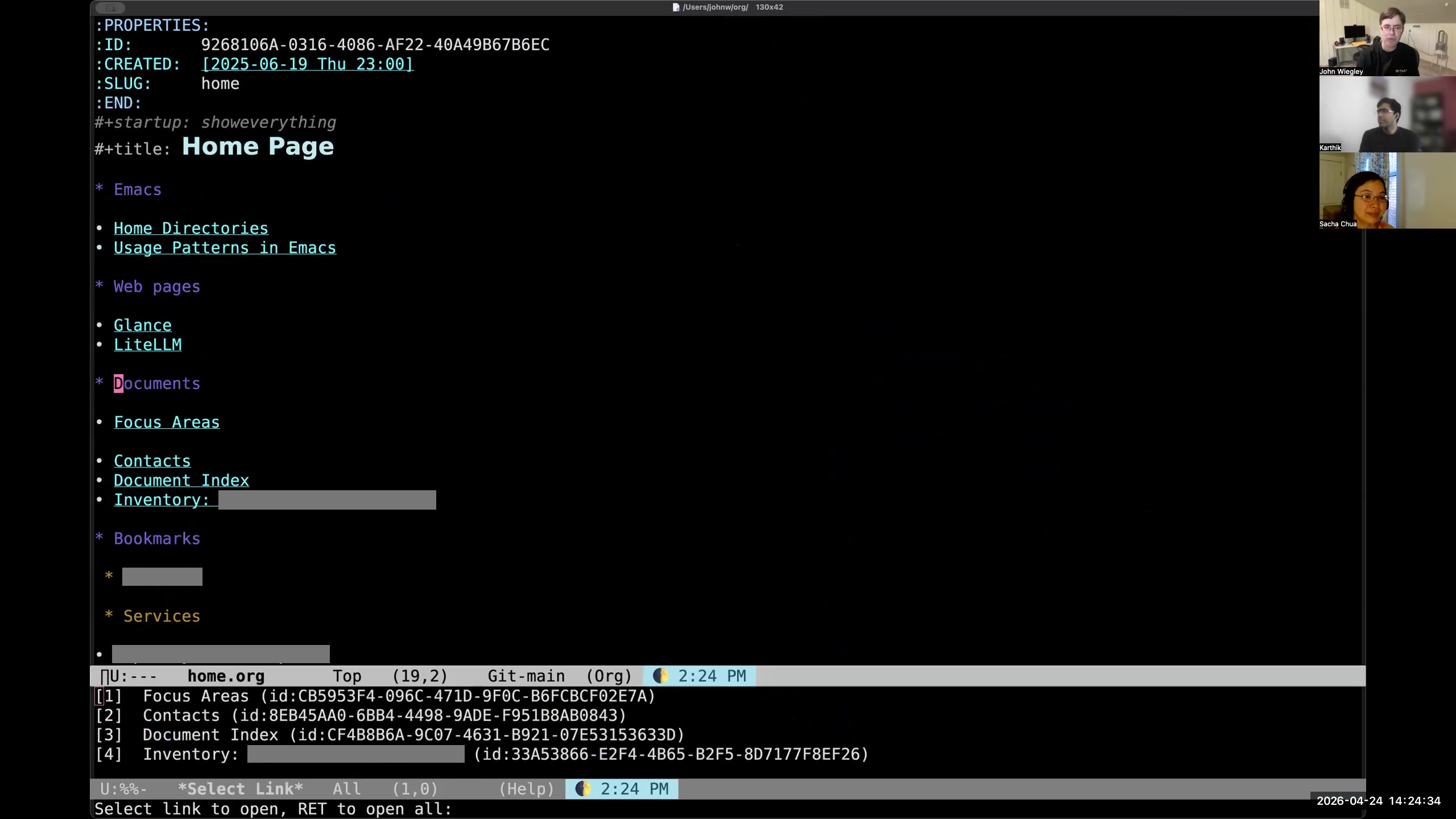 John: The other nice thing about Org-mode is that if you're on an entry that has links inside the entry like this one does, and you do C-c C-o, it'll show you all of the links, and then you can hit return to open them all.
John: The other nice thing about Org-mode is that if you're on an entry that has links inside the entry like this one does, and you do C-c C-o, it'll show you all of the links, and then you can hit return to open them all. 9:38 Example: Claude settings.json on multiple machines
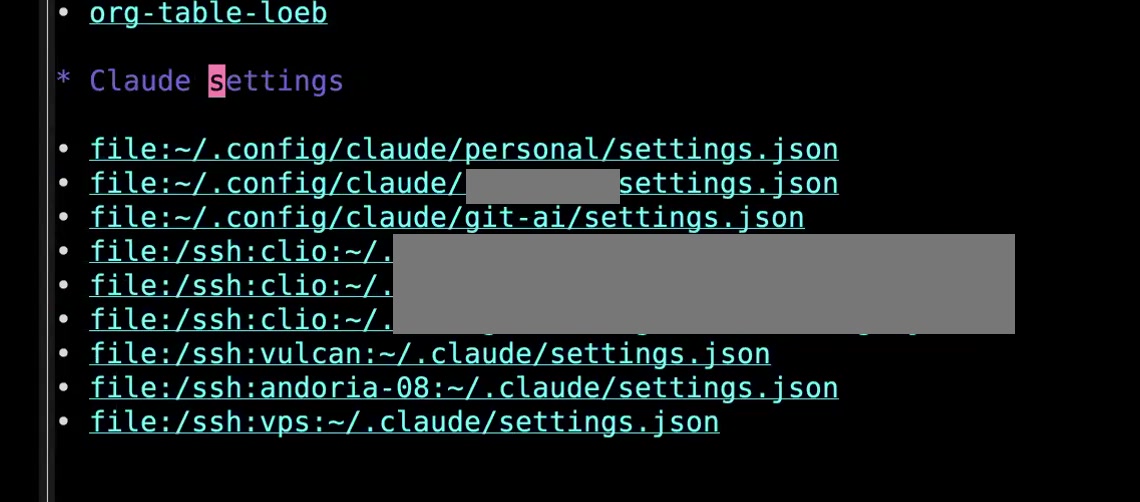 John: This way, what I do in the homepage is, I have a whole bunch of settings files for Claude because I use Claude in a lot of different places. I have different accounts and I have different machines and different accounts on those machines. Sometimes I need to make an edit to every single one of those files but I don't want to have to remember how to open up each one. Even an Emacs bookmark wouldn't be quick enough, but if I have the whole list of links as I do here in my Org-mode file, then I can just C-c C-o RET and it will open all of these in my browser at once. I do this a lot to open sets of pages when I need to do bulk editing in the browser or even in Emacs because, as you know, with the right add-ons, Org-mode links can be empowered to open all kinds of different things. I have Org-mode links that jump to Magit status pages for different projects in Git. I have ones that open dired buffers. I have ones that open Gnus, all kinds of different apps. I navigate to these through Org-mode links. In this way, Org-mode becomes the master dashboard of my information ecology. Yeah, so... go ahead. Sacha: No, no. So to recapitulate: instead of using a gazillion agendas where you have to remember the keystrokes to open each custom agenda, you use Org-mode outlines in your focus and your homepage that have links to or reports for the different things that you're focusing on. John: Yes, but not instead of. I also use tons of Org-mode agenda links as well. But Org-mode agenda links have a very specific focus. Usually when I start the day, when I start Emacs, I come to these two pages. I've set it up so that after startup, it always shows me these two pages. But usually the first thing I do is hit
John: This way, what I do in the homepage is, I have a whole bunch of settings files for Claude because I use Claude in a lot of different places. I have different accounts and I have different machines and different accounts on those machines. Sometimes I need to make an edit to every single one of those files but I don't want to have to remember how to open up each one. Even an Emacs bookmark wouldn't be quick enough, but if I have the whole list of links as I do here in my Org-mode file, then I can just C-c C-o RET and it will open all of these in my browser at once. I do this a lot to open sets of pages when I need to do bulk editing in the browser or even in Emacs because, as you know, with the right add-ons, Org-mode links can be empowered to open all kinds of different things. I have Org-mode links that jump to Magit status pages for different projects in Git. I have ones that open dired buffers. I have ones that open Gnus, all kinds of different apps. I navigate to these through Org-mode links. In this way, Org-mode becomes the master dashboard of my information ecology. Yeah, so... go ahead. Sacha: No, no. So to recapitulate: instead of using a gazillion agendas where you have to remember the keystrokes to open each custom agenda, you use Org-mode outlines in your focus and your homepage that have links to or reports for the different things that you're focusing on. John: Yes, but not instead of. I also use tons of Org-mode agenda links as well. But Org-mode agenda links have a very specific focus. Usually when I start the day, when I start Emacs, I come to these two pages. I've set it up so that after startup, it always shows me these two pages. But usually the first thing I do is hit C-c a a to go to my agenda for today. 11:41 org-super-agenda is divided into topical categories
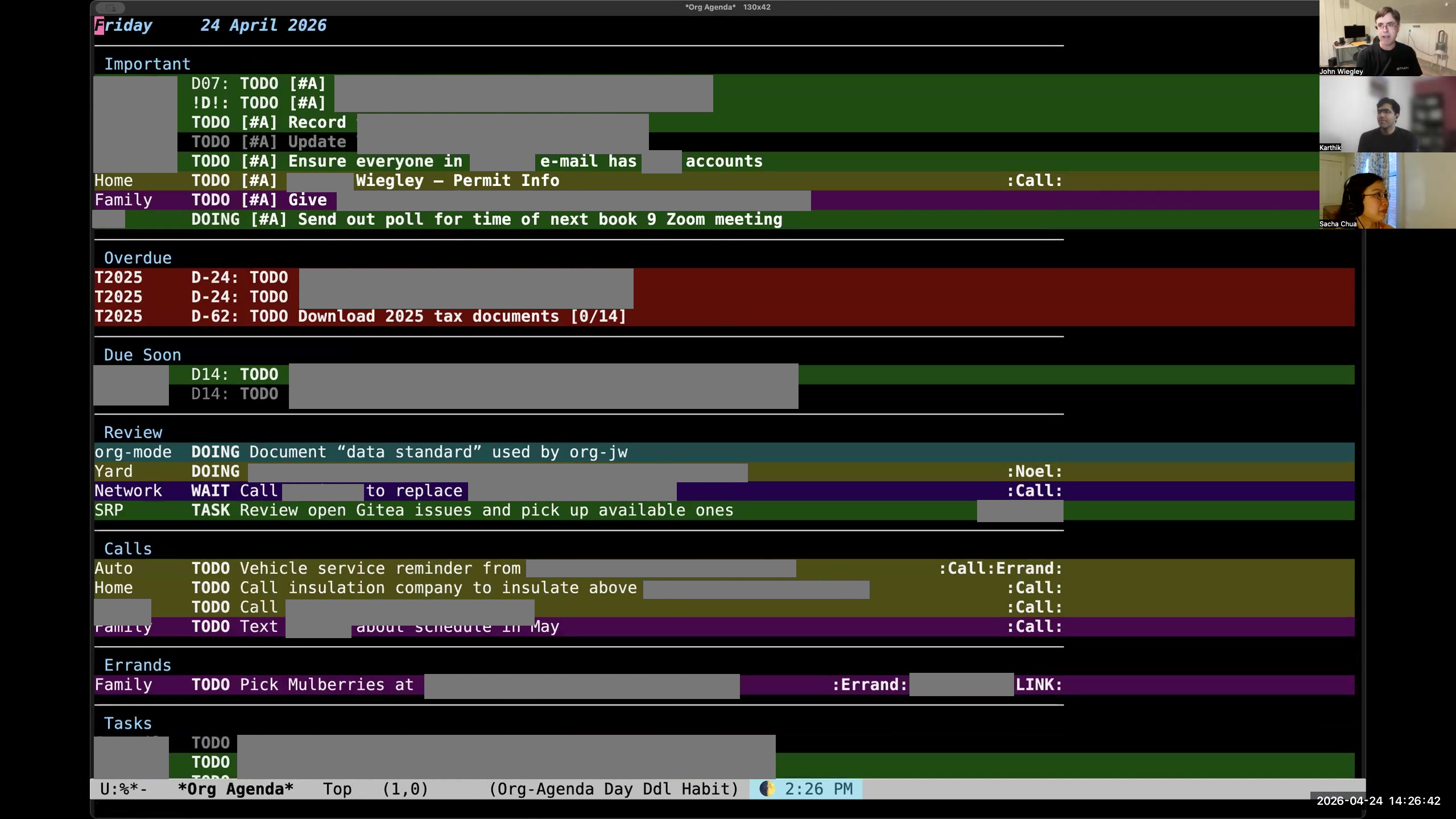 John: I use org-super-agenda to divide this into categories— not category categories, but topical categories— so that I can see things segregated by which are the high-priority items, which are the things that are currently in progress, and then if they have a context where they need to happen (phone calls, errands, blah blah blah), then I see them all. This is just one of the agenda reports I use; this is the daily report. If I look at my agenda here, you can see I have the standard agenda reports, but then I have subcategories. I have a whole set of org-ql-powered agenda queries. If I look at these, I can look at all my open-source tasks, all my work tasks. Sacha: Your screen is shifted sideways for me. I'm not really sure. Karthik: Same here. So it's a little bit on the left. You may need to reshare your screen. John: That's weird. I've never seen that happen before. Sacha: So you've got your agenda. John: I'm sharing a process window. Sacha: Okay, here we are. Yes, I see it now. Okay, so these are the other things you've got.
John: I use org-super-agenda to divide this into categories— not category categories, but topical categories— so that I can see things segregated by which are the high-priority items, which are the things that are currently in progress, and then if they have a context where they need to happen (phone calls, errands, blah blah blah), then I see them all. This is just one of the agenda reports I use; this is the daily report. If I look at my agenda here, you can see I have the standard agenda reports, but then I have subcategories. I have a whole set of org-ql-powered agenda queries. If I look at these, I can look at all my open-source tasks, all my work tasks. Sacha: Your screen is shifted sideways for me. I'm not really sure. Karthik: Same here. So it's a little bit on the left. You may need to reshare your screen. John: That's weird. I've never seen that happen before. Sacha: So you've got your agenda. John: I'm sharing a process window. Sacha: Okay, here we are. Yes, I see it now. Okay, so these are the other things you've got. 12:54 Org-ql filters tasks
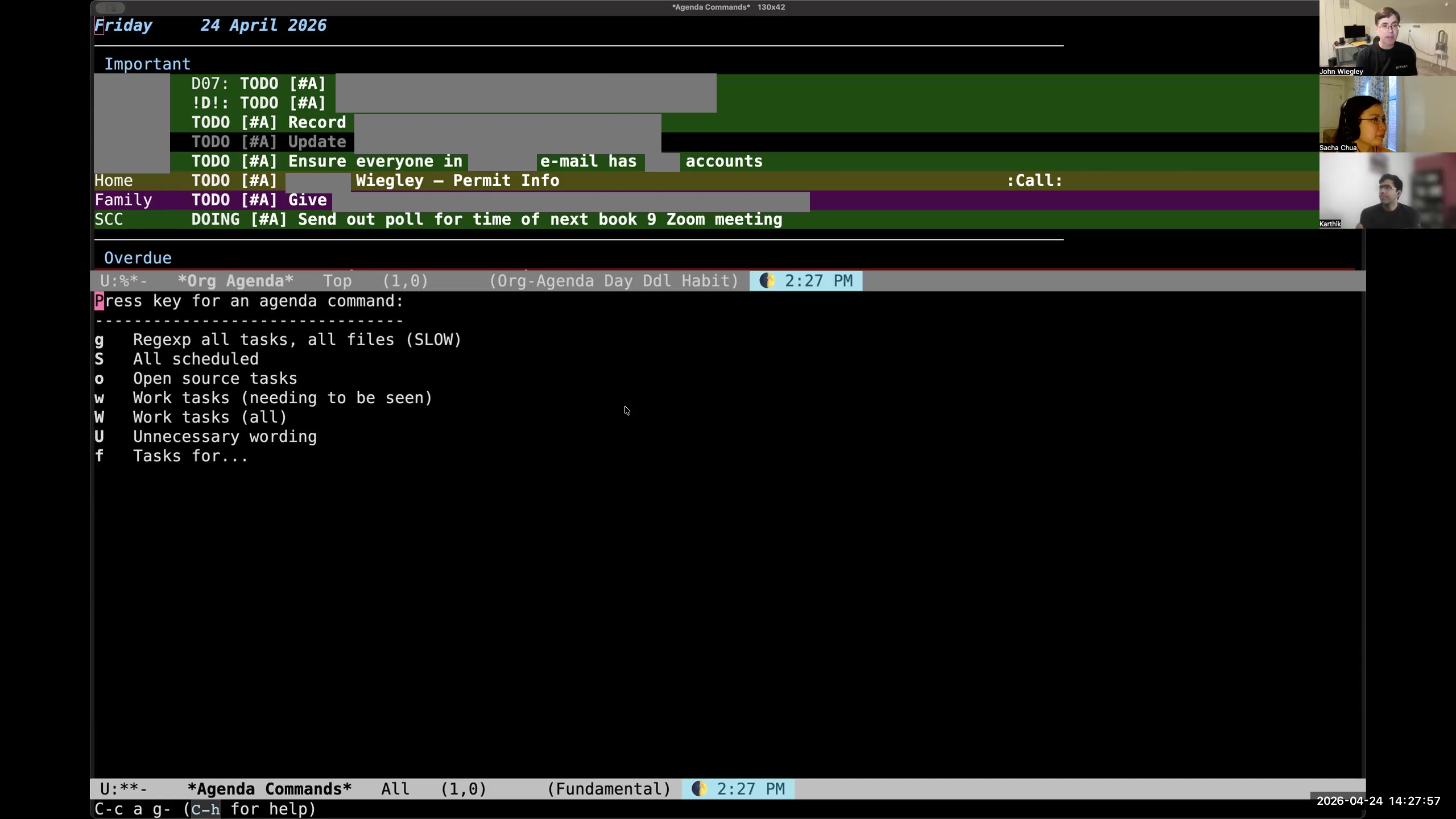 John: These are basically queries that I have created for org-ql, and then the tasks-for that mirrors that org-ql column view "who tag" where I can give something that will match either a category or a tag,
John: These are basically queries that I have created for org-ql, and then the tasks-for that mirrors that org-ql column view "who tag" where I can give something that will match either a category or a tag,  John: and it will show me here in the org-agenda report the same information it would have shown in that org-ql column view report.
John: and it will show me here in the org-agenda report the same information it would have shown in that org-ql column view report. 13:20 Other agenda reports help review tasks
 John: I also have different reports in the agenda for reviewing my tasks, and I'll have to come back to that because that's a big part of this whole process as well.
John: I also have different reports in the agenda for reviewing my tasks, and I'll have to come back to that because that's a big part of this whole process as well. 13:29 Custom reports identify things that need to be filed
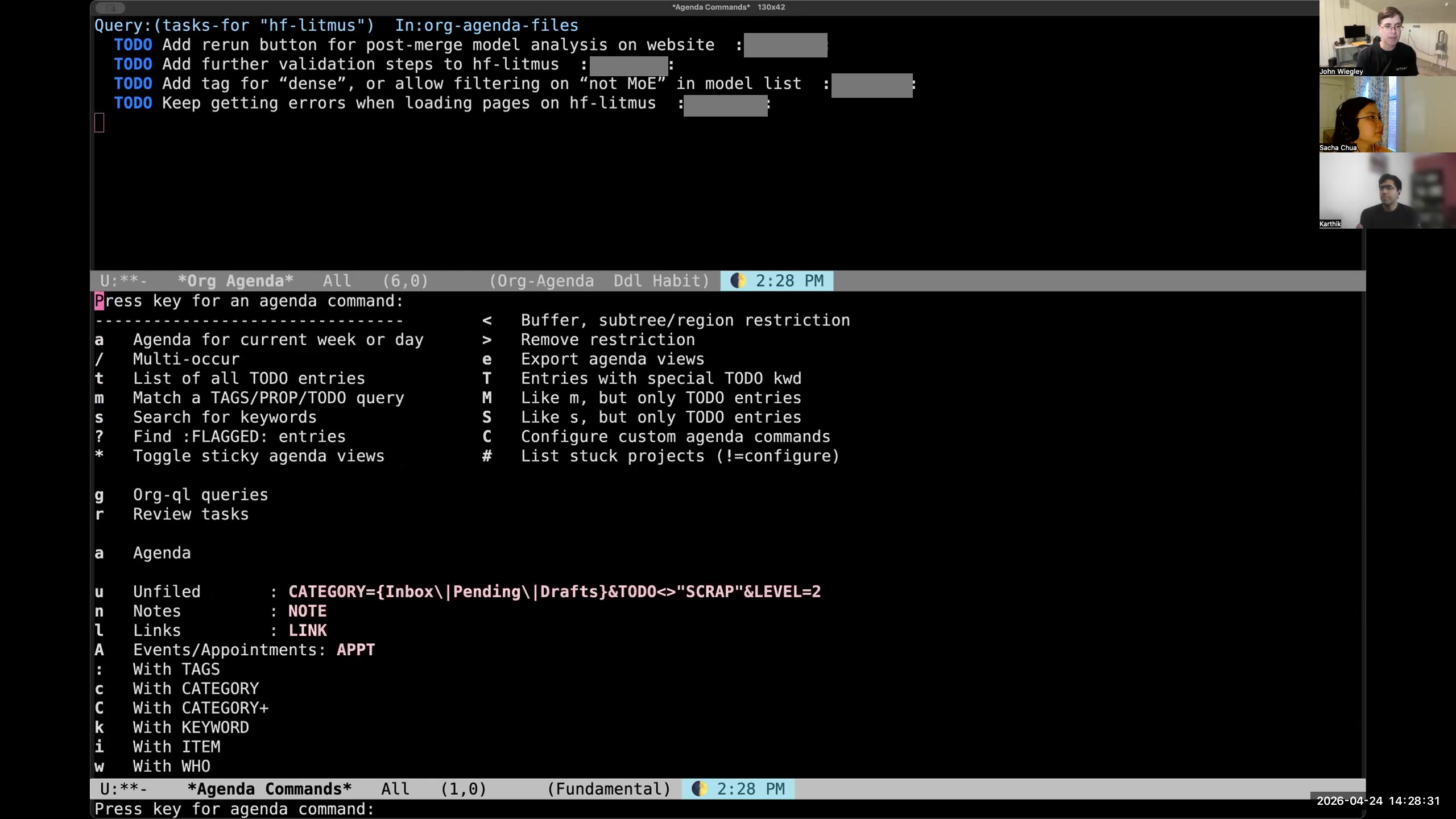 John: Then at the bottom, you can see I have other custom reports for seeing things that haven't been filed— they're in my inbox, they need to be filed away.
John: Then at the bottom, you can see I have other custom reports for seeing things that haven't been filed— they're in my inbox, they need to be filed away. 13:37 I keep files in a flat directory and use search instead of categorizing files
John: I do like to file tasks in the file system. I've lost the battle of introducing any kind of structure because I just have too many files. My database on functional programming alone now has over 10,000 PDFs in it. I just can't categorize those. So they're all in one flat directory, and I search for them by using AI and by keyword search, because that's all I really can do. But for Org-mode, I haven't given up on having a hierarchy to my data. That's still helpful. 14:14 Make meaningful distinctions
John: By the way, we're going to talk philosophy in a little bit, but I will say that all the decisions I make about which reports to create, which tags to create, which categories to create, are driven by a philosophical principle which I call meaningful distinctions. We all interact with basically an uncountably large sea of information, and part of our job as knowledge workers is to impose criteria on that information so that we can make distinctions and say, "Okay, this relates to this, this relates to this." But there's all kinds of stuff we could be doing in making those distinctions, and not all of them are meaningful. Sometimes we spend energy— and all maintaining distinctions takes energy, because first you have to do it and then you have to maintain it. So it's very, very important to economize the work you spend making distinctions. I economize by trying to answer the question: is this distinction meaningful? What makes a distinction meaningful to me is that I use it in some way. It either has to help me in my job of maintaining focus on the appropriate information, or it has to help me with finding information. If it's not doing one of those two things, there's no reason to have the distinction. Even if a distinction screams out loud, "Hey, there's a distinction between your wife and your mother-in-law!"— does it matter that I draw that distinction? Probably not in most cases. So I have a "family" group rather than distinguishing those two people. Do I need to distinguish between all my co-workers? Probably—those are all distinctions that have some kind of meaning, but they're not meaningful to the purpose for which I use Org-mode, which is to assist my focus. So it's really important to know what you want Org-mode to do for you in order to make good use of Org-mode, especially at scale. 16:08 Color indicates agenda category
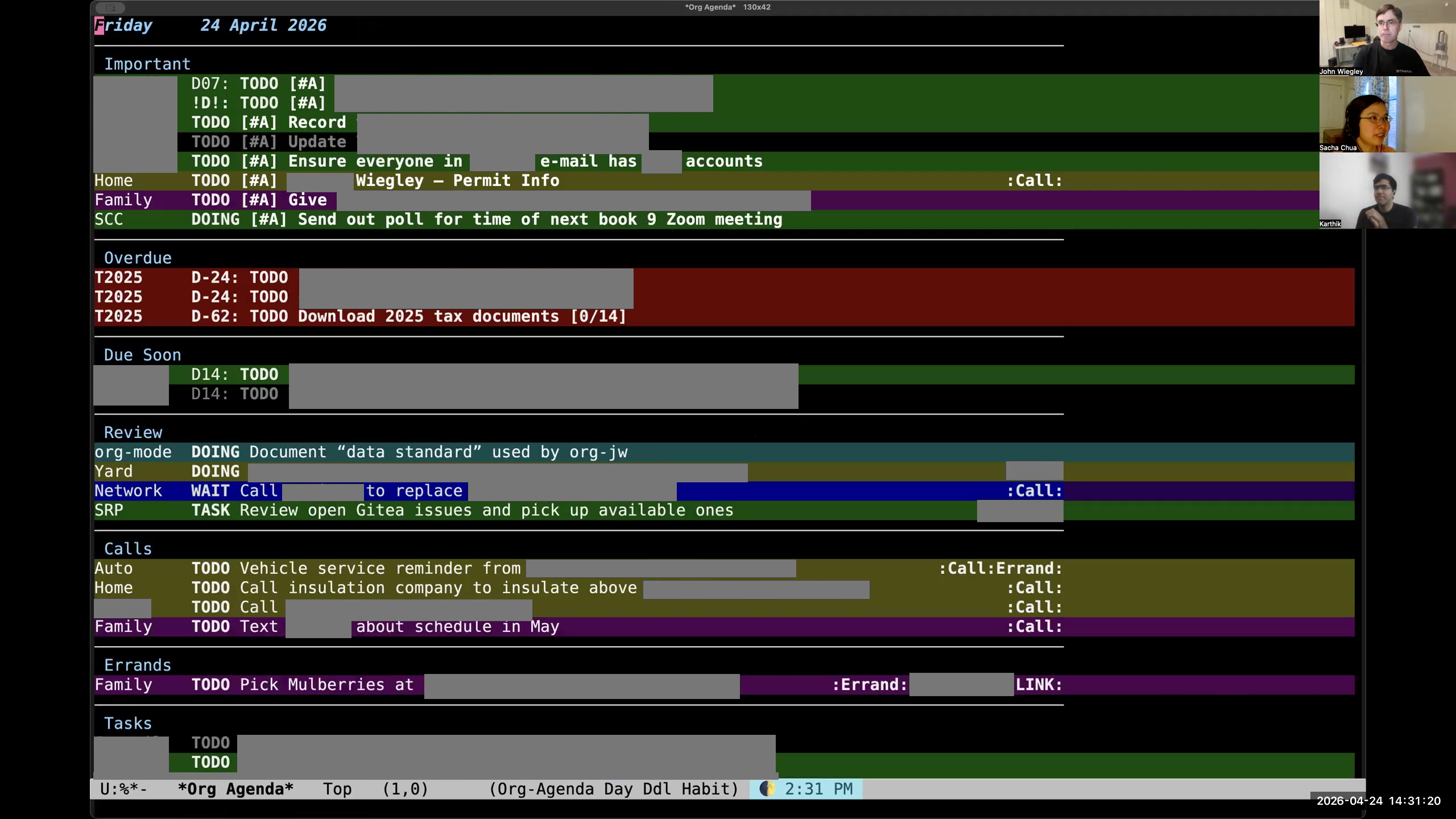 Sacha: I noticed one of the things that's changed since I last saw your agenda is now you're using color to make a lot of things more salient. So how do the colors in your agenda kind of build on the distinctions that you're making? John: The colors here are based on category. I also show the category in words on the left because many categories share colors. Everything that's personal is one color, everything that's work-related is another color, everything that's family, faith, open-source-related— they each have their own color. That way, when I look at the agenda, I see whether a color is dominating, or it draws my attention. If I see colors that I know are work, I will see if those need rescheduling into the next day first.
Sacha: I noticed one of the things that's changed since I last saw your agenda is now you're using color to make a lot of things more salient. So how do the colors in your agenda kind of build on the distinctions that you're making? John: The colors here are based on category. I also show the category in words on the left because many categories share colors. Everything that's personal is one color, everything that's work-related is another color, everything that's family, faith, open-source-related— they each have their own color. That way, when I look at the agenda, I see whether a color is dominating, or it draws my attention. If I see colors that I know are work, I will see if those need rescheduling into the next day first. 17:00 Simplifying meaningful distinctions
Sacha: All right. And it looks like the rest of your agenda is fairly light in terms of showing those meaningful distinctions. So I guess you're just using the filtering of the different agendas and other blocks in your outline to do that kind of filtering of things based on the distinctions you've already made. John: Yeah. I do still have lots of distinctions, but I have now narrowed it down. I used to have more, and then when I realized this concept, I started getting rid of as many of them as I could possibly get rid of. Otherwise it's just too—if you have to sit down and spend hours combing your data, it's just never going to happen. It's going to end up piling up on you and you'll never get to it. So this has to be a manageable amount of distinction, and every single one of those distinctions has to have precious value in helping me manage my focus. 18:01 Capturing a task
Sacha: Is it possible for you to walk us through an example of when you're capturing something and any structure you have to support making those distinctions? John: Usually I'd capture everything into drafts. So if I want to create an item, I use org-capture. Actually, I capture it in two ways, so I'll show you both of them. John: For capturing a task— Karthik: Sorry, John, before that, Sacha, do you see the window having shifted again? Sacha: It's doing the thing. I don't like seeing the thing. John: It's not moving at all over here. So this has to be something wrong happening with the Zoom client. Sacha: I don't know. John: We're just going to have to keep resharing it at intervals. Because nothing is moving here. Sacha: What if we don't make it full screen and we just make it slightly... Are you sharing the window or are you sharing the screen? John: I'm sharing the window. Sacha: Okay. You might consider sharing the whole screen if that's not too weird. John: I prefer not to, only because lots of notifications pop up. Sacha: Oh, yes. Okay, that makes sense too. John: And then we would have to blur those out as well. Sacha: Okay, then. All right. John: What I can try to do is share the window as a full-screen window. Sacha: Oh yeah, okay, well, we can work with that. Probably in post we can just—oh yeah, oh look at that, it's zooming in. Karthik: Okay. This is perfect. Sacha: We were talking about how... Sacha: Let's say you're creating a new task. Do you just type in the text and all that stuff by hand? Or do you have something to help you make those distinctions? 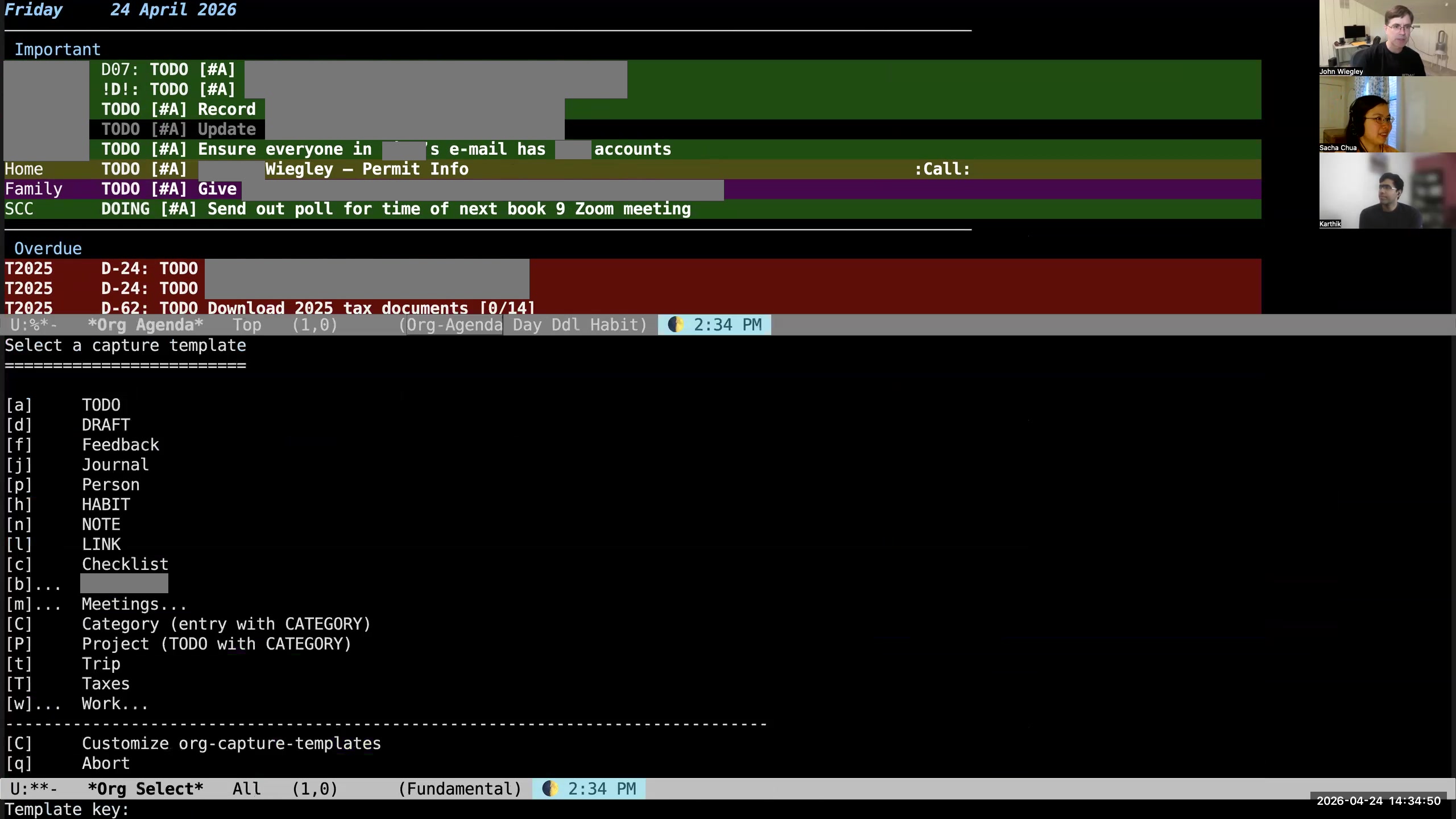 John: What I do is hit M-m, because that wasn't being used for anything else, and that pops up a capture template for what I want to add. So let's add a TODO. I'm going to say "send an email to Sacha."
John: What I do is hit M-m, because that wasn't being used for anything else, and that pops up a capture template for what I want to add. So let's add a TODO. I'm going to say "send an email to Sacha." 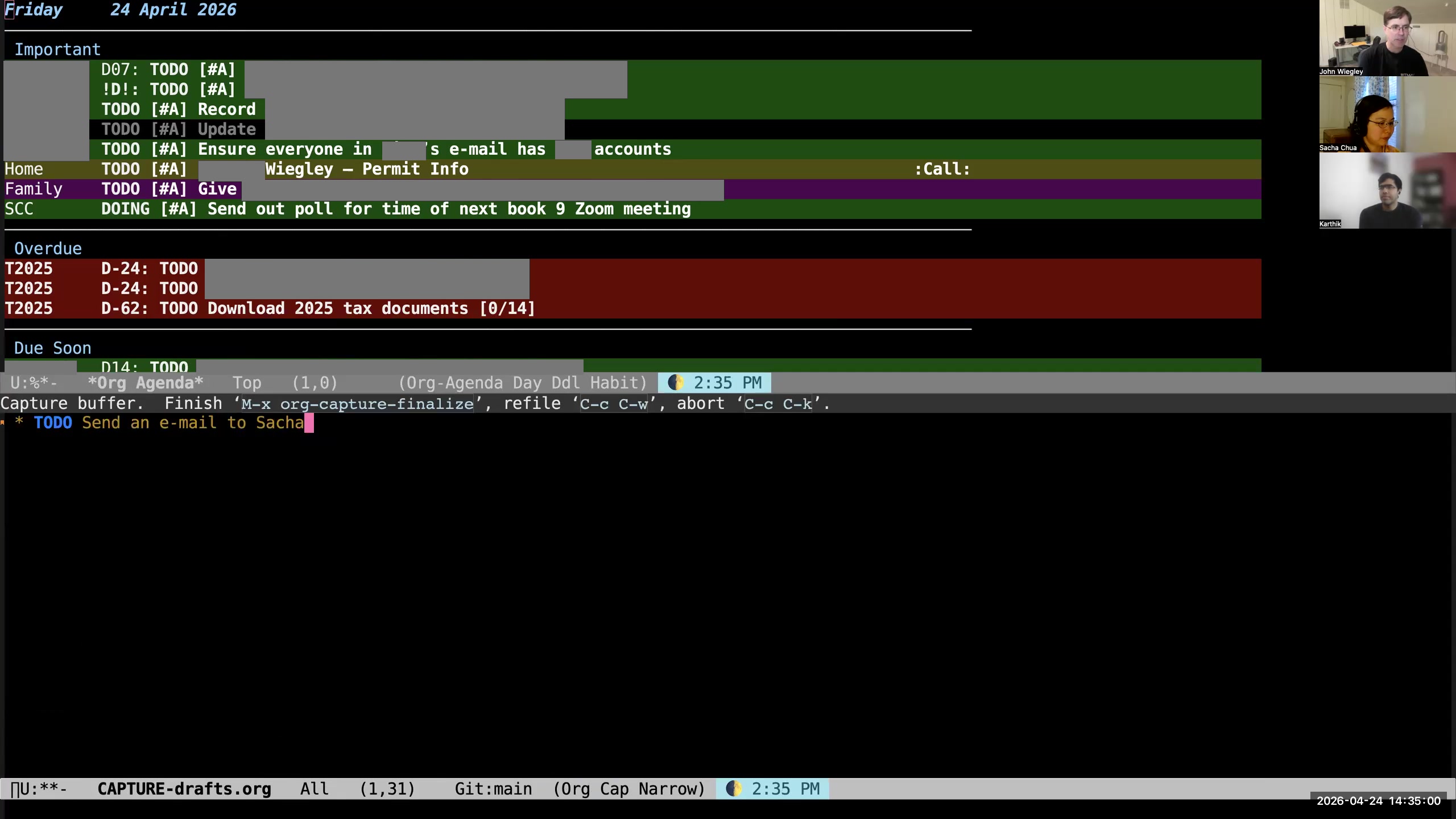 John: I try not to do any of that organization of the task at capture time. The idea with capture is that it gets onto paper as quickly as humanly possible. So I just hit C-c C-c, and it writes it out.
John: I try not to do any of that organization of the task at capture time. The idea with capture is that it gets onto paper as quickly as humanly possible. So I just hit C-c C-c, and it writes it out. 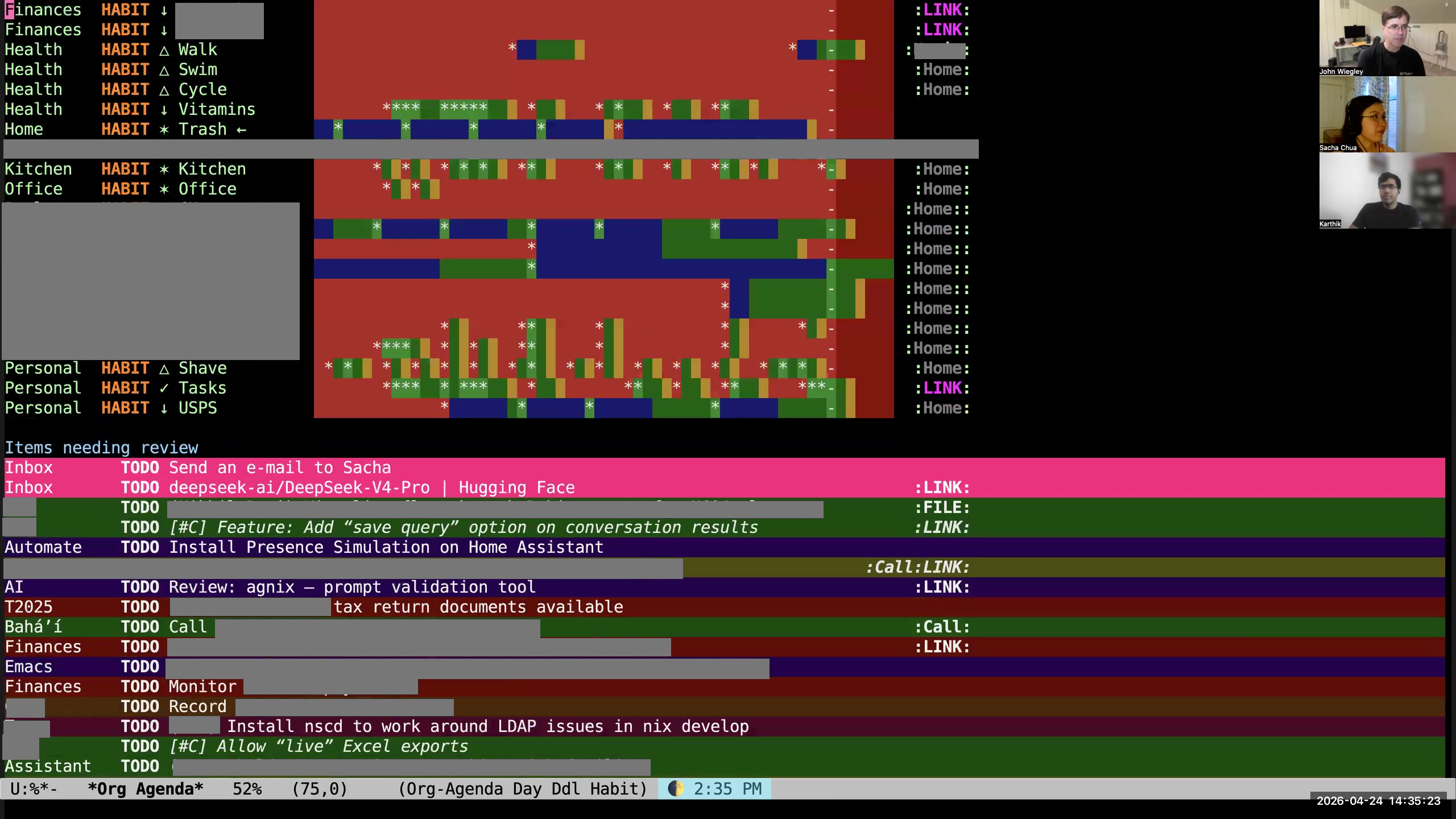 John: What will happen, because this is now in my drafts, is that it will appear at the top of my items needing review, and it will be in this very bright fuchsia-color background, which is extremely loud and always says to me, "You have items in your drafts that need reviewing."
John: What will happen, because this is now in my drafts, is that it will appear at the top of my items needing review, and it will be in this very bright fuchsia-color background, which is extremely loud and always says to me, "You have items in your drafts that need reviewing." 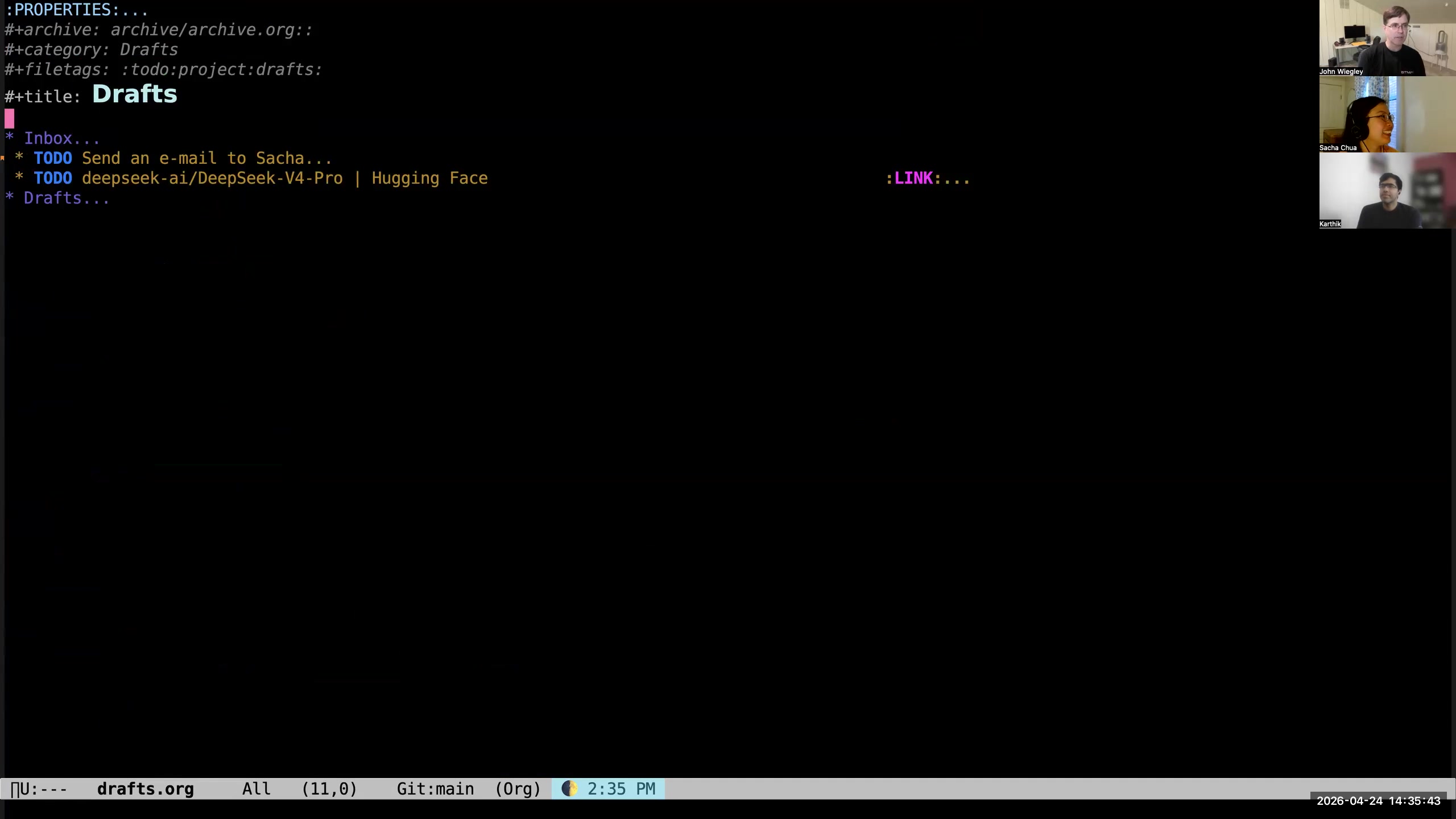 John: So I go to the item—here I'm in my drafts.org file, which has an inbox and a collection of drafts. (That's the other thing I'm going to tell you about.) Now I look at, "Oh, send..." I don't like using filler words. I actually have a report that finds entries that have filler words. So I always get rid of "a" and "the," stuff like that. So: "Send email to Sacha."
John: So I go to the item—here I'm in my drafts.org file, which has an inbox and a collection of drafts. (That's the other thing I'm going to tell you about.) Now I look at, "Oh, send..." I don't like using filler words. I actually have a report that finds entries that have filler words. So I always get rid of "a" and "the," stuff like that. So: "Send email to Sacha." 21:02 Task metadata is mostly automatic
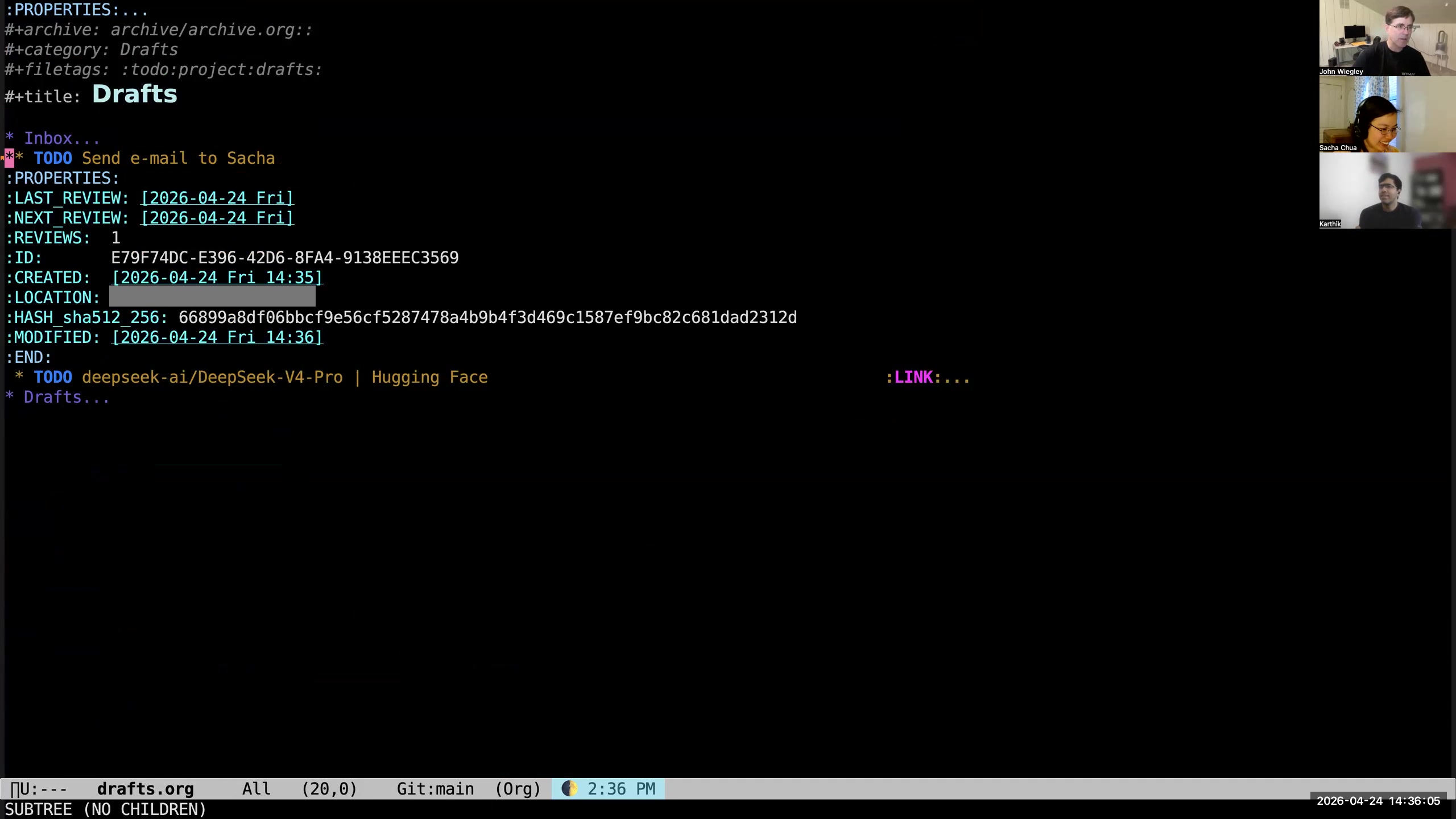 John: It comes with a lot of metadata. All of my tasks get a lot of metadata to start out. They get a notion of when I need to next review them. They always get a unique identifier— everything has a unique identifier, every entry, every file. They get the created timestamp, the GPS location of where I was when I created the task. The task itself is hashed so that I can know in the future when it changes, for a reason I will also explain shortly. The modified date is the last time the hash was updated, and that way I know... Sacha: I'm curious, what do you use GPS for? John: It's just information. Why not collect it? Any information I can collect that requires zero energy from me, I collect. Sacha: Okay, fair, fair. All right. So you're saying hash. Okay, you got a hash.
John: It comes with a lot of metadata. All of my tasks get a lot of metadata to start out. They get a notion of when I need to next review them. They always get a unique identifier— everything has a unique identifier, every entry, every file. They get the created timestamp, the GPS location of where I was when I created the task. The task itself is hashed so that I can know in the future when it changes, for a reason I will also explain shortly. The modified date is the last time the hash was updated, and that way I know... Sacha: I'm curious, what do you use GPS for? John: It's just information. Why not collect it? Any information I can collect that requires zero energy from me, I collect. Sacha: Okay, fair, fair. All right. So you're saying hash. Okay, you got a hash. 21:55 Task hash detects modifications
John: So I have a hash of the content, which includes all the property values other than the hash, of course, and the title and the body and all that kind of stuff. It just lets me know when the item has changed. I have a procedure in my Git pre-commit hook which will ensure that the hash is correct, and the hash updates whenever the file is saved. This is all being done by a module I wrote called org-hash, and org-hash will do this all for you. 22:24 Categorizing tasks
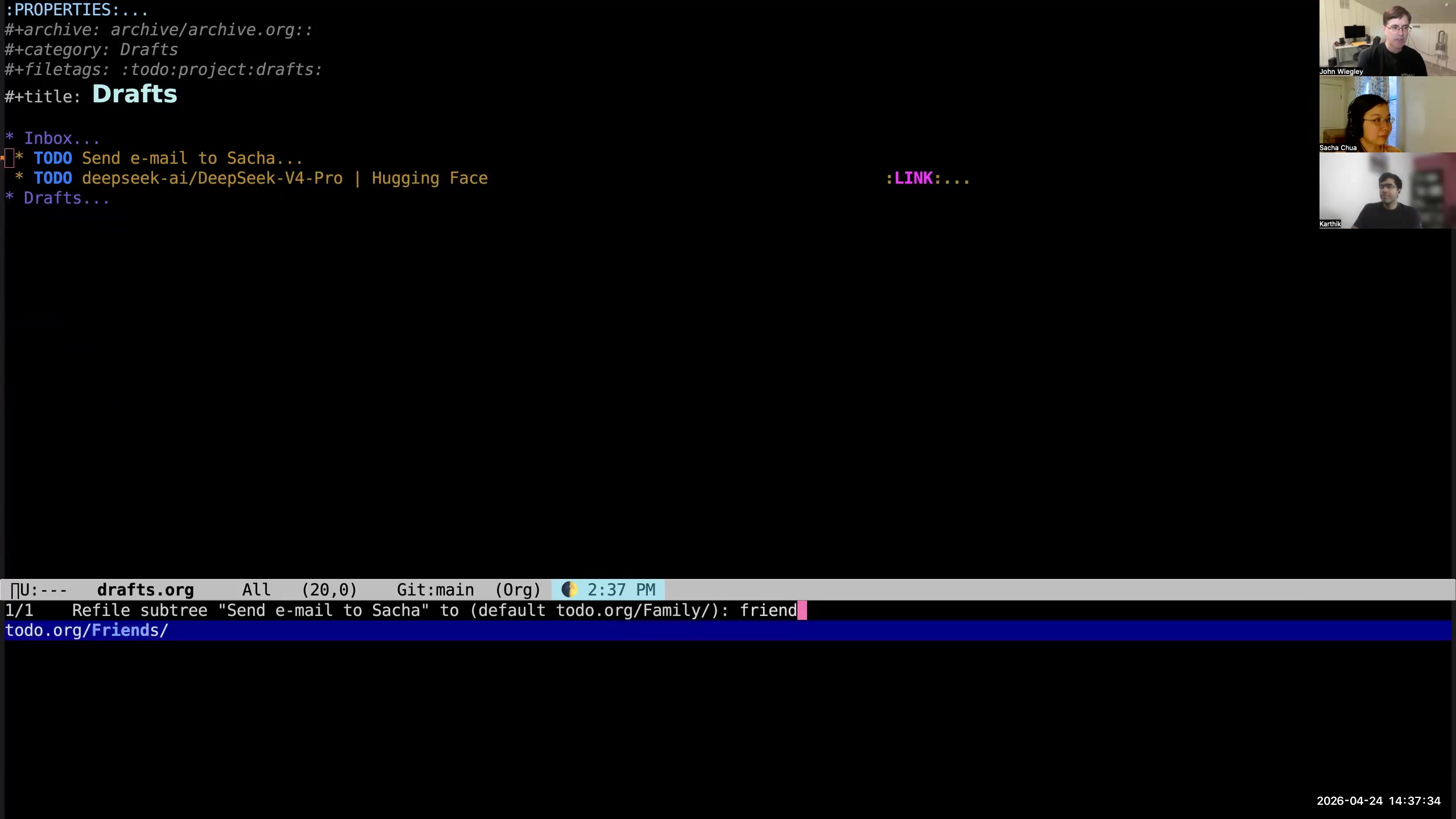 John: So now what I'll do is—this doesn't really need much categorization. I will just put it under "friends," so I just file it under friends. I didn't give it a scheduled date, so that'll appear in my review list rather than any daily agenda. This one is a reminder to me to download an AI model once the quantizations are available for my machine, so I'll just put that into the AI category.
John: So now what I'll do is—this doesn't really need much categorization. I will just put it under "friends," so I just file it under friends. I didn't give it a scheduled date, so that'll appear in my review list rather than any daily agenda. This one is a reminder to me to download an AI model once the quantizations are available for my machine, so I'll just put that into the AI category. 22:56 Daily reports should be short; reschedule or unschedule aggressively
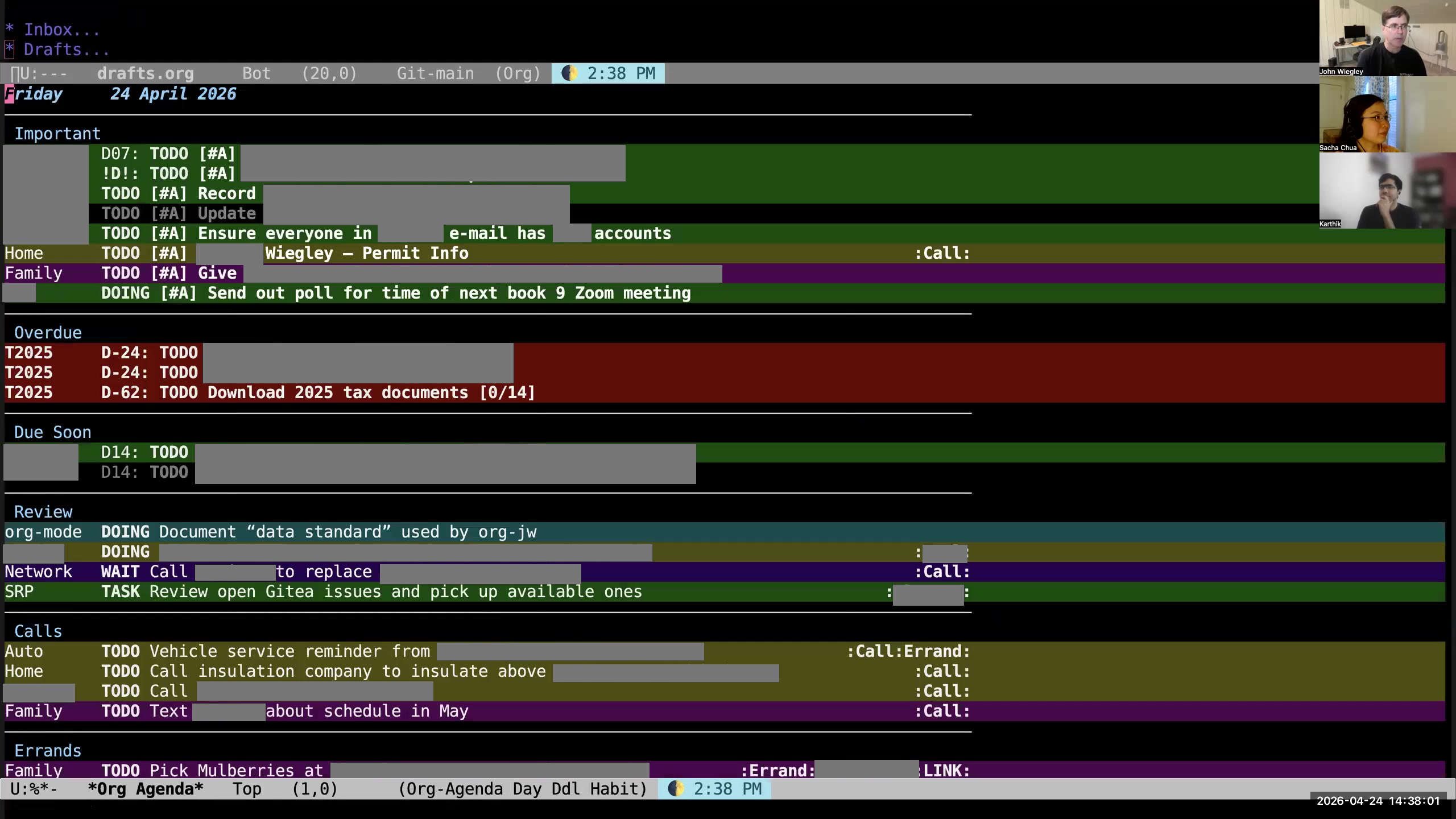 John: Now my inbox is empty and I can go back to my daily report. This daily report, by the way, is too long. In general, daily reports don't work unless they're less than ten items long. I haven't done it yet today, but I try to aggressively reschedule or unschedule things that don't fit within ten items in a day, because I just will never do more than ten items in a day. Like, I talked with my wife about this item, so I'm just going to move that to the next day so I can revisit it. These work items are going to have to go to Monday now. I'll just get them out. I reschedule or unschedule pretty aggressively. Sacha: Okay, so what I'm hearing is: you capture it very quickly, every so often you look over the bright fuchsia items in your review inbox, and say, "Okay, let me refile that to the categories"— the files, basically, or actually the places in your outline where they make sense. Then you have this list shown to you properly categorized now, but then you reschedule things until things look more manageable. John: Yeah, the ideal scenario is that on a given day, Org-mode is showing me ten or fewer items, and those ten items are the things I should be thinking about and doing on that day. That is not the case right now, which means I need to curate this. But that is the objective function for this entire system. If the system can do that, it is succeeding. So I just work as hard as I can to get the system to approximate that behavior. Sacha: Last time we talked, in 2024, you waxed nostalgic about LlamaGraphics Life Balance and some kind of automatic prioritization. You also briefly mentioned that you use AI sometimes to do sorting and reviewing. Is your workflow for prioritization still manual, or have you found something that works to help you? John: I did start writing an org-balance thing— you and I talked about it a while back— I have not continued that. I don't try to do automated balancing. I just look at the daily list and pick and choose. That generally ends up being what happens. As far as the task management in an AI-friendly way, we'll have to come back to that because that's another thing I want to show you. I don't think, Karthik, that 30 minutes is going to be anywhere near enough to even just show you the outline of how it is a system. Sacha: Yeah. That's why we have ongoing conversations. John: Yeah, this will just be the 10,000-foot overview for today.
John: Now my inbox is empty and I can go back to my daily report. This daily report, by the way, is too long. In general, daily reports don't work unless they're less than ten items long. I haven't done it yet today, but I try to aggressively reschedule or unschedule things that don't fit within ten items in a day, because I just will never do more than ten items in a day. Like, I talked with my wife about this item, so I'm just going to move that to the next day so I can revisit it. These work items are going to have to go to Monday now. I'll just get them out. I reschedule or unschedule pretty aggressively. Sacha: Okay, so what I'm hearing is: you capture it very quickly, every so often you look over the bright fuchsia items in your review inbox, and say, "Okay, let me refile that to the categories"— the files, basically, or actually the places in your outline where they make sense. Then you have this list shown to you properly categorized now, but then you reschedule things until things look more manageable. John: Yeah, the ideal scenario is that on a given day, Org-mode is showing me ten or fewer items, and those ten items are the things I should be thinking about and doing on that day. That is not the case right now, which means I need to curate this. But that is the objective function for this entire system. If the system can do that, it is succeeding. So I just work as hard as I can to get the system to approximate that behavior. Sacha: Last time we talked, in 2024, you waxed nostalgic about LlamaGraphics Life Balance and some kind of automatic prioritization. You also briefly mentioned that you use AI sometimes to do sorting and reviewing. Is your workflow for prioritization still manual, or have you found something that works to help you? John: I did start writing an org-balance thing— you and I talked about it a while back— I have not continued that. I don't try to do automated balancing. I just look at the daily list and pick and choose. That generally ends up being what happens. As far as the task management in an AI-friendly way, we'll have to come back to that because that's another thing I want to show you. I don't think, Karthik, that 30 minutes is going to be anywhere near enough to even just show you the outline of how it is a system. Sacha: Yeah. That's why we have ongoing conversations. John: Yeah, this will just be the 10,000-foot overview for today. 25:41 Note from Karthik: John is an old-school Org user
Karthik: If I may jump in, I'm thinking about this from the perspective of someone who knows what Org-mode is and maybe has used it once or twice and is now watching this on a video hosting platform and is going, "What? What's happening here?" So can we zoom out a bit? Maybe I should start by saying that John is an old-school Org user. I mean, he's also new-school as we'll see when we get to the AI stuff. But John is a veteran Org user who's been using it for 20-plus years, if I'm not wrong. There are functions in Emacs Org-mode that are named after John, or at least mention John in their docstring as the reason for their existence. This is what you're looking at, and what you were probably confused by, dear viewer, is the result of 20 years of using Org and organizing your life with Org and then optimizing and improving the workflow incrementally. This is kind of where you end up. Okay, maybe that should go in the intro, but now it's fine. 27:04 Continuing with the lifecycle: capture, file, schedule, review
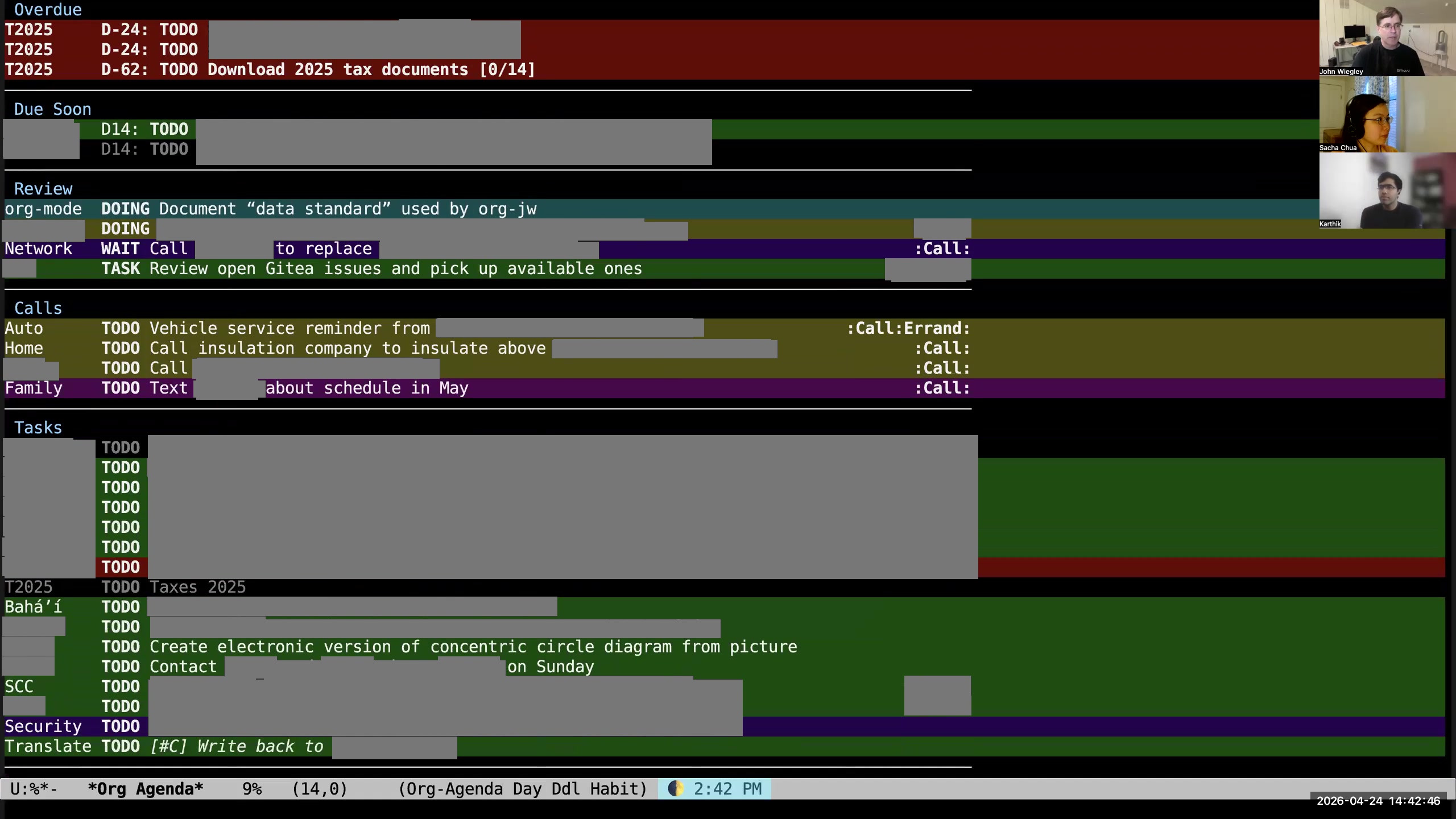 Karthik: Maybe we can continue with the capture example that you were showing—the typical lifecycle of a piece of information, right? It starts as a capture and then shows up in the agenda. Well, it shows up in the agenda very brightly saying "pay attention to me," and then eventually gets filed somewhere. Let's continue from there. What happens next? What happens to the email that you haven't written to Sacha? John: Well, either I schedule the task at that time and then it's going to appear in one of these daily agendas, or— as I'm looking at my agenda here, you'll see I have my items for today all grouped out by org-super-agenda.
Karthik: Maybe we can continue with the capture example that you were showing—the typical lifecycle of a piece of information, right? It starts as a capture and then shows up in the agenda. Well, it shows up in the agenda very brightly saying "pay attention to me," and then eventually gets filed somewhere. Let's continue from there. What happens next? What happens to the email that you haven't written to Sacha? John: Well, either I schedule the task at that time and then it's going to appear in one of these daily agendas, or— as I'm looking at my agenda here, you'll see I have my items for today all grouped out by org-super-agenda. 27:48 Habits
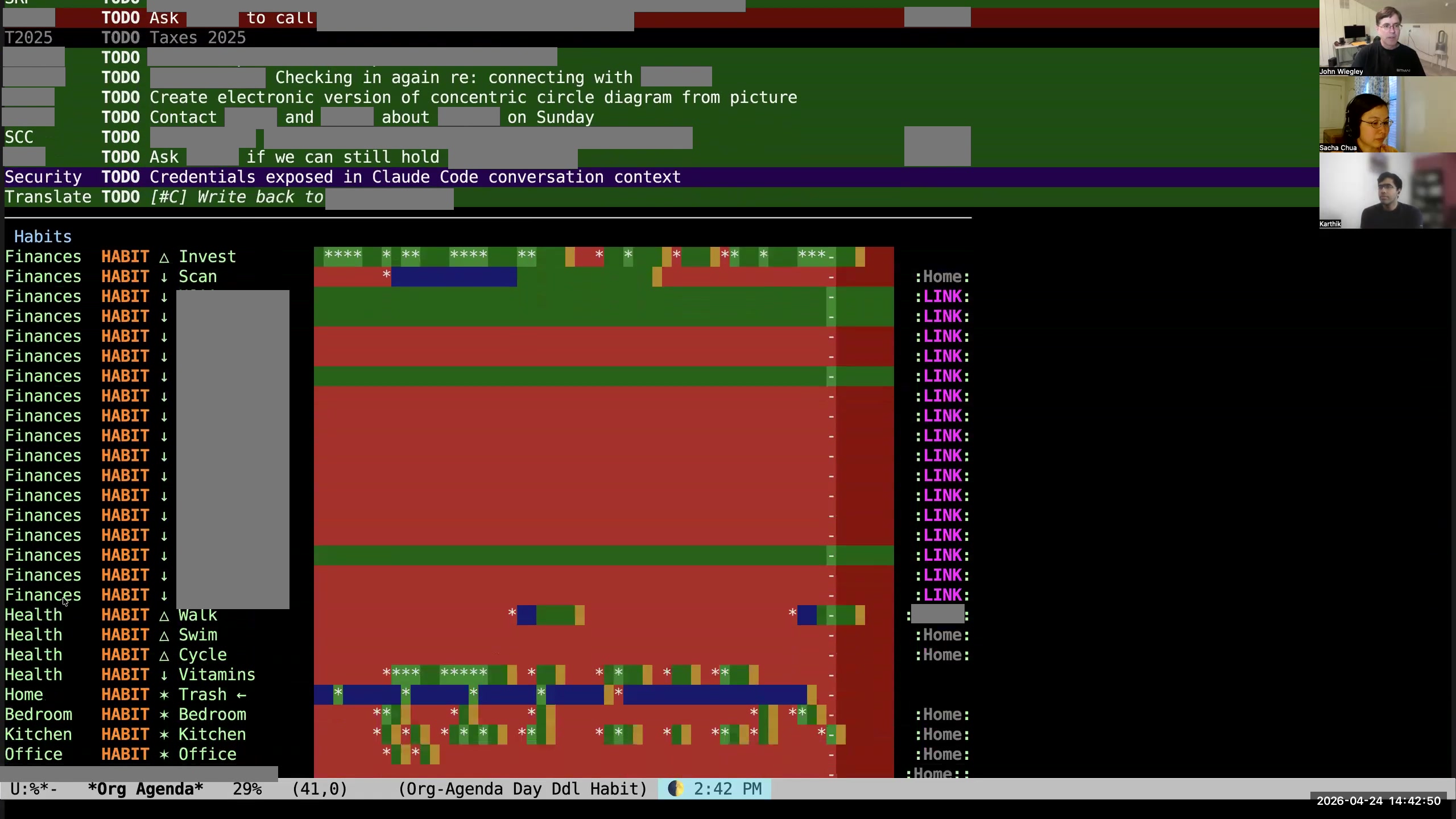 John: Then I have habits, which is a different type of task where I'm trying to track consistency rather than completion. I use habits a lot, especially because I really love the book Atomic Habits. It makes some really good arguments about the importance of behaviors and processes to getting things really done.
John: Then I have habits, which is a different type of task where I'm trying to track consistency rather than completion. I use habits a lot, especially because I really love the book Atomic Habits. It makes some really good arguments about the importance of behaviors and processes to getting things really done. 28:09 org-review and items needing review; randomization
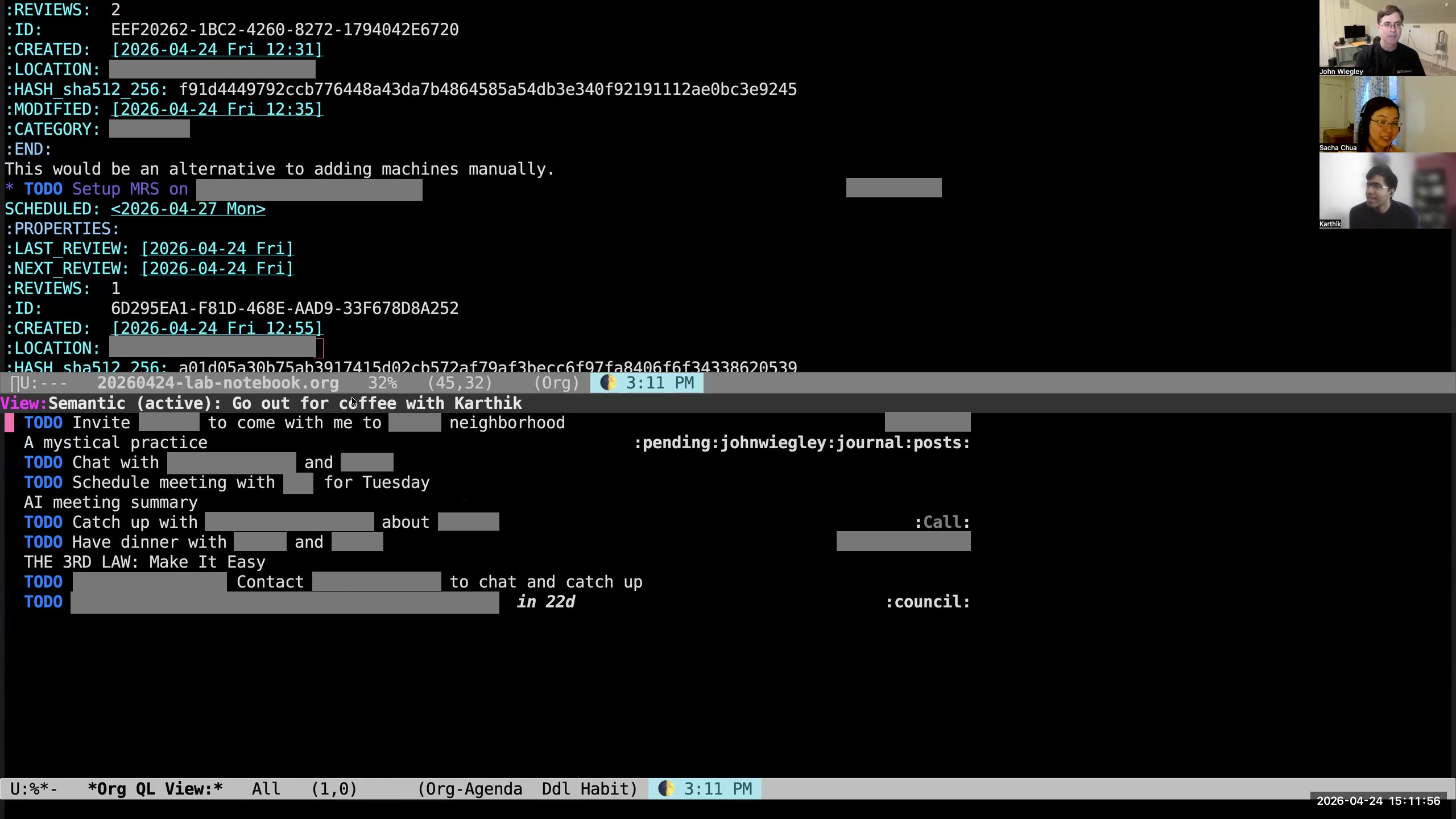
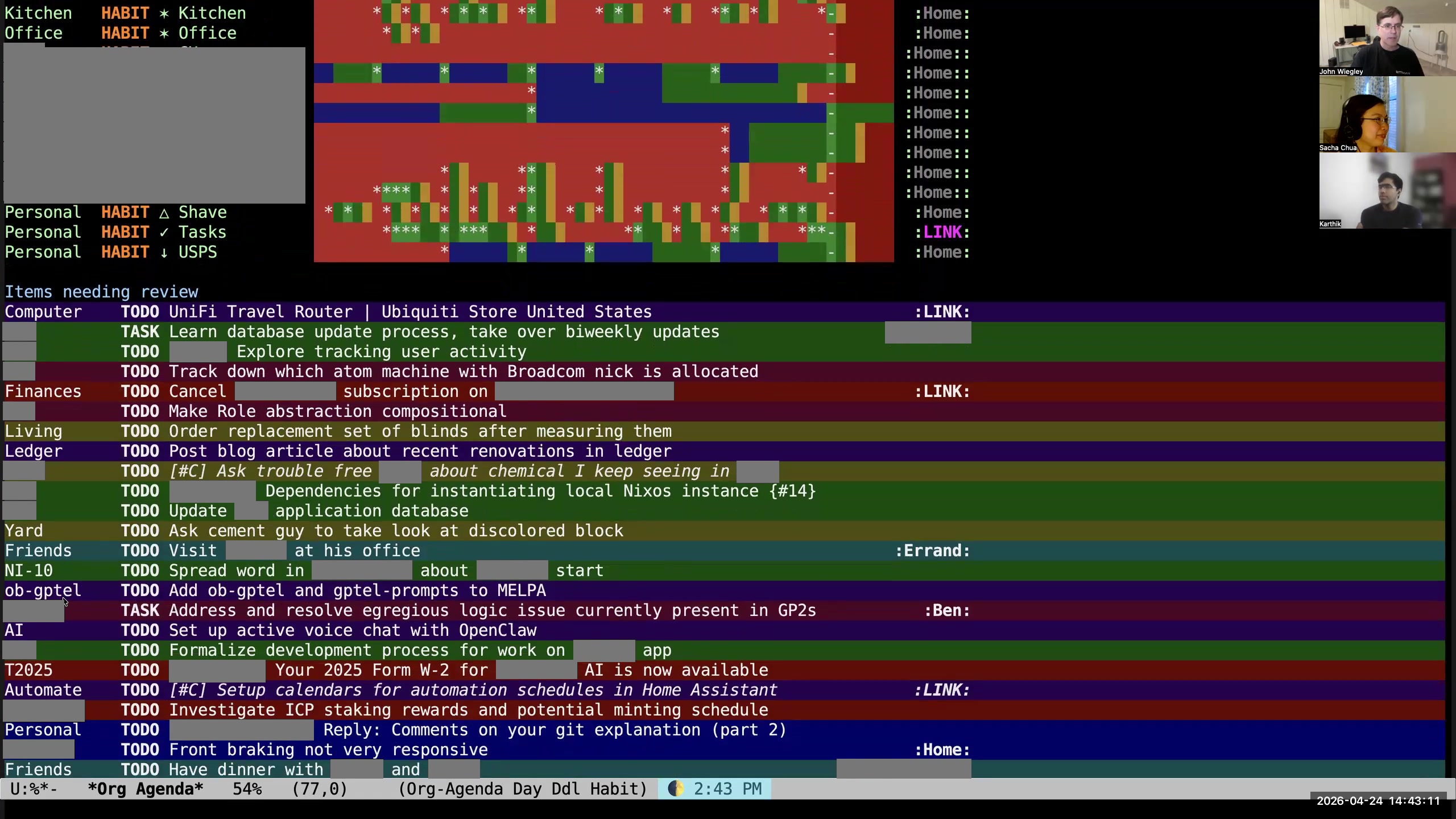 John: Then at the bottom of every agenda view is this section, "items needing review." I have close to a thousand items currently needing review. I can't review them— that's too many to review. Even if I just looked at the work ones, it would still be too many to review. So what I choose to do instead is that every time I refresh my agenda view, it picks 38 unreviewed or unscheduled items at random and puts them here in this list. What I do is I just sort of scan it to say, "Is there anything in this list that really I should be doing? Should I be scheduling something?" I don't even try to read the whole list because that is too much. I just cherry-pick. I say, "Oh, is there anything? Oh, look at this— 'set up active voice chat with OpenClaw.' Well, that's going to be priority C, that's not very important." Or this one, "front braking on my bike is not very responsive." You know what? I don't really care about that right now, so I'm going to tell it to show it to me for review later in the summer. I have a bunch of key bindings behind the key r, which allow me to change when it will be reviewed by. Karthik: Okay, so to clarify, this idea of a review is different from anything that Org provides you out of the box, right? This is not scheduling the task to be completed at a certain time. This is not a timestamp in the sense of an event in a calendar. This is not a deadline. This is like a different concept that means show this to me after this time. Is that correct?
John: Then at the bottom of every agenda view is this section, "items needing review." I have close to a thousand items currently needing review. I can't review them— that's too many to review. Even if I just looked at the work ones, it would still be too many to review. So what I choose to do instead is that every time I refresh my agenda view, it picks 38 unreviewed or unscheduled items at random and puts them here in this list. What I do is I just sort of scan it to say, "Is there anything in this list that really I should be doing? Should I be scheduling something?" I don't even try to read the whole list because that is too much. I just cherry-pick. I say, "Oh, is there anything? Oh, look at this— 'set up active voice chat with OpenClaw.' Well, that's going to be priority C, that's not very important." Or this one, "front braking on my bike is not very responsive." You know what? I don't really care about that right now, so I'm going to tell it to show it to me for review later in the summer. I have a bunch of key bindings behind the key r, which allow me to change when it will be reviewed by. Karthik: Okay, so to clarify, this idea of a review is different from anything that Org provides you out of the box, right? This is not scheduling the task to be completed at a certain time. This is not a timestamp in the sense of an event in a calendar. This is not a deadline. This is like a different concept that means show this to me after this time. Is that correct? 29:49 org-review task properties
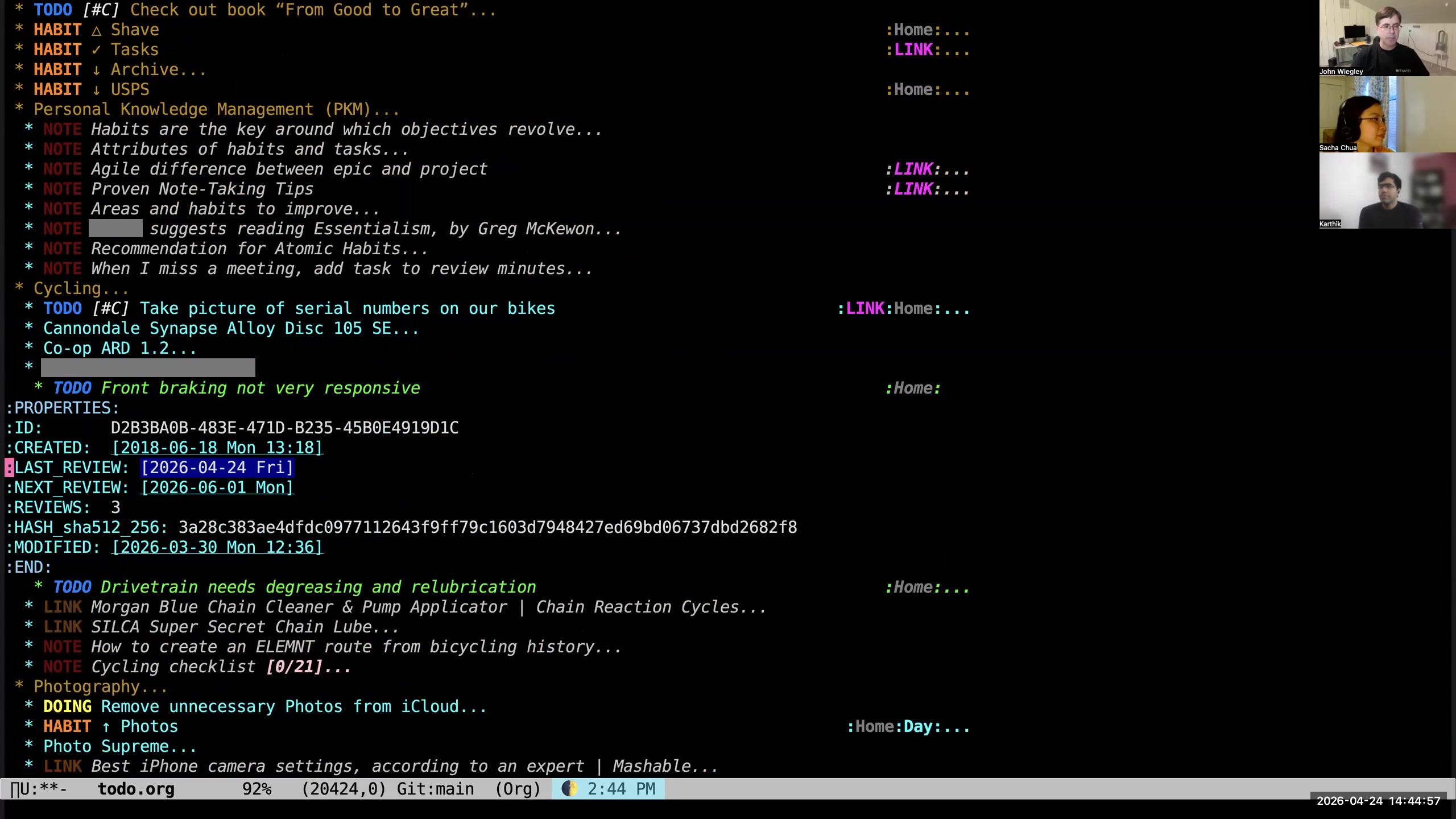 John: Yes. If we look at the task itself, we will see in the properties for that task it has these three properties:
John: Yes. If we look at the task itself, we will see in the properties for that task it has these three properties: LAST_REVIEW,
NEXT_REVIEW, and REVIEWS. These are added by the org-review package, which is an add-on to Org-mode that's not part of the stock distribution. LAST_REVIEW is the last time it was reviewed, of
course. NEXT_REVIEW is the next time I want to see it in the reports that gather tasks to be reviewed. That's the only time that date ever comes into play. If that date NEXT_REVIEW is in the future, it won't show up in those 38 items that are randomly selected underneath my tasks. So if I've reviewed every task and they're all in the future, then that list at the bottom of my to-do list would be empty. It has been empty sometimes when I'm on vacation and I have the time to actually review tasks. REVIEWS is something I added to keep track of how many times I have pushed that into the future, because then I can create an agenda report for the redheaded stepchildren in my Org-mode database— who are the people that are just keep getting pushed and pushed and pushed and never getting any attention? Karthik: Okay, so this is like a whole subsystem that you added to Org to handle the kinds of tasks that are maybe important but not urgent? John: Right. Because there has to be a midway between "these are the focus tasks for today" and "these are all the guys that aren't scheduled." There has to be something in between those two, because the gap is too large. Sacha: All right, so instead of just relying on scheduling, you use reviews to give you that extra level of "I want this to come back on my radar every so often." You will actually have a randomized subset of these things to come back on your radar every so often, but you're not necessarily scheduling it for that day, so that your scheduled tasks still focus on your priorities. Right. 31:48 It's all just plain text
John: Now, at the end of the day, Org-mode files are just text files. That's one of the beauties of the whole system: they're really nothing special. Because it's Org-roam on top of Org-mode, I have many files. I have hundreds and hundreds of Org-mode files. Many of them contain tasks, many of them do not. I use some advice from the internet on how to optimize the collection of tasks for the agenda so that it only opens the files that have tasks in them. That way it stays nice and responsive, even though the number of files is constantly growing. The reason I use separate Org-mode files is, yes, I do separate by topic sometimes— I have a file for work and a file for personal— but I also like to have an individual file for every meeting. At work, if I have a one-on-one meeting, a team meeting, a project meeting, an all-hands meeting, I will create a file for that meeting. I will put into it who the attendees are and what was the agenda. I will have an AI note-taker (usually Gemini or Fireflies or something like that) on during that meeting, so that I can include the summary, the action items, and the transcript from the AI note-taker inside that file when the meeting is done. I also have a notes section where I collect all of the Org-mode tasks and notes. I don't use the drafts mechanism to capture in those instances; I capture them directly into the file. 33:18 Capturing to the current point with M-0
 John: One of the nice things about Org-mode is that when I hit M-m to select the capture template, that's going to go into my drafts file. But if I hit M-0 M-m, then it's going to capture it where I currently am. So I could say M-0 M-m a,
John: One of the nice things about Org-mode is that when I hit M-m to select the capture template, that's going to go into my drafts file. But if I hit M-0 M-m, then it's going to capture it where I currently am. So I could say M-0 M-m a,  John: and then I could say "send email to Sacha" again— you're going to get lots of emails, Sacha—
John: and then I could say "send email to Sacha" again— you're going to get lots of emails, Sacha—  John: and as you can see, it's right here in the file where I was a moment ago. That's what I use to capture stuff into the one-on-one files. So I use M-m if I'm using the Org-mode capture, which is for individual items that either are in my current location or in the drafts.
John: and as you can see, it's right here in the file where I was a moment ago. That's what I use to capture stuff into the one-on-one files. So I use M-m if I'm using the Org-mode capture, which is for individual items that either are in my current location or in the drafts. 33:59 A different set of Org Roam capture templates
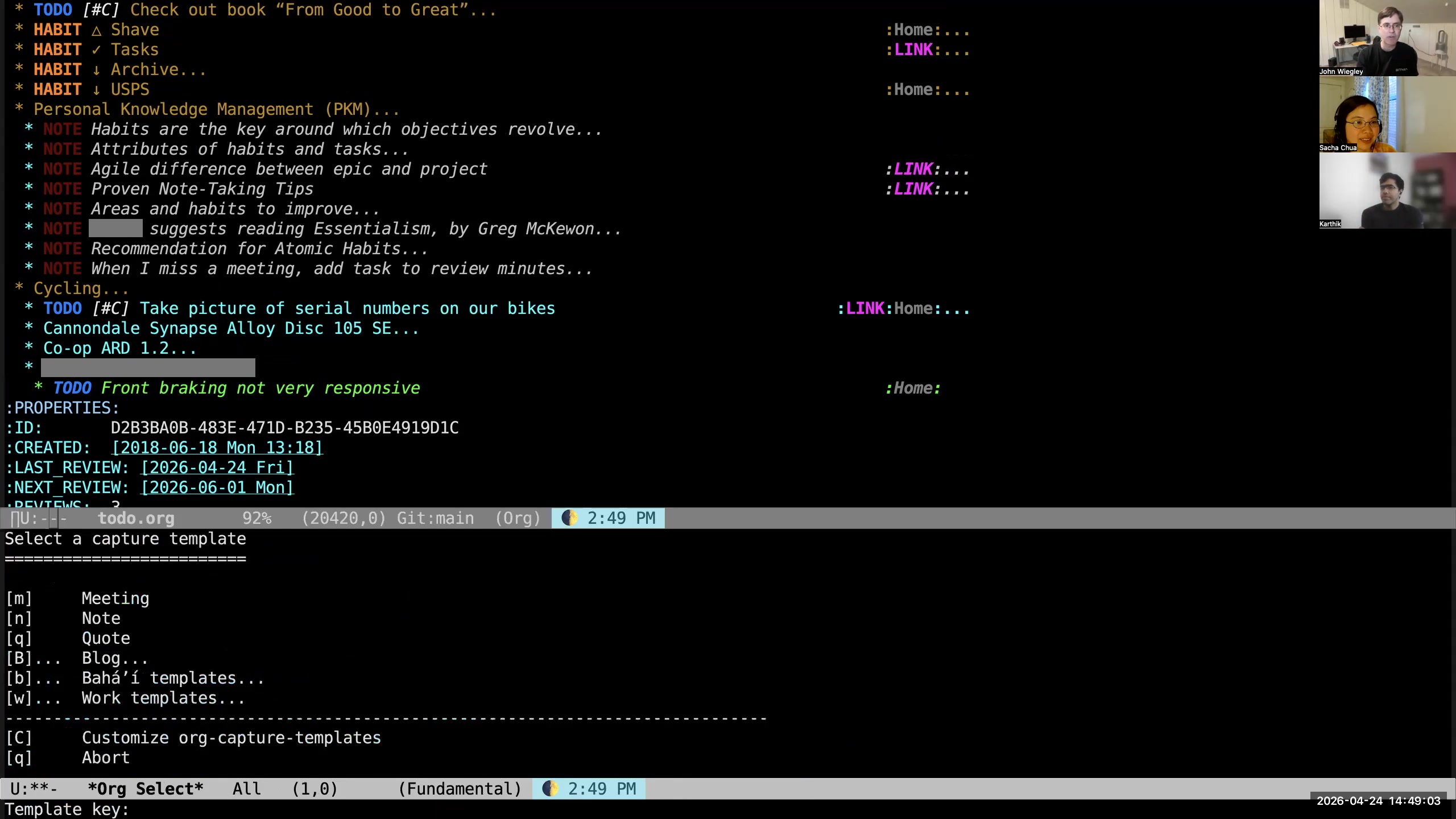 John: Then I use C-c M-m for a different set of capture templates, which are for Org-roam files. If I do C-c M-m, then I can go to my work templates, my Bahá'í templates. I could capture a note, which is an independent empty file. I could capture a blog for one of my two blogs.
John: Then I use C-c M-m for a different set of capture templates, which are for Org-roam files. If I do C-c M-m, then I can go to my work templates, my Bahá'í templates. I could capture a note, which is an independent empty file. I could capture a blog for one of my two blogs. 34:18 Capturing by name
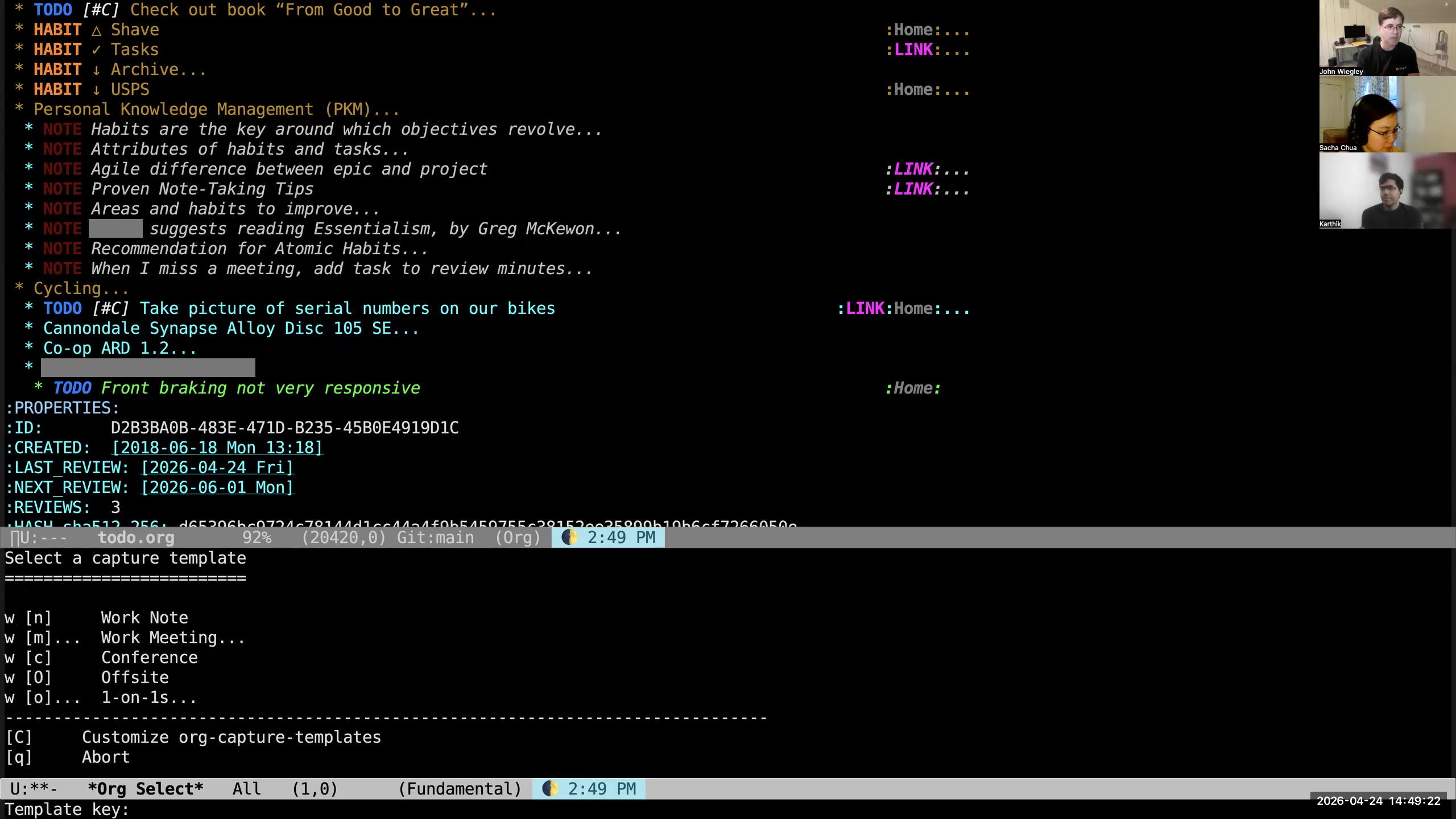 John: So let's do work. I'll say "work," I'll say "O" for one-on-ones,
John: So let's do work. I'll say "work," I'll say "O" for one-on-ones, 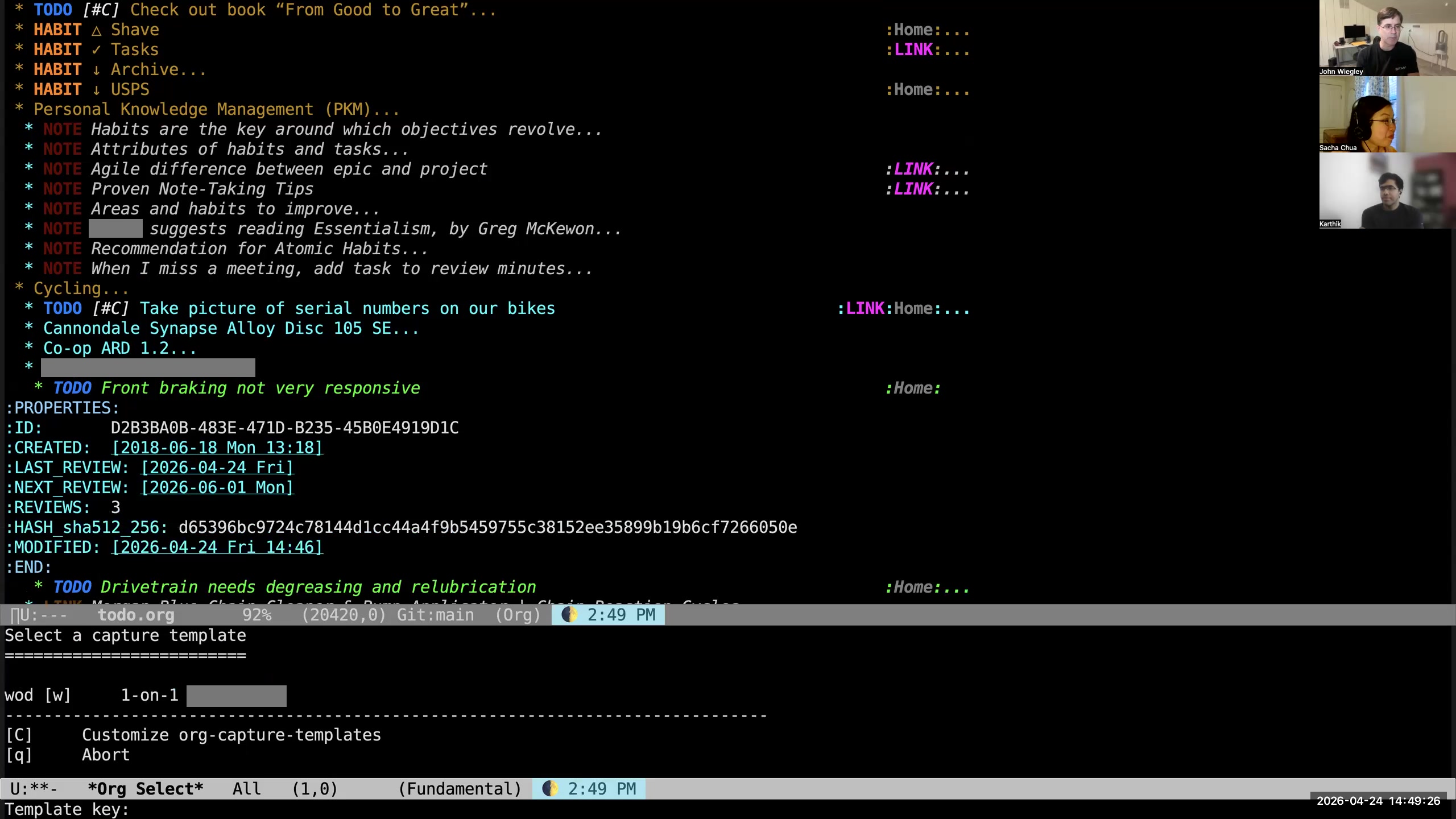 John: I'll say "D" for names that begin with D,
John: I'll say "D" for names that begin with D, 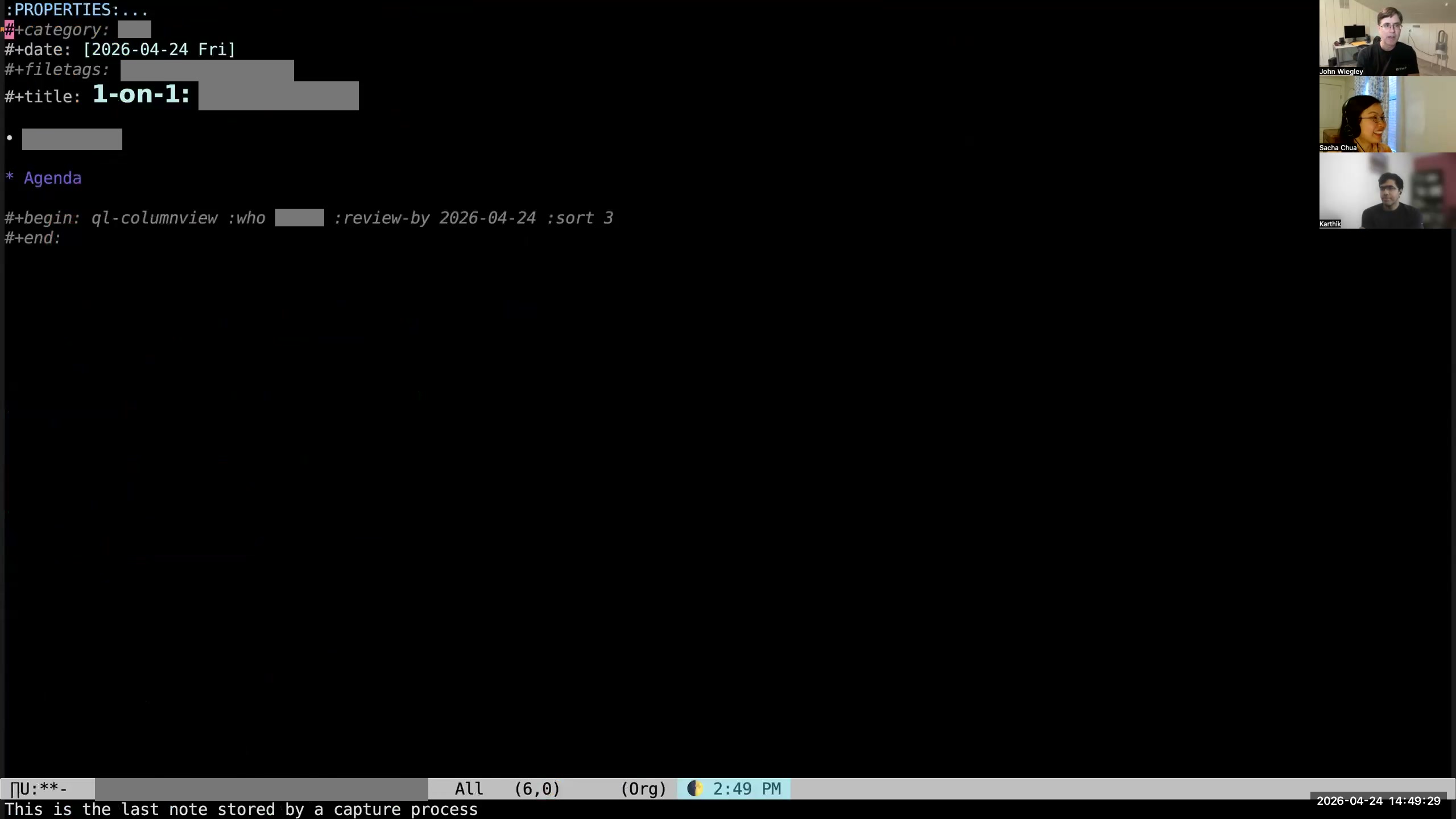 John: and I'll say "W" and it will be my manager. What that will do is now it pops me into an Org-roam file where all the metadata for this file has been set up: the right category, the right file tags, creation date, everything.
John: and I'll say "W" and it will be my manager. What that will do is now it pops me into an Org-roam file where all the metadata for this file has been set up: the right category, the right file tags, creation date, everything. 34:38 An after-save hook automatically renames the files
 John: I like to add the meeting time to the date. When I save the file, then there is an after-save hook that will automatically rename the file so it has the correct date and time in the filename.
John: I like to add the meeting time to the date. When I save the file, then there is an after-save hook that will automatically rename the file so it has the correct date and time in the filename. 34:54 org-ql in the template provides a meeting agenda
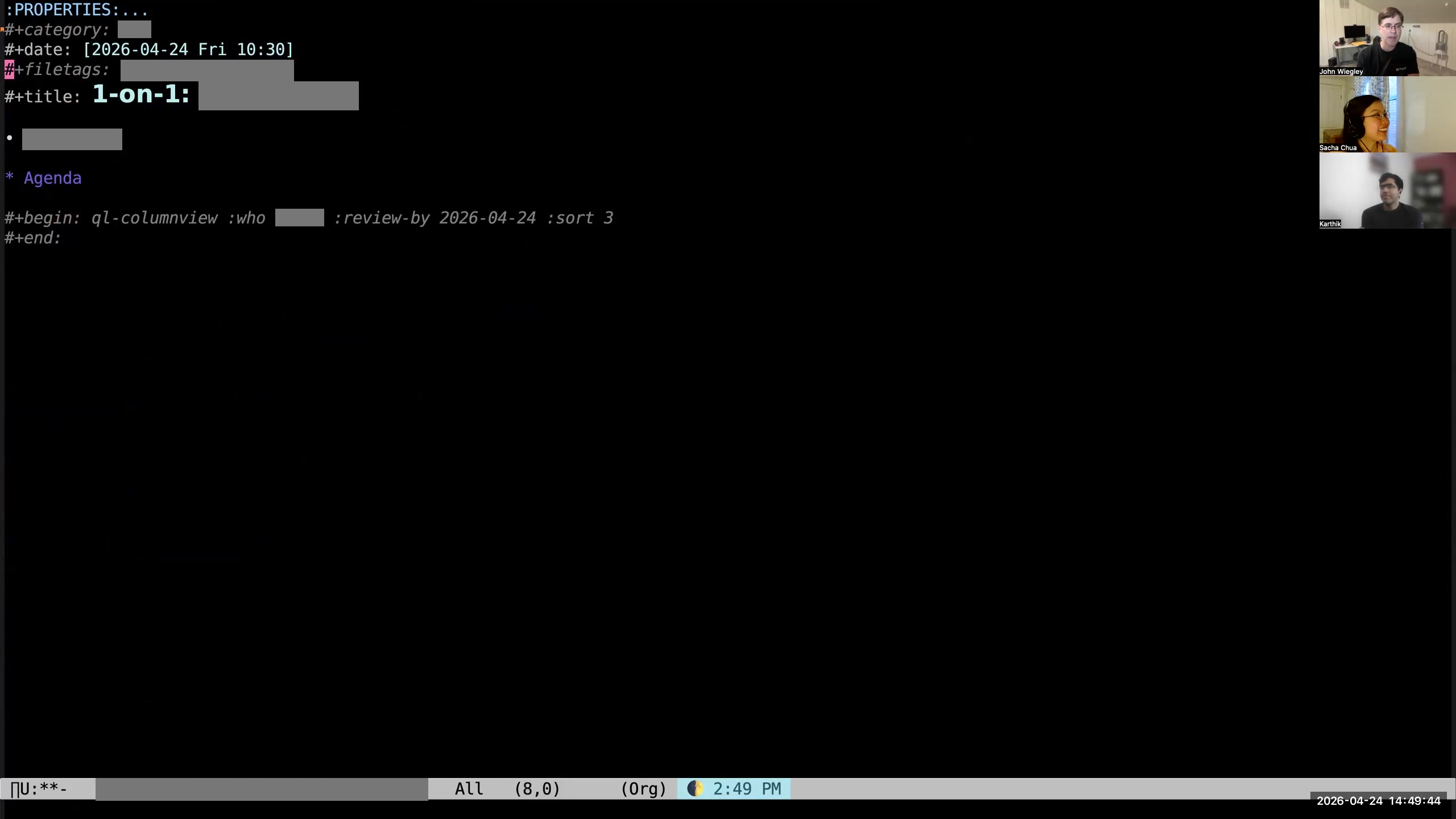
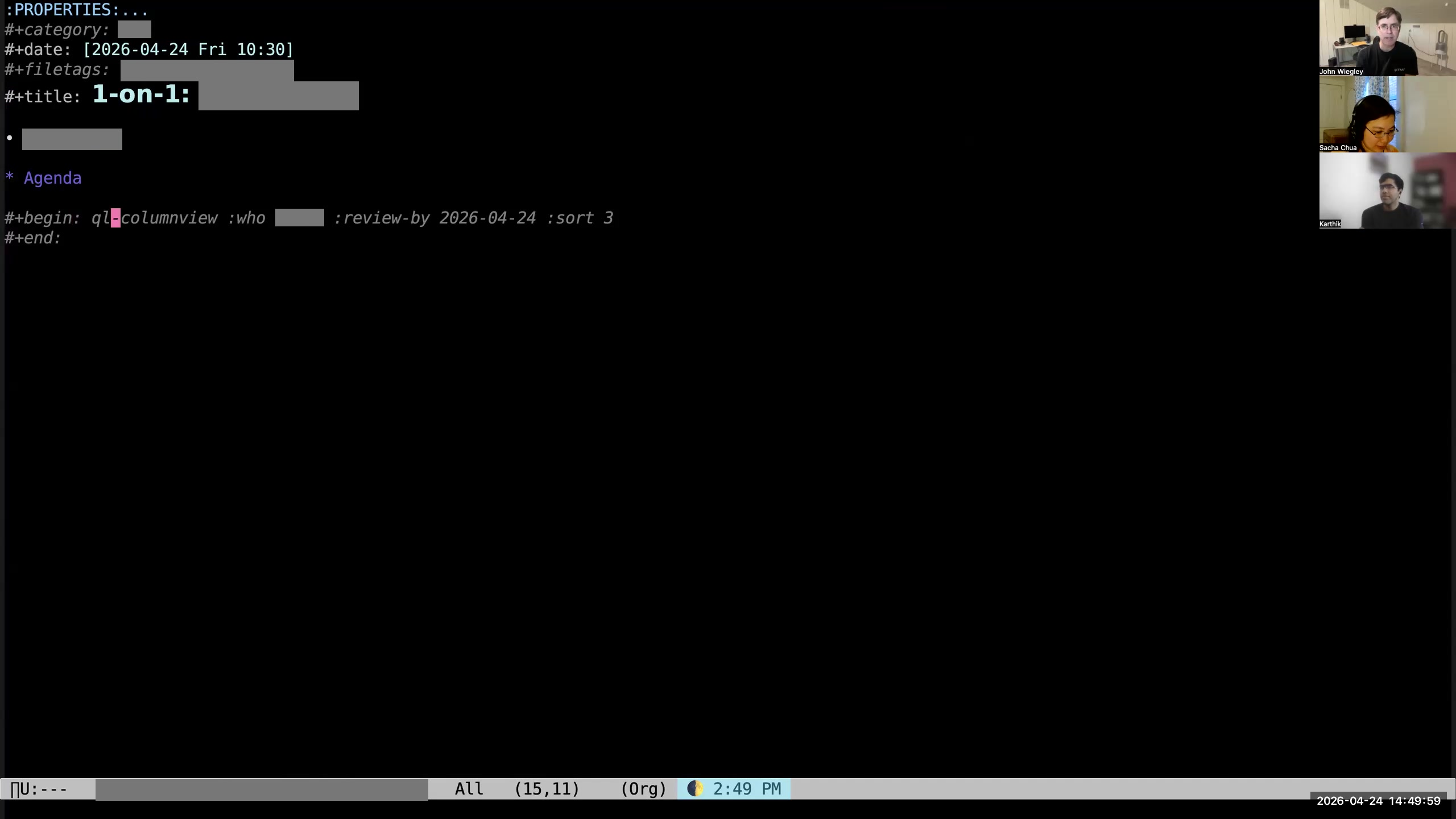 John: Then you can see that it has pre-populated an empty org-ql column view,
John: Then you can see that it has pre-populated an empty org-ql column view, 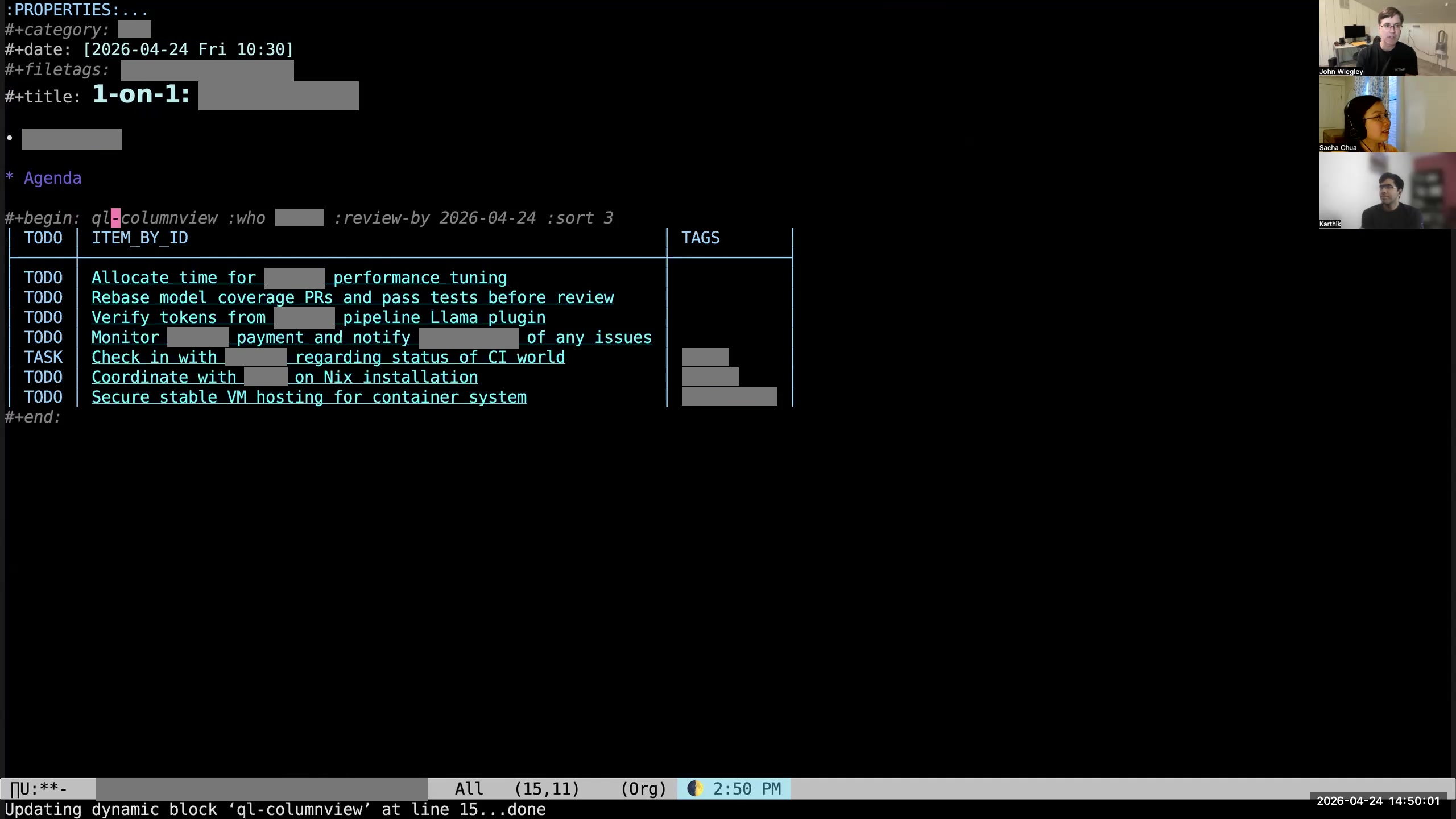 John: which I then hit C-c C-c on. So now, if the person I'm meeting with has not provided me with an agenda, I have an automatically constructed agenda for that person based on what I know I have to do for them in my Org-mode data. When I was a manager for several employees and would use Fireflies to capture all the action items from all of our meetings, this was how I followed up on all those action items with all the people. I had one-on-ones with every direct every week, and I would auto-populate agendas for those meetings from Org-mode. Then I would just go through the agenda with them and say, "What's the status? What's the status?" and just keep that moving forward. That ended up being a really nice system for making sure that all the action items we committed to were being completed.
John: which I then hit C-c C-c on. So now, if the person I'm meeting with has not provided me with an agenda, I have an automatically constructed agenda for that person based on what I know I have to do for them in my Org-mode data. When I was a manager for several employees and would use Fireflies to capture all the action items from all of our meetings, this was how I followed up on all those action items with all the people. I had one-on-ones with every direct every week, and I would auto-populate agendas for those meetings from Org-mode. Then I would just go through the agenda with them and say, "What's the status? What's the status?" and just keep that moving forward. That ended up being a really nice system for making sure that all the action items we committed to were being completed. 35:49 The "Review by" argument for the column view block filters the tasks
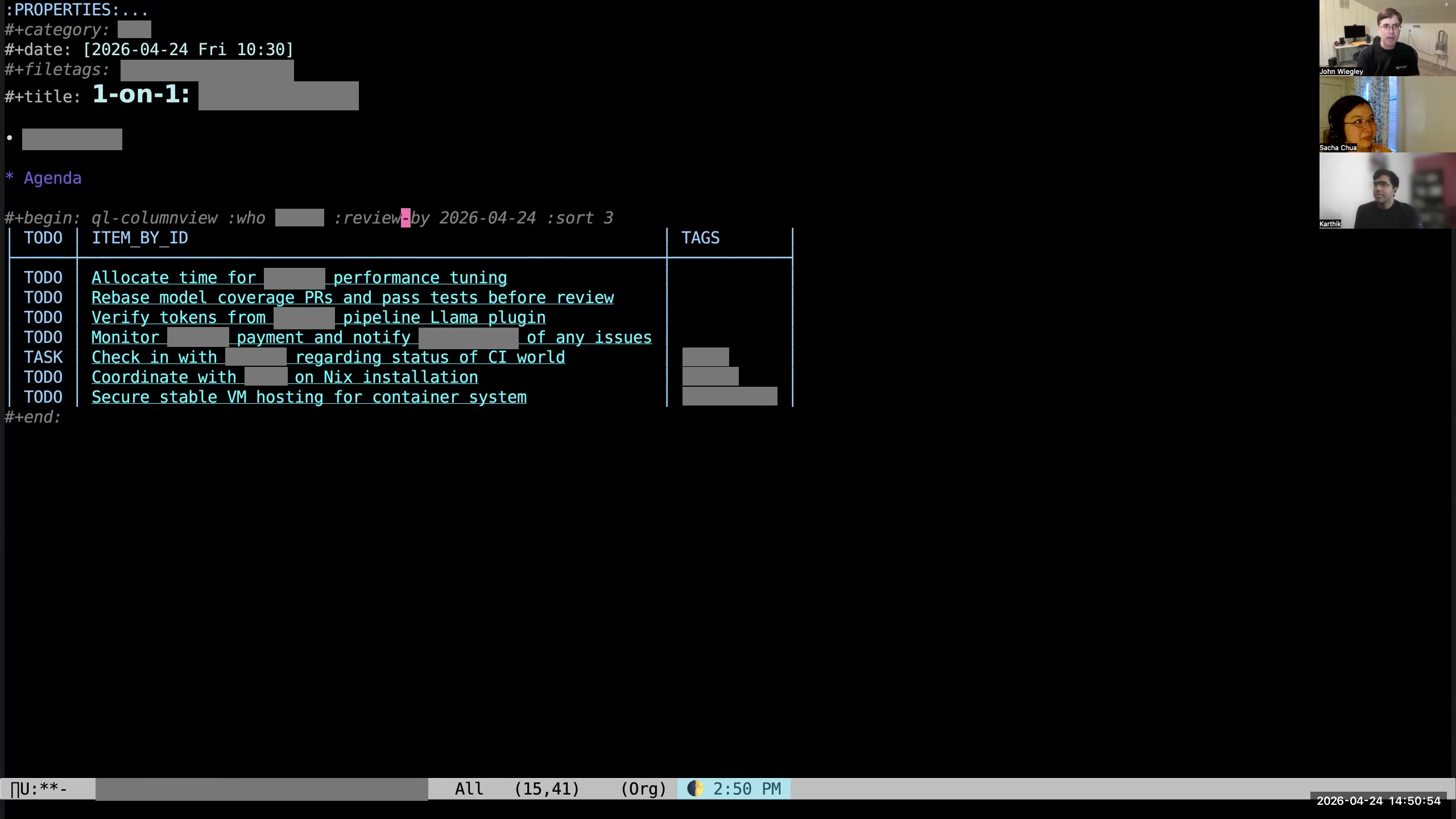 John: You can see here on this org-ql column view I have this
John: You can see here on this org-ql column view I have this :REVIEW_BY tag. That says, "If the NEXT_REVIEW date for the item is beyond this date, don't put it here. It doesn't belong in this agenda." That way, if a person says, "Oh, I'm working on this, but it's going to take me two months," I'll say, "Well, I'm going to check back with you in two months." Then I'll just set the NEXT_REVIEW for that item to be two months into the future. Sacha: And then for the ones that are there that you're reviewing, as you're sitting in the meeting with them, you're opening up the other tasks in another window and updating your status? John: Usually, yeah, I'll do this. 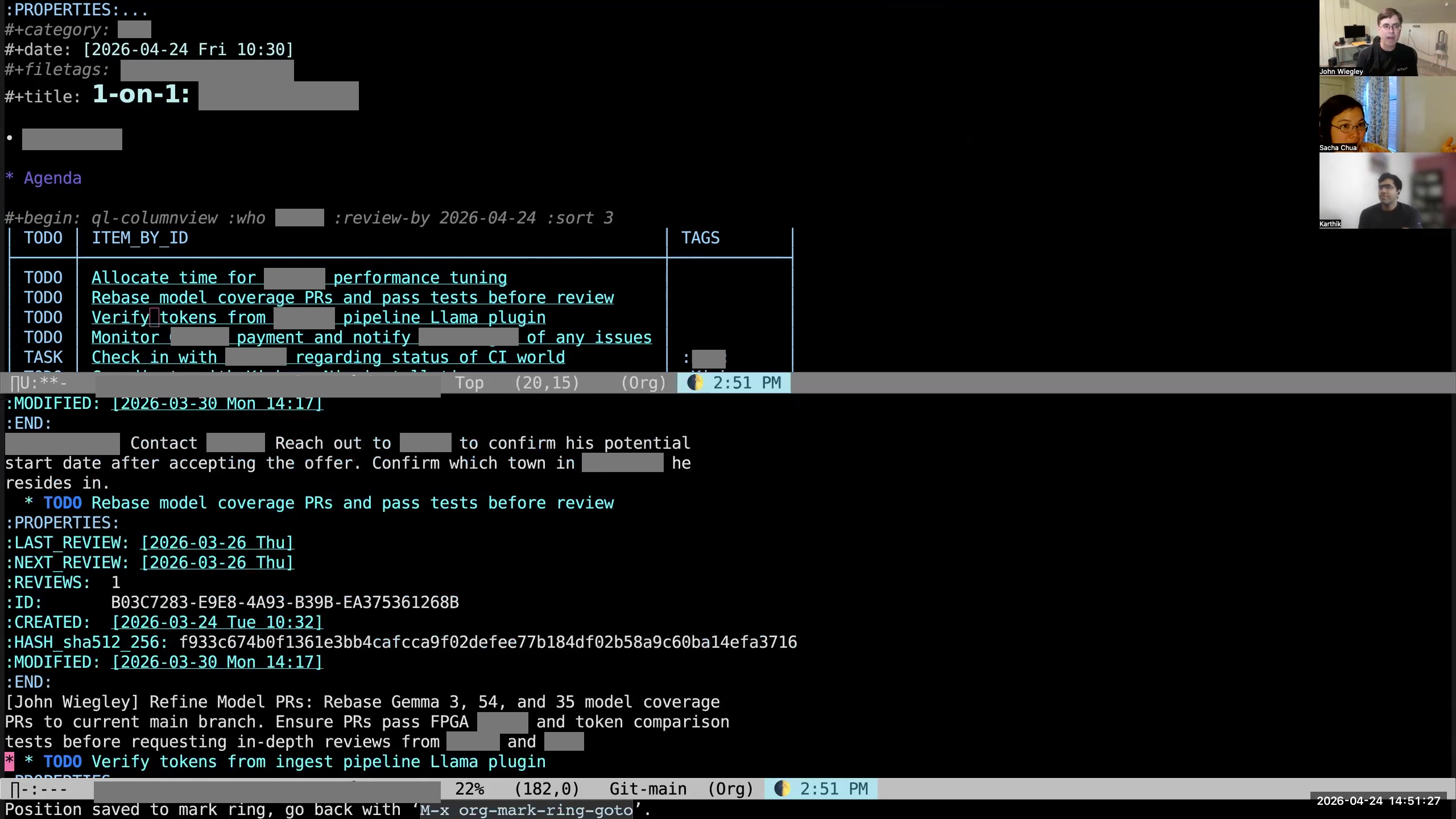 John: I'll open it up and see whether there's any supporting information. There may be links to files, links to URLs, a description.
John: I'll open it up and see whether there's any supporting information. There may be links to files, links to URLs, a description. 36:36 Copying from Slack to paste into tasks
John: I like to copy and paste from Slack into tasks. In fact, I have a whole pipeline for that. I use Slack through Firefox because Firefox has a "Copy as Org-mode" plugin. So what I do is I drag and drop over the entire conversation that I want to make a task out of. I hit Home on my keyboard, which uses Keyboard Maestro on my Mac to copy that as Org-mode, switch to the Emacs application, capture a task, insert the Org-mode Slack text that it just captured, and then run an Emacs Lisp function called org-fixup-slack, which will rewrite all of the links and all of the markup to match what I want in my Org-mode files. Then I ask Claude to review that content and synthesize a title for that to-do item for me. Then I will tag it with the person I need to work on this with— or I'll switch it from TODO to TASK, which means it's delegated to them, and then I'll tag it with their name, which means they're the ones working on it. I have to check in with them on our next one-on-one to see whether this was completed. Sacha: All right, so that's how you get external information such as Slack conversations into your notes, formatted the way that you like to format them, and into your whole agenda review meeting process. 38:13 Using gptel and large language models to generate titles and identify tasks
John: Right. And Karthik is the author of the wonderful gptel Emacs interface— that's the interface whose API I use to do the title synthesizing. I do a lot of title synthesizing. I do not write Org-mode titles. I just paste in lots of information and then ask Claude to create the title for me, because I've taught it what kind of titles I like. In fact, I could do that right now. I could go into notes, I could create a TODO here. That didn't work.  John: I could create a TODO— I'm using yasnippet to create the TODO. I have to fix my org-review today, so one second here while I make a task to fix that. Sacha: Of course. John: And that will be scheduled for today. Sacha: That sounds like a good opportunity to copy the error message, paste it in, and demonstrate how Claude will do the thing for us. John: Yeah, well, it might. I could do it this way.
John: I could create a TODO— I'm using yasnippet to create the TODO. I have to fix my org-review today, so one second here while I make a task to fix that. Sacha: Of course. John: And that will be scheduled for today. Sacha: That sounds like a good opportunity to copy the error message, paste it in, and demonstrate how Claude will do the thing for us. John: Yeah, well, it might. I could do it this way.  John: I type C-x c t — C-x c is my prefix for all things AI, and T is "make an Org-mode title." Actually, it's not using Claude, it's using my local AI. This is going to take a little bit longer. So while it does that, I'll tell you about other things. It can do it asynchronously, so I can come back here and tell you about this. So I'm here. What was I saying? What was I going to do in this file? I think I was just going to show you the creation of a TODO here. Sacha: Yeah, we were talking about copying the information from somewhere else. You've got this big paste, and then you're getting the AI to give you a title that summarizes the action item.
John: I type C-x c t — C-x c is my prefix for all things AI, and T is "make an Org-mode title." Actually, it's not using Claude, it's using my local AI. This is going to take a little bit longer. So while it does that, I'll tell you about other things. It can do it asynchronously, so I can come back here and tell you about this. So I'm here. What was I saying? What was I going to do in this file? I think I was just going to show you the creation of a TODO here. Sacha: Yeah, we were talking about copying the information from somewhere else. You've got this big paste, and then you're getting the AI to give you a title that summarizes the action item. 40:03 after-save-hook adds a TODO file tag; the TODO file tag adds it to the list of org-agenda files
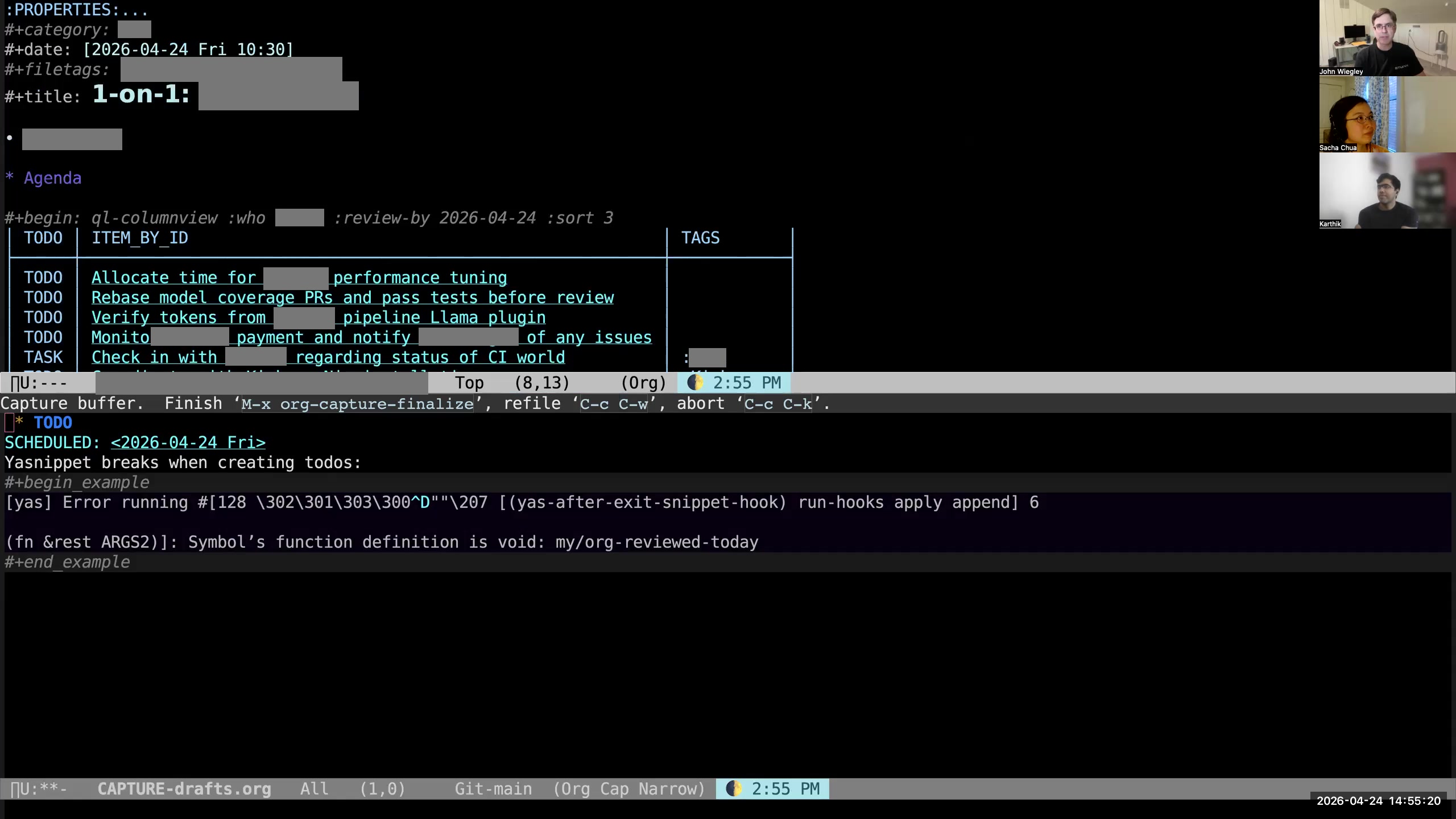 John: Since I've created a TODO, and since I saved the file (which is what caused it to then create the hash), you'll see that it has added "TODO" to the file tags. This is how the system knows to add it to the set of org-agenda files, so that the org-agenda will now get the TODOs from this file as well. Sacha: Okay, adding to the agenda. Gotcha. All right. Now, you mentioned the hash a few times. Go ahead.
John: Since I've created a TODO, and since I saved the file (which is what caused it to then create the hash), you'll see that it has added "TODO" to the file tags. This is how the system knows to add it to the set of org-agenda files, so that the org-agenda will now get the TODOs from this file as well. Sacha: Okay, adding to the agenda. Gotcha. All right. Now, you mentioned the hash a few times. Go ahead. 40:33 Reviewing the task
Karthik: If I may jump in briefly, I feel like I'm trying to catch up to an F1 car on a bike. I want to go back to the flow of that one task about writing an email to Sacha very briefly. You said you filed it and then it shows up in the list of things to review, right? What happens from there is that either you schedule it, or you just do it at some point, or you push it forward into the future. Is that right? John: Say that one more time? Karthik: The task about writing an email to Sacha that you captured and then moved into the friends category— I want to know how the task actually gets done. How are you reminded of it two weeks from now, let's say? John: Well, it'll have to show up down here in the tasks to be reviewed. Karthik: Uh-huh. John: But randomly. Sacha: Let's pretend you're scheduling it for today, because it's very important you send me an email today. So if you want to refile it to find it again, we can schedule that and you can send it in. Because I think Karthik just really wants to see the task marked done. Karthik: No, you don't even have to write an email to Sacha— Sacha: Oh, you can. Karthik: I mean, you can if you really want to. 42:04 Karthik: "Things I capture in Org never get done."
Karthik: So okay, I'll tell you the reason why I keep focusing on this. It's because everyone knows how to capture in Org, right? And then everyone also knows how to get a list of all TODOs. But things I capture in Org never get done, right? So I want to know what the mechanism is to force your hand into actually sitting down and writing this email. Of course, if it's urgent and there's a deadline, it gets done, right? But it's the things like this where, oh, it would be nice to write this email and then follow up on this. Sacha: I think the problem, as you said earlier, the problem is the human. 42:40 Grazing through tasks
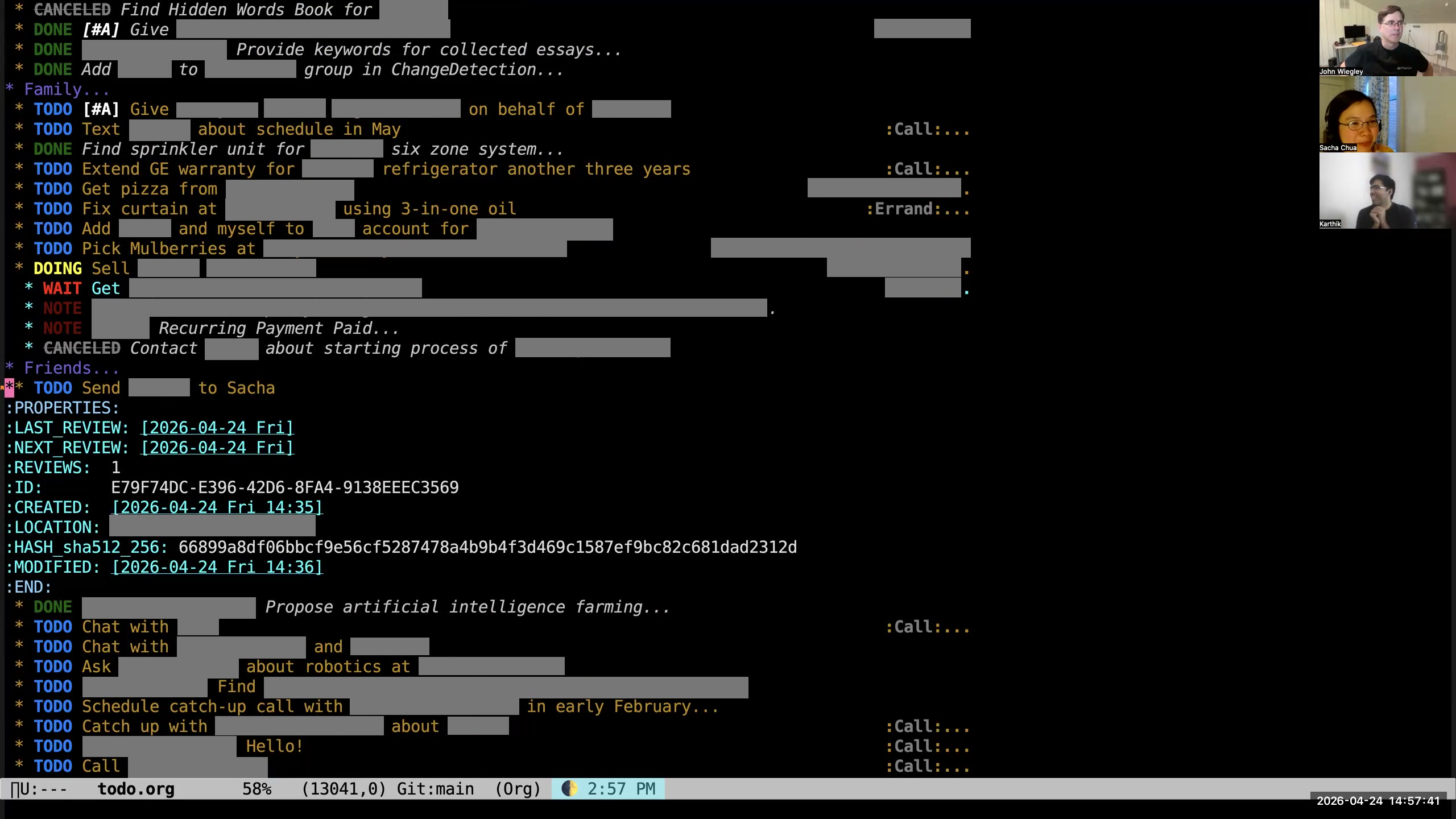 John: Yeah, the truth is it may never happen, Karthik, but it will be here as an open task. As I have time in my life, I do graze through my tasks. I cut it in different ways to try to refresh myself on what hasn't been done, and there will come a day when I will see this task again. Sacha: Okay, yeah. Anything that's got a time on it goes into the priority queue, and anything that would be nice to have goes into— someday it will show up in John's lottery of random tasks and then he'll be like, "You know, I'd rather do that task than all the other tasks. Let's do that one instead." Just a quick question, because we're coming up... John: Oh, we haven't even really scratched the surface. Sacha: I know. John: There are major, major things underneath this that I haven't even mentioned yet. Sacha: I can keep going if you can keep going. So up to you.
John: Yeah, the truth is it may never happen, Karthik, but it will be here as an open task. As I have time in my life, I do graze through my tasks. I cut it in different ways to try to refresh myself on what hasn't been done, and there will come a day when I will see this task again. Sacha: Okay, yeah. Anything that's got a time on it goes into the priority queue, and anything that would be nice to have goes into— someday it will show up in John's lottery of random tasks and then he'll be like, "You know, I'd rather do that task than all the other tasks. Let's do that one instead." Just a quick question, because we're coming up... John: Oh, we haven't even really scratched the surface. Sacha: I know. John: There are major, major things underneath this that I haven't even mentioned yet. Sacha: I can keep going if you can keep going. So up to you. 43:36 This is an advanced Org workflow
Karthik: Also, I know more than I'm letting on about John's Org workflow, right? I'm just trying to ease the viewer into it gently because— what's the goal here? I don't think that this presentation is for people newly introduced to Org-mode. John: I just don't think you can. I don't think they want my system. This is too complex. What I'm hoping is that people who already use Org-mode will cherry-pick out ideas that could advance their system a tiny bit. But nobody should do everything that I do, because I can barely survive it. It's too much information. Karthik: There's no way that I was expecting this to be a tutorial. Not at all. It's just that I want the viewer to come away from this knowing what's possible and understanding what you're actually doing. Right. Sacha: This is definitely aspirational. This is the thing that helps people think, "Oh, you know what? That's possible. Now I can go look up org-review or think about writing validation functions for my Org-mode, before-save hooks or actually after-save, that rename my files." So they can look through it. They're not going to be able to just pull the whole thing from your repository and plop it into their system right off the bat, but they can look at it for ideas, seeing how it all comes together. 45:11 Drafts: write down the text and then decide what to do with it
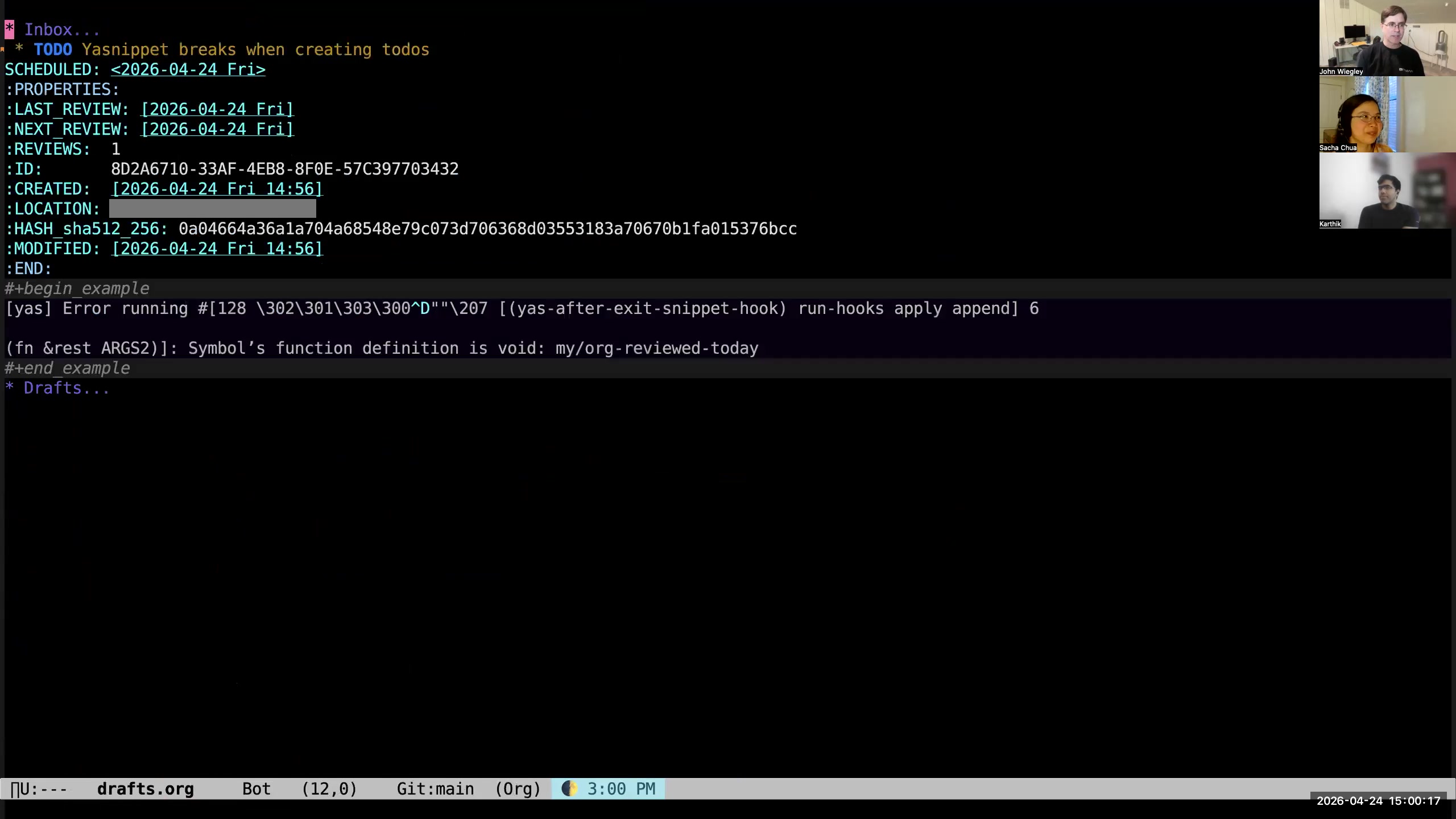 John: I mentioned that I was going to show in the drafts how I have an inbox
John: I mentioned that I was going to show in the drafts how I have an inbox  John: and a draft section. I've just recently added a new thing to my workflow, which is, instead of collecting drafts here... So what is a draft? A lot of times when I'm going to capture,
John: and a draft section. I've just recently added a new thing to my workflow, which is, instead of collecting drafts here... So what is a draft? A lot of times when I'm going to capture, 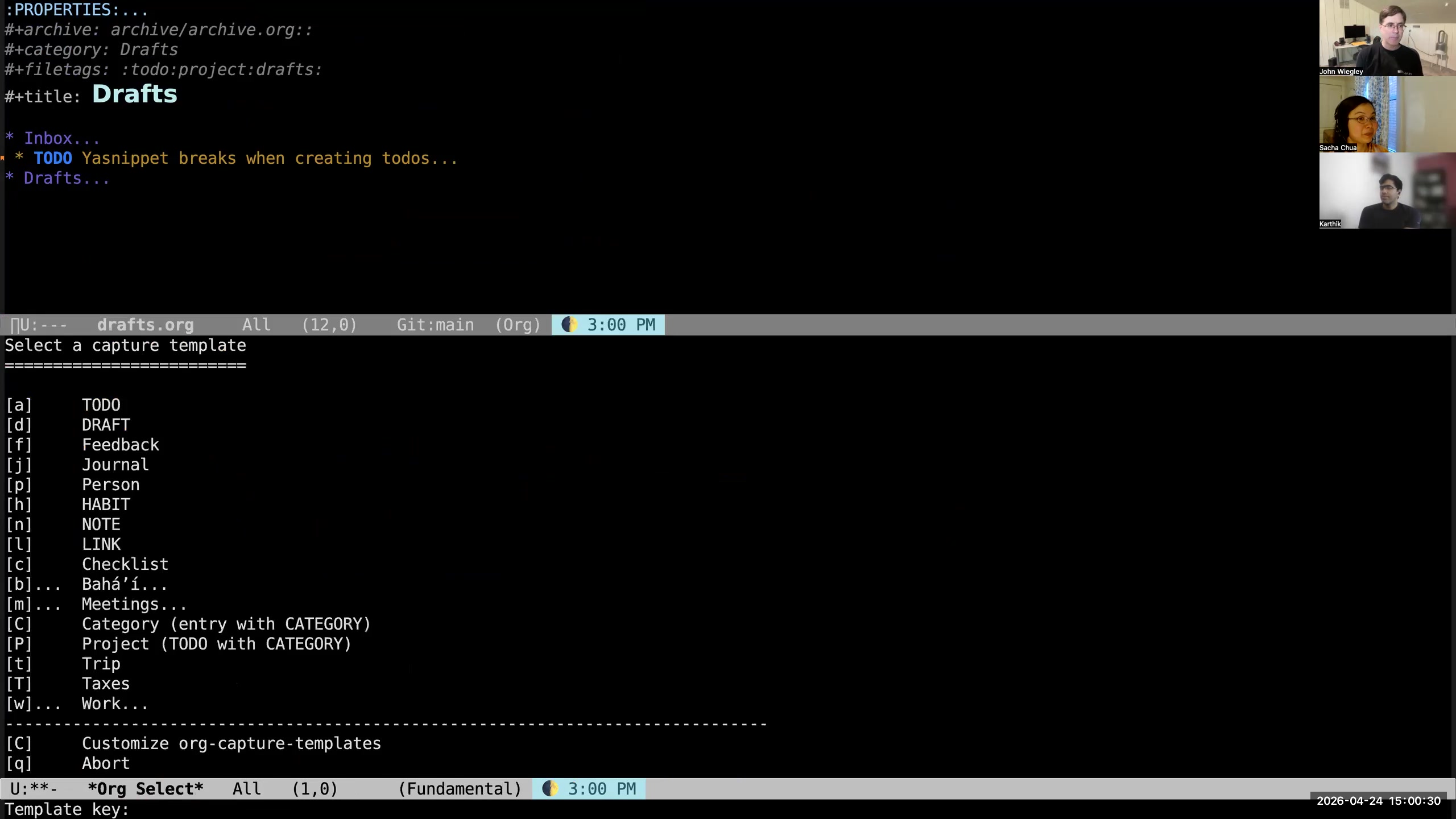 John: I hit M-m and I pick from the options of what I want to capture. That creates a template for that type of item. But sometimes that's too much thinking up front. I don't want to have to distinguish between a TODO or a note or a link or anything else. What I want is to just get the text out of my mind absolutely as fast as possible. For this purpose, I wrote org-drafts. I named it after a Mac application that I've been using for years that does exactly the same thing. Drafts lets you write first, act on the information later. In Drafts, the Mac app, you can write some text and then decide you want to send it as an email, send it as a message, send it as a WhatsApp—you know, but you shouldn't have to be thinking about the mechanism of action when you first just want to think about the creative act. I have changed it so that, instead of just M-m,
John: I hit M-m and I pick from the options of what I want to capture. That creates a template for that type of item. But sometimes that's too much thinking up front. I don't want to have to distinguish between a TODO or a note or a link or anything else. What I want is to just get the text out of my mind absolutely as fast as possible. For this purpose, I wrote org-drafts. I named it after a Mac application that I've been using for years that does exactly the same thing. Drafts lets you write first, act on the information later. In Drafts, the Mac app, you can write some text and then decide you want to send it as an email, send it as a message, send it as a WhatsApp—you know, but you shouldn't have to be thinking about the mechanism of action when you first just want to think about the creative act. I have changed it so that, instead of just M-m, 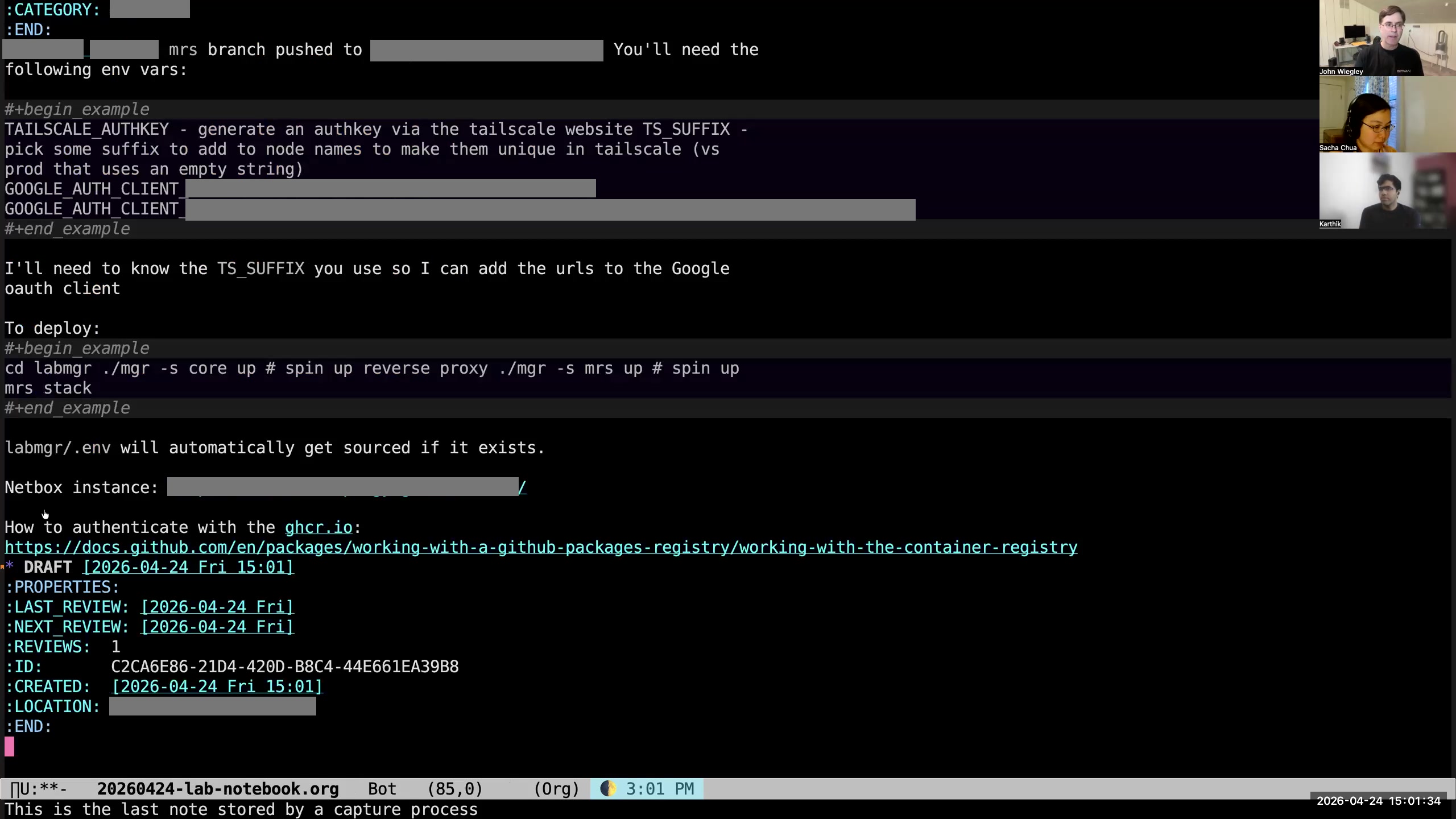 John: if I do M-S-m, it creates a draft. It used to create the draft using the org-capture interface, and then it would go into that drafts subheading in my drafts.org file. But now what it does is it goes into my lab notebook.
John: if I do M-S-m, it creates a draft. It used to create the draft using the org-capture interface, and then it would go into that drafts subheading in my drafts.org file. But now what it does is it goes into my lab notebook. 46:47 My lab notebook collects notes and ideas throughout the day
John: So the lab notebook is where I want to collect notes and ideas throughout the day. I don't know that I want it to be in the lab notebook— the point is, I don't want to think about it. So when I do M-S-m, then what it does is it creates a draft instantly at the bottom of my lab notebook, and it puts me in the body of that draft to write it. So I could then say, "Send an email to Sacha." That's all I have to do. I don't have to hit C-c C-c. I don't even have to save the file. I could just go straight on to what I was doing. But the idea with org-drafts is that, once you have written a draft, now or at any time in the future, you're going to want to act on that draft in some way. 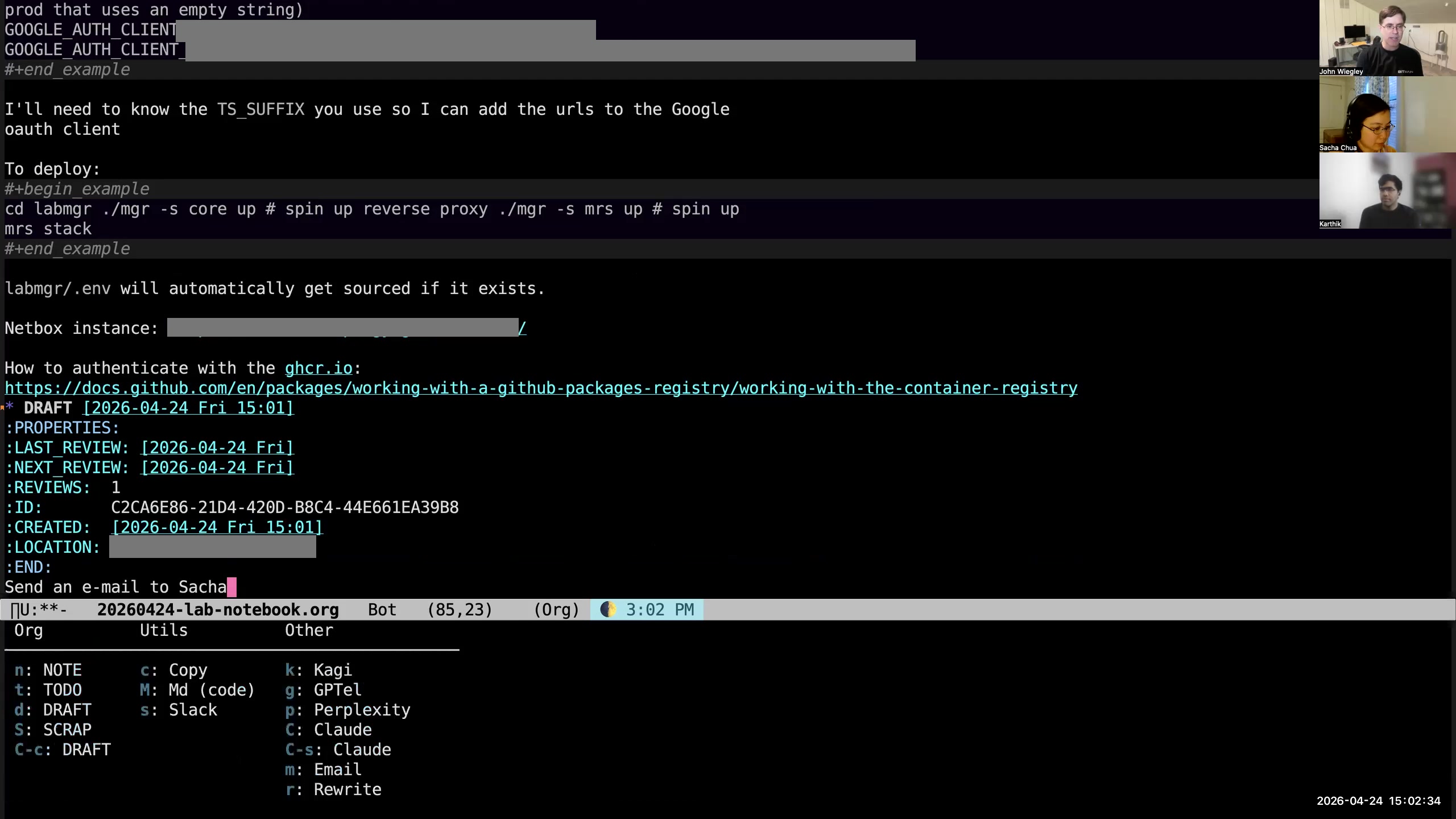 John: So if I hit C-c C-c, it pops up a little submenu of things I can do with this draft.
John: So if I hit C-c C-c, it pops up a little submenu of things I can do with this draft. 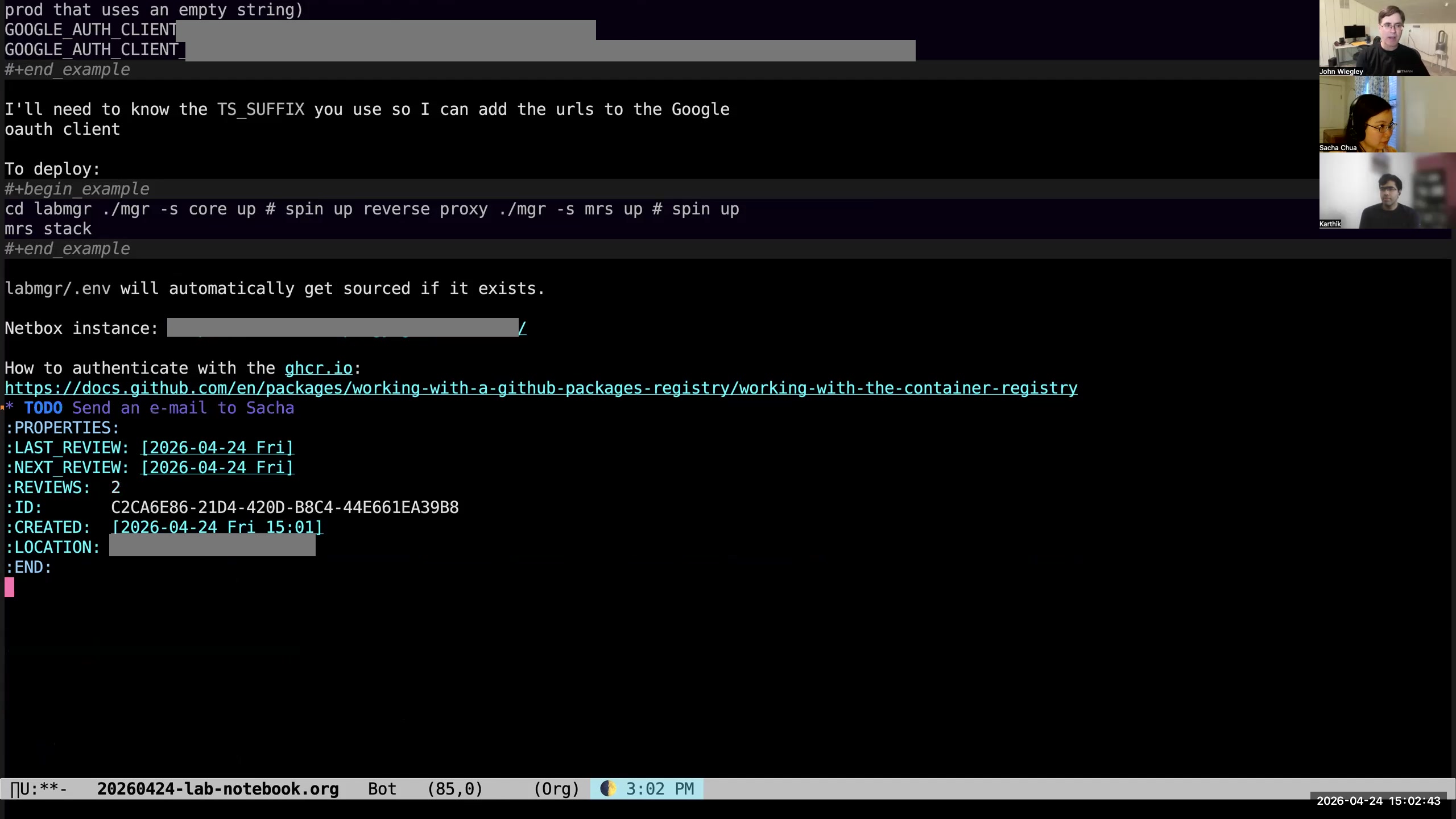 John: If I hit t, it'll take the first line of the body of the draft and turn it into a TODO with that line as the title of the TODO.
John: If I hit t, it'll take the first line of the body of the draft and turn it into a TODO with that line as the title of the TODO. 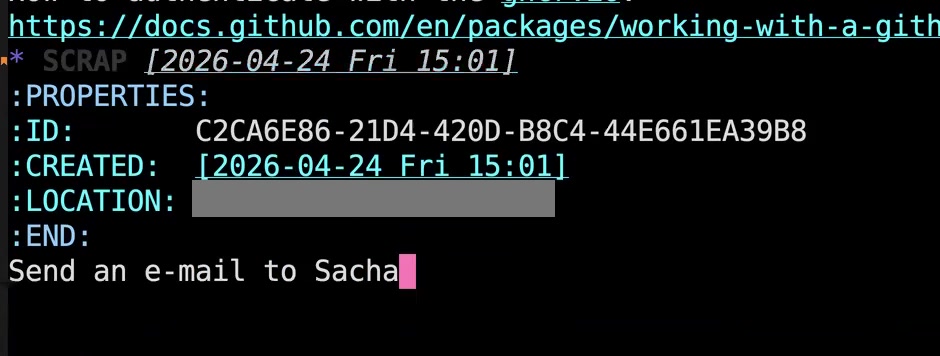 John: If I hit C-c C-c c, it will copy the body of the draft onto my clipboard and then change the keyword of the draft to SCRAP. SCRAP is just a keyword that I use to identify drafts that I don't need to act on anymore but I like to keep the information. Maybe I want the information in the future.
John: If I hit C-c C-c c, it will copy the body of the draft onto my clipboard and then change the keyword of the draft to SCRAP. SCRAP is just a keyword that I use to identify drafts that I don't need to act on anymore but I like to keep the information. Maybe I want the information in the future. 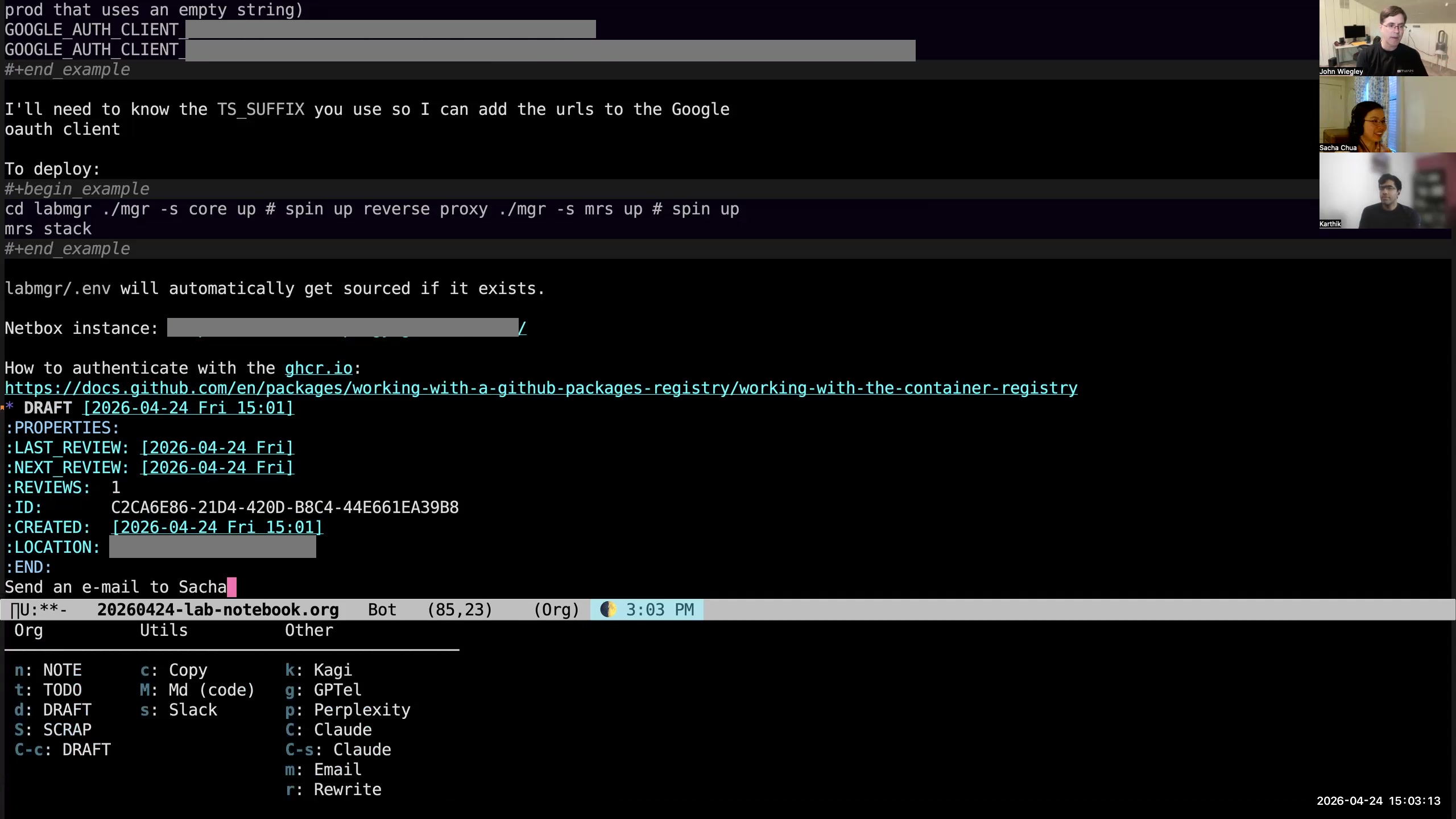 John: Another thing I can do with it: I could do C-S-c, and what that will do—you don't see it because it didn't show up there— but it starts up a webpage into Claude.ai and inserts the body of the draft as the text to submit for the prompt to that webpage. This is extensible. You can add new actions to this. I can draft an email with this. I don't have it set up to send Apple Messages, but I could. I could set up that interaction as well. This is now a preferable way for me to collect ideas and thoughts and notes throughout the day. So when I'm using Claude Code, which is what I'm generally using, and I write a really long prompt and I think, "I may want to use that prompt again in the future," I will copy and paste it and then make it a draft, and not do anything with it. Actually, I just turn it into SCRAP right away with another keybinding, but I want to retain it within my lab notebook so that I can use other forms of search, which I'm going to talk about in a moment, to try and recover that information and find it later.
John: Another thing I can do with it: I could do C-S-c, and what that will do—you don't see it because it didn't show up there— but it starts up a webpage into Claude.ai and inserts the body of the draft as the text to submit for the prompt to that webpage. This is extensible. You can add new actions to this. I can draft an email with this. I don't have it set up to send Apple Messages, but I could. I could set up that interaction as well. This is now a preferable way for me to collect ideas and thoughts and notes throughout the day. So when I'm using Claude Code, which is what I'm generally using, and I write a really long prompt and I think, "I may want to use that prompt again in the future," I will copy and paste it and then make it a draft, and not do anything with it. Actually, I just turn it into SCRAP right away with another keybinding, but I want to retain it within my lab notebook so that I can use other forms of search, which I'm going to talk about in a moment, to try and recover that information and find it later. 49:17 org-jw: normalizing structured data
John: I said that Org-mode is text, and that is a strength of Org-mode. It is also a weakness of Org-mode, because really Org-mode is a database— but it is a super-unstructured database. I have spent more than a year now layering a system on top of Org-mode I call org-jw, simply because it is so specific to my workflow that I didn't think it would ever be of general use. What org-jw is, is a separate Haskell application that parses Org-mode files into an internal representation in memory of those files that's entirely complete. When I say "entirely complete," I mean that if I take that in-memory representation and write it back out as an Org-mode file, it is byte-for-byte identical to the Org-mode file that went in. It checks this property by doing a round trip. If the file fails the round trip, it raises an error saying your data is not conformant. I make this a pre-commit hook before anything can be committed to Git as a change to my Org-mode files, to ensure that if it's in Git, it is normalized. This fully normalized data now is accessible in new ways. I wrote a whole linting process that checks hundreds of different properties of my Org-mode data to make sure that those properties are always maintained. For example, if there is a URL property in an entry, it must have a "link" tag, and vice versa. Those two things have to go together, because the link tag is there to be a reminder to me that there is a URL and it would be meaningful to use C-c C-o on that entry. Likewise, I don't want it to have a link tag but not have a URL. The two always have to come together. There are a whole bunch of linting rules that I have, but they're all specific to me and how I like to use Org-mode. 51:17 Copying structured Org data into a PostgreSQL database
John: Another thing org-jw does, now that it has this internal memory representation, is it can write all of that data out to a highly relational database. So it's, I think, a third-normal-form or fourth-normal-form Postgres database that collects all of the information. When I say third normal form, I mean that tags are in their own table, categories are in their own table—every little piece of information is in its own table. Then there are correlating tables. So each entry is identified by its UUID, and then the tag knows what entry it goes with by basically referencing that UUID. All the data is interlinked like this. In addition to storing the data in this database—and this is the text of every property, the text of every note, the text of all the body paragraphs, everything is in there—because all of that data is now so nicely structured within the database, Postgres has the ability to do vector search. Anyone that's been playing in the AI space knows about vector search. When I use org-jw to reflect all entries that have recently changed back into the Postgres database, I also use an AI model to calculate a vector embedding for every piece of text that's related to every entry. These get stored as vectors in Postgres, so that later I can ask the database, "Show me entries that are related to a leak that I'm searching for in my pool." It will search for that semantically within the database, and it will find me everything that is in the area of pools and leaks and all of that kind of thing. This is very effective. I can do it on the command line with org-db-search—that’s the name of the command that I run to do this. 53:12 OpenClaw enables conversations with the data
John: But I also taught OpenClaw how to use this tool. So OpenClaw is an AI agent that will do work on your behalf. I have it linked up to a local LLM that I run, and I get to talk to it over Discord. It's really locked down— I have it all bound within its own Linux microVM so that it can't really do anything but the few capabilities I've given it. But what it means is that, when I'm on the airplane, I can use my phone and my WhatsApp or my Discord app, and I can say, "What tasks do I have coming up in the next week that involve calling somebody?" Then it can do both a full-text search, a structural search for tasks, and also a vector embedding search to find similarity. So I could ask OpenClaw, "Do I have anything coming up having to do with Christmas ornaments?" and it will find for me the items that deal with Christmas ornaments. What this has all done, by starting with Org-mode and then creating basically what I call "strict Org-mode" or "structured Org-mode," from that creating a database, from that creating these vector embeddings, and then from that tying it into an AI agent, I now have the ability to dialogue with my data. I can ask my whole entire Org-mode sea of data questions like, "What problems at work have I not been paying much attention to lately?" and it can give me an answer. Then I can query that answer and refine it further. I can say, "Well, do any of those have to do with this project?" or, "Do they seem like they're very high priority?" I can keep going until I get to a more refined set of items that represent a focus for the day, as an alternative to using the scheduled dates and the org-agenda reports. But I also have an org-agenda report which does a vector query. They all tie together, so I can do it from whatever direction. If I say, here, "org-semantic-search," and then say "go out for a coffee with Karthik," what it will do is run the org-db-search command-line tool and then feed the data into an org-agenda query. Sacha: So I'm hearing: you've got your Org plain-text data, you make sure that it's all formatted nicely using your normalization functions, you take that and put it into a structured PostgreSQL database, which then allows you to do a full-text search as well as vector search. Then you take that and you hook an AI into it through something like OpenClaw, so then you can have conversations. Even when you're away from your computer, you can query it for stuff and do something with the results. Even just the semantic search is something I'm very interested in because it's hard to find things if you need exact word match, so this is great for being able to find stuff that's related to something without having to worry about making sure you've got the right words in it. John: Right. Karthik: This is like five levels of crazy, each building on another. John: Yeah, it's all about making this data work for me. I've spent all this time collecting it—how can I make this data work for me? I don't know why the CLI search is not working. It might be some problem with the local model. So many changes. So many. Yeah, it's the demo phenomenon. Also, so many things change in my environment so fast that, unless I use things constantly, they easily break. 56:49 Avoid drift by using only one TODO system
 Sacha: Which actually is an interesting thing that touches on the conversation that Karthik and I were having before you joined. How do you keep the ideal of your tasks or whatever synchronized with the reality of your current focus, or the things that have broken or changed? Karthik: Yeah, it's the drift. I call it the drift problem, where the state of your life—well, the portion of your life that you want to capture in this case in Org—has drifted from what's actually happening. Then when you look at your agenda, you go, "No, this is not relevant to me anymore. The things that are bothering me right now are not here." So it's like the Venn diagrams—I mean, the two blobs—the overlap is getting smaller and smaller. So is that a problem you have, and if you do, how do you deal with it? John: I deal with it by not using any other systems but Org-mode. So you have to always be in Org-mode, seeing that data somehow. You have to just be interacting with it to combat that drift constantly. You can't have even two to-do lists. For me, even just one other to-do list makes the drift unmanageable. So if somebody puts something for me on another to-do list, I'll make an Org-mode task and I'll put a link to that to-do list. It has to be in Org-mode. Sacha: Do you sometimes find yourself— go ahead. Karthik: What about the to-do list in your mind? John: I don't keep a to-do list in my mind. Karthik: You don't have a to-do list in your mind. Sacha: I was just saying, as we saw earlier, if you do come across—if there's a thought and it's not in your current review list and it's not in your current agenda, your semantic search and your org-ql will help you find that thing relatively quickly, I think. John: Yeah, if it's in the Org-mode file anywhere, a combination of either ripgrep or Postgres full-text search or semantic search, there will be a way to find it. Then if it's not in there, I just use the capture interface to put it in there.
Sacha: Which actually is an interesting thing that touches on the conversation that Karthik and I were having before you joined. How do you keep the ideal of your tasks or whatever synchronized with the reality of your current focus, or the things that have broken or changed? Karthik: Yeah, it's the drift. I call it the drift problem, where the state of your life—well, the portion of your life that you want to capture in this case in Org—has drifted from what's actually happening. Then when you look at your agenda, you go, "No, this is not relevant to me anymore. The things that are bothering me right now are not here." So it's like the Venn diagrams—I mean, the two blobs—the overlap is getting smaller and smaller. So is that a problem you have, and if you do, how do you deal with it? John: I deal with it by not using any other systems but Org-mode. So you have to always be in Org-mode, seeing that data somehow. You have to just be interacting with it to combat that drift constantly. You can't have even two to-do lists. For me, even just one other to-do list makes the drift unmanageable. So if somebody puts something for me on another to-do list, I'll make an Org-mode task and I'll put a link to that to-do list. It has to be in Org-mode. Sacha: Do you sometimes find yourself— go ahead. Karthik: What about the to-do list in your mind? John: I don't keep a to-do list in my mind. Karthik: You don't have a to-do list in your mind. Sacha: I was just saying, as we saw earlier, if you do come across—if there's a thought and it's not in your current review list and it's not in your current agenda, your semantic search and your org-ql will help you find that thing relatively quickly, I think. John: Yeah, if it's in the Org-mode file anywhere, a combination of either ripgrep or Postgres full-text search or semantic search, there will be a way to find it. Then if it's not in there, I just use the capture interface to put it in there. 58:59 Capturing with Drafts on the Mac or Apple Watch
John: Oh, by the way, I also should mention how I capture. I've been showing you Org-mode commands to capture, but that's not actually how I typically capture tasks. I use the Drafts app on macOS, as I mentioned, and I have it set up so that in the Drafts app, if I hit C-c, it will write the item that I captured in Drafts to a file that Org-mode will turn into a task the next time I run any agenda command. So I have something that's the after-agenda, the before-agenda setup hook. Let me do that. I'll go over to my Mac and I'll say, "Send an email to Sacha." I'll then submit it. It goes to iCloud Drive, gets synced to all my machines. 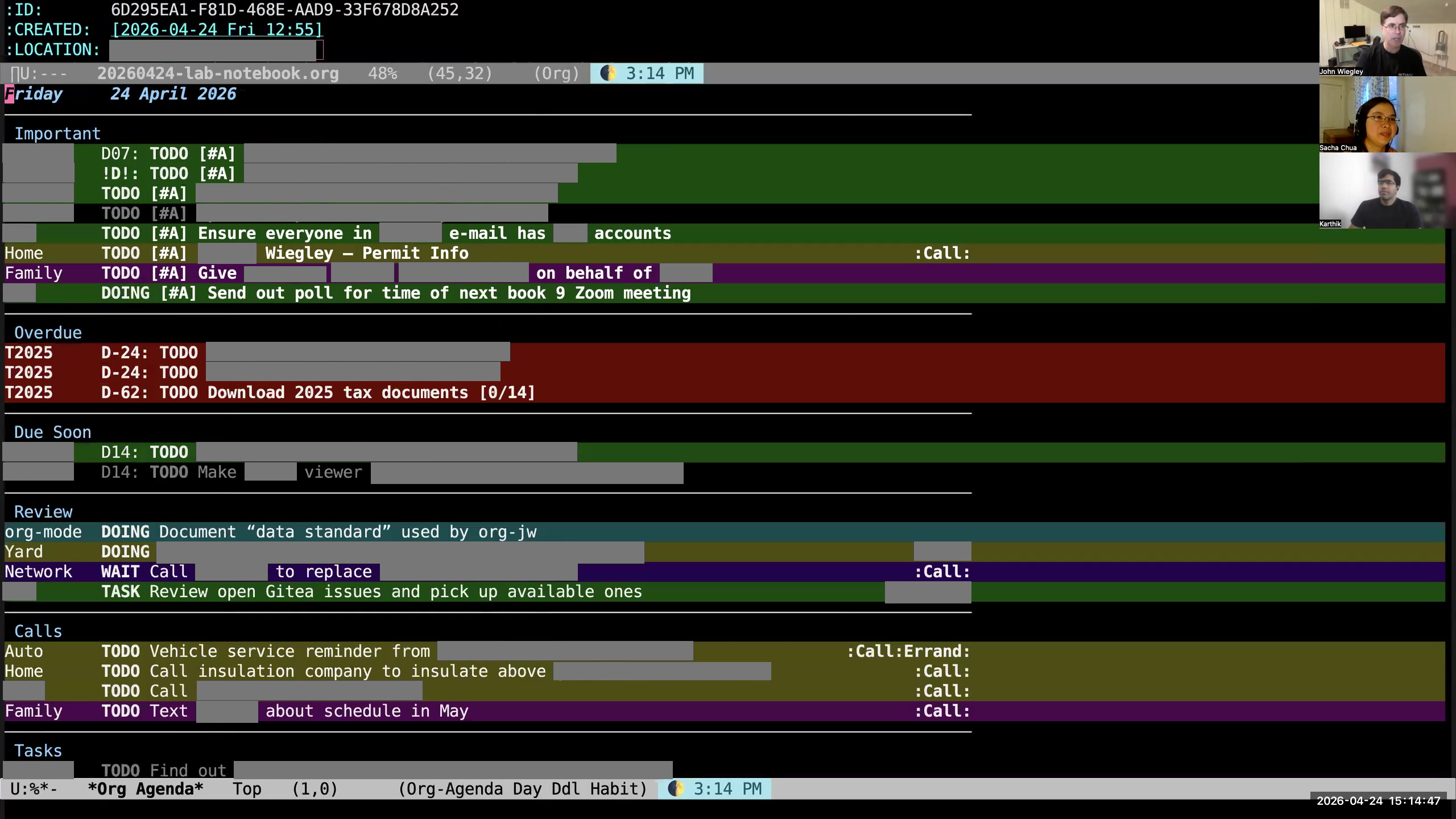 John: Now I'll regenerate my Org-mode agenda. And now here it is—this fuchsia guy just came in from the Mac Drafts app. The Drafts app on the Mac runs on my phone and it runs on my watch. So what I do to create tasks is I tell my watch— I just talk to Siri and I say, "Remind me to do such-and-such." Then the Drafts app knows to automatically suck in anything that's on my Reminders list, and that ends up becoming something that's auto-sucked into Org-mode. This way I use voice to capture things as they happen wherever I am. I don't have to have my computer. I don't even have to have my phone. I just need my watch at the very least, and I'm capturing tasks by voice like this, dozens of them a day. This is probably the most frequent way that I do it. Oh, and also, I taught OpenClaw how to add stuff to Drafts. So I can also ask OpenClaw via Discord, "Hey, remind me to do such-and-such." But why do that? I just did it as an alternate way. I prefer to do it with my watch. Sacha: Yeah, just because you can.
John: Now I'll regenerate my Org-mode agenda. And now here it is—this fuchsia guy just came in from the Mac Drafts app. The Drafts app on the Mac runs on my phone and it runs on my watch. So what I do to create tasks is I tell my watch— I just talk to Siri and I say, "Remind me to do such-and-such." Then the Drafts app knows to automatically suck in anything that's on my Reminders list, and that ends up becoming something that's auto-sucked into Org-mode. This way I use voice to capture things as they happen wherever I am. I don't have to have my computer. I don't even have to have my phone. I just need my watch at the very least, and I'm capturing tasks by voice like this, dozens of them a day. This is probably the most frequent way that I do it. Oh, and also, I taught OpenClaw how to add stuff to Drafts. So I can also ask OpenClaw via Discord, "Hey, remind me to do such-and-such." But why do that? I just did it as an alternate way. I prefer to do it with my watch. Sacha: Yeah, just because you can. 1:01:01 A foot pedal makes speech-to-text even more convenient; whisperflow, handy
Sacha: As I was mentioning, voice computing—just speech-to-text— is very interesting because it allows you to capture your thoughts so much faster than typing. So I was wondering if you're using any of that in your drafts, not just for quick tasks that you're capturing from your phone, but when you're at your computer, are you using that at all yet? John: Yes. In fact, I am using it so much that I bought a foot pedal for myself. Sacha: Yeah? John: Yeah. I use two different apps. I use one that's commercial called WhisperFlow that sends your voice out to the internet and uses their AI models. First they transcribe it, and then they process it— they remove all the uhs and the ums and they rewrite it into correct grammar and all that kind of stuff. That's extremely fast, so usually when I'm talking to Claude and prompting it, I'm prompting it by voice using my foot pedal. That's the right pedal. The left pedal uses a free open-source app called Handy. Handy uses a local transcription model, which I use Whisper Transcribe for, because it's super fast and super accurate. Then I use Qwen 3.5 9-billion-parameter as my local LLM model to post-process the transcription, so that it does the same things that WhisperFlow does. It can accomplish everything WhisperFlow does; it just takes about ten times as long to do it. Sometimes I don't like that delay in the flow. But it's also entirely open source and entirely local, so I know that whatever I'm transcribing, none of that data is going out to any third-party services. Sacha: Fantastic. Okay, so that gets you— when you're brain-dumping a whole bunch of things into a prompt for an AI or into your notes before a meeting or whatever, you can just blurt a lot of information and the AI will clean it up nicely and make it more presentable. John: Let's do this. "Send an email to Sacha." Now, it just finished transcribing. Transcribing only takes like half a second, but now it's processing. It may take longer the first time because that 9-billion-parameter model may not be currently loaded—I had to reboot my machine recently. Karthik: Sacha, you're going to get so many emails. Sacha: I don't know, it's fine. It's fine. I get emails sometimes. Go ahead. John: Oh, there we go. So it said, "Send an email to Sacha." It nicely added a period at the end of it. Sacha: Yeah. John: Let's see. Now that it's warmed up, let's do a longer one. "This email should say something about Org-mode and it should be related to the conversation that we all had on our Zoom call together." You could hear that I had— I don't know if you heard me, but I had some uhs and ums in that.  John: But this is what it came out with. The only thing it didn't know how to do was put a hyphen between "Org" and "mode." I have complete control with Handy over the post-processing prompt. In the post-processing prompt, I can give it an Emacs section and tell it about vocabulary that's special to Emacs that I want it to be aware of. I've done that for all of my work topics, but I haven't done it for the Emacs topics. Sacha: I have something similar where I do the post-processing of the speech-recognition output in Emacs, so I can just run a list of functions on it, including fixing common errors and processing speech commands. So I'm gradually playing around with that too. John: It's invaluable. The other nice thing about voice transcription is that you end up saying more than you type, because I think we just naturally economize— typing takes more energy. When I talk, I'm just a blabbermouth and I end up giving all this information that ends up being better for AI. In fact, they've shown that if you just add 40 more periods at the end of your sentence, that improves the quality of your response, because all of those additional tokens cause attention to be recomputed for the existing tokens many, many more times, and that computation helps it find its way through the feed-forward networks more accurately. So more text is actually better, especially when you're only talking about maybe 20% longer due to voice transcription. So I prefer to talk to AIs through voice. What I do is I like to create—let's see here— I like to create the body of the TODO using voice transcription, and then after that I like to create the title using AI as well. Now that it's warmed up, it should not take quite so long.
John: But this is what it came out with. The only thing it didn't know how to do was put a hyphen between "Org" and "mode." I have complete control with Handy over the post-processing prompt. In the post-processing prompt, I can give it an Emacs section and tell it about vocabulary that's special to Emacs that I want it to be aware of. I've done that for all of my work topics, but I haven't done it for the Emacs topics. Sacha: I have something similar where I do the post-processing of the speech-recognition output in Emacs, so I can just run a list of functions on it, including fixing common errors and processing speech commands. So I'm gradually playing around with that too. John: It's invaluable. The other nice thing about voice transcription is that you end up saying more than you type, because I think we just naturally economize— typing takes more energy. When I talk, I'm just a blabbermouth and I end up giving all this information that ends up being better for AI. In fact, they've shown that if you just add 40 more periods at the end of your sentence, that improves the quality of your response, because all of those additional tokens cause attention to be recomputed for the existing tokens many, many more times, and that computation helps it find its way through the feed-forward networks more accurately. So more text is actually better, especially when you're only talking about maybe 20% longer due to voice transcription. So I prefer to talk to AIs through voice. What I do is I like to create—let's see here— I like to create the body of the TODO using voice transcription, and then after that I like to create the title using AI as well. Now that it's warmed up, it should not take quite so long. 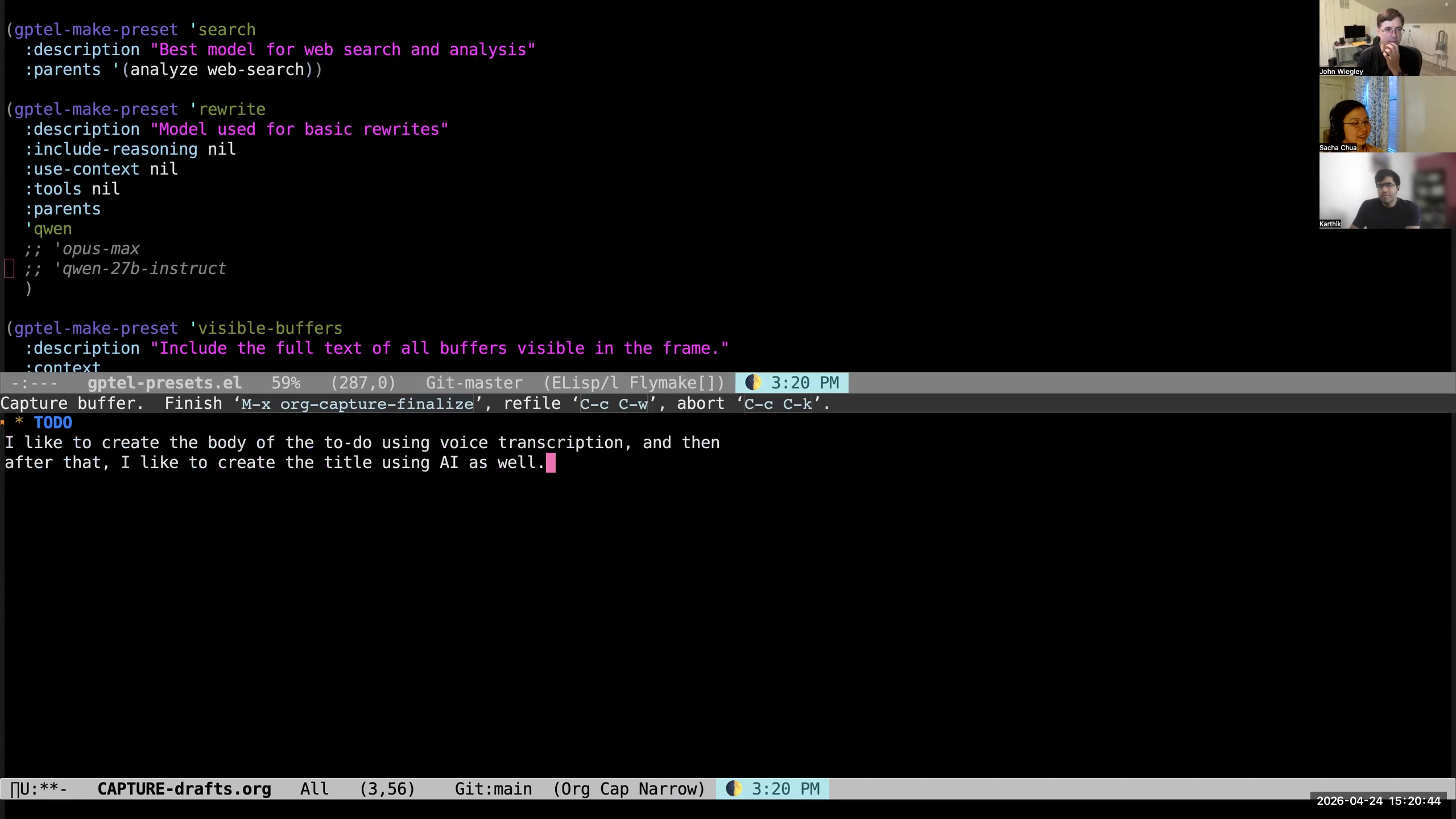 John: There we go. We will just say to Qwen— that was Qwen 9B giving me the transcription— now we're going to use Qwen 27B to give me the title. It may not be warmed up as well. I try to keep four different models always loaded so that they'll be quick to respond, but as I said, I had to reboot the machine recently. Sacha: All right. So you've got your outline for focus and your home, they have the blocks in it, you can use that to drill down into whatever subset of your tasks. You also have your agenda with the reviews. You can go into any of those tasks, use AI to fill out the text based on your speech recognition, or you can send it to Claude or other AI for executing the task, for all that stuff.
John: There we go. We will just say to Qwen— that was Qwen 9B giving me the transcription— now we're going to use Qwen 27B to give me the title. It may not be warmed up as well. I try to keep four different models always loaded so that they'll be quick to respond, but as I said, I had to reboot the machine recently. Sacha: All right. So you've got your outline for focus and your home, they have the blocks in it, you can use that to drill down into whatever subset of your tasks. You also have your agenda with the reviews. You can go into any of those tasks, use AI to fill out the text based on your speech recognition, or you can send it to Claude or other AI for executing the task, for all that stuff. 1:06:39 Looking to the future
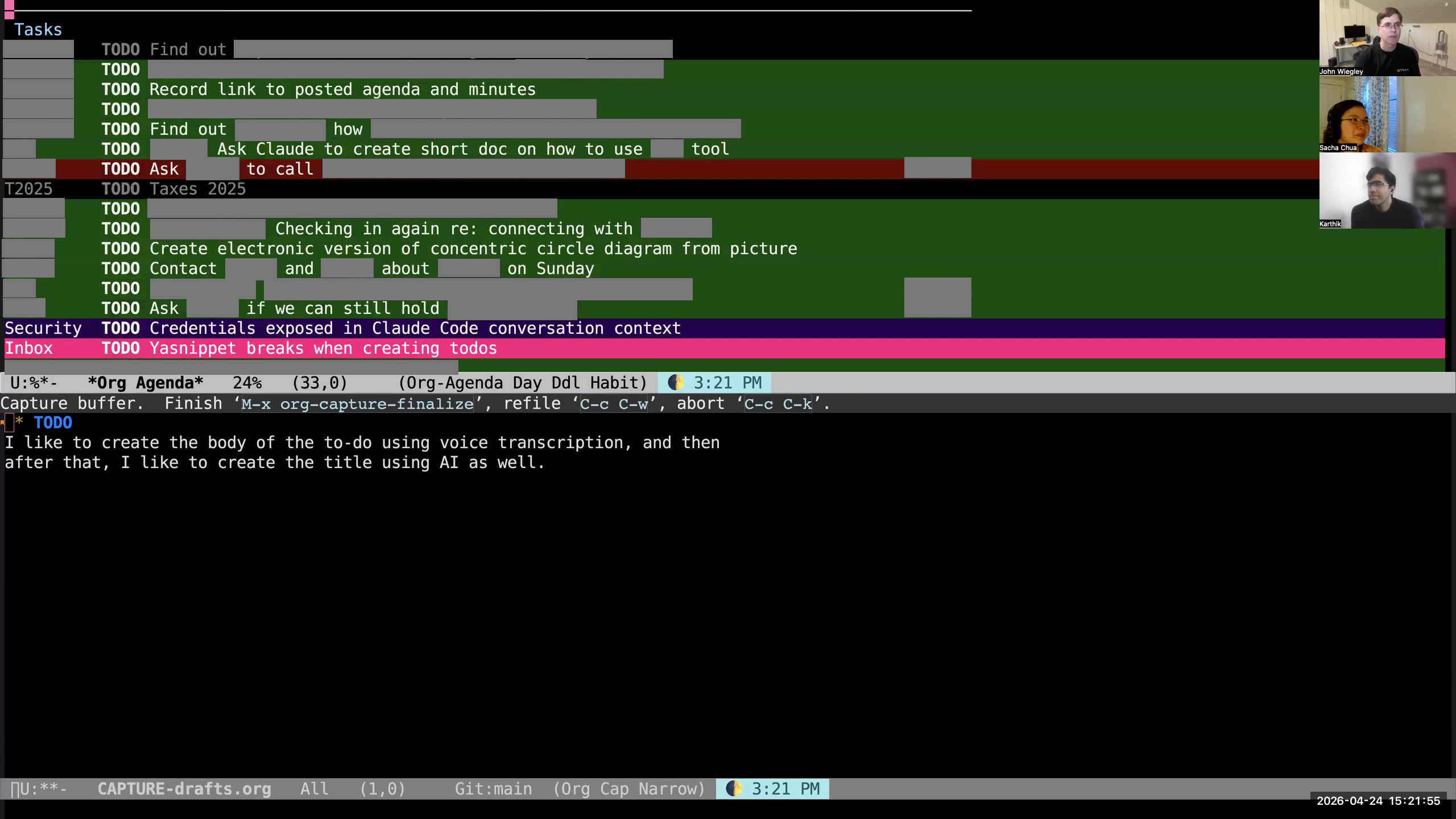 Sacha: If you're looking three to six months out, your workflow is pretty polished, but where do you want to take it? What are your future needs that you'd like to work towards? John: I just need to be able to get these big old long lists shorter. That's all I want to say. Sacha: Yeah, that is a getting-things-done thing, not a tooling thing, right? John:
Sacha: If you're looking three to six months out, your workflow is pretty polished, but where do you want to take it? What are your future needs that you'd like to work towards? John: I just need to be able to get these big old long lists shorter. That's all I want to say. Sacha: Yeah, that is a getting-things-done thing, not a tooling thing, right? John:
Yeah. Atomic Habits, I think, helped me more
than anything else in the way that I break up tasks. 1:07:07 John is running local models on a Mac Studio
John: I'll give you another AI example here. For some reason, Qwen is not working. Let me check my OMLX— I use OMLX these days for running. Karthik: So you're running all these local models on a Mac Studio? John: Yes. Karthik: Okay. John: Oh, it looks like OMLX might not be running. No, I have it. Karthik: Okay. In the meantime, I had a question about the whole database mirror of your corpus. John: Okay, sorry, one sec. The reason it wasn't working is because I'm also working on another AI-powered app for doing stock analysis, and it was taking over the port. So what was your question? 1:08:12 Using AI to facilitate getting data into PostgreSQL; structural limitations?
Karthik: Yeah, so the question was: you have a mirror of your Org corpus in Postgres, right? I was thinking, one of the reasons that people like Org-mode is because it's easier to work with as text, but also because it's flexible. So you can set up whatever system you want corresponding to whatever schema in the database. You can also change it easily because it's just text, right? But your Org subset specification, by your own admission, is rigid, right? You've settled on it for now, and that's why you can have a database that's like this with a one-to-one connection. What happens if you change something? Like if you change what a category means or if you add more things, you have to then update all the tables in the database and update the schema. You have to do a migration of the database. John: Yeah, but I just have AI do that for me. I didn't create a schema. I didn't even create the code that did the Postgres migration. That was all written for me. Karthik: I suspected that, yeah, that's probably what you do. You don't worry about it. That is neat, the idea that you can have all the flexibility of Org-mode—flexibility to change things, change the system as your needs change—and then also have the database do all the things it does, like very fast search, semantic search. You get all of that for free, if you have someone who can go and change the database when you change your Org system, if you have someone who can do that for you. Sacha: It actually prompts me to think of this question I had about stuffing the Org entries into the database. Let's say, for example, you have an Org tree and you have sub-entries within it that you also want to be able to work with on a more granular basis. If you have subheadings, how do you like to put it in your database? Do you have a copy of everything, and then each sub-entry has its own entry as well, and then each subheading under that has its own row in the database? Or are you only working with the most granular ones? John: I don't even know, actually. how the AI decided to organize it. Sacha: Okay, yeah. So basically, when you do a search, for example, can you find something where the keywords are in multiple subtrees of a larger entry? John: I could do a join and find that information, because every entry knows what its parent entry is, and it could find out what the keywords for those parents and for any siblings would be as well. Sacha: Interesting. 1:11:04 Habits are better than goals
John: All the data is there. I was going to mention, by the way, that I was talking about Atomic Habits and how much that has affected the way I break tasks down. I try to get them to be smaller, and I also try to rely more on habits than on goals to accomplish things. 1:11:24 Breaking down tasks with a large language model
 John: So another thing that I built up in Org-mode using gptel is— let me find an entry that's long enough for this to work. Okay, so here we have a relatively long entry. It's a note here, and it's about bridging non-switching ports on an OPNsense router. Let's say that this was something I actually had to do now.
John: So another thing that I built up in Org-mode using gptel is— let me find an entry that's long enough for this to work. Okay, so here we have a relatively long entry. It's a note here, and it's about bridging non-switching ports on an OPNsense router. Let's say that this was something I actually had to do now.  John: I have this C-x c prefix that I use for talking to AI. One of the things that it can do is called a "task breakdown." So I do C-x c, and there are two of them: capital B and capital T. Capital B is designed to take something that is already a task and identify what the component tasks would be, probably, that need to be done and in what order to get this thing done.
John: I have this C-x c prefix that I use for talking to AI. One of the things that it can do is called a "task breakdown." So I do C-x c, and there are two of them: capital B and capital T. Capital B is designed to take something that is already a task and identify what the component tasks would be, probably, that need to be done and in what order to get this thing done. 1:12:13 Inferring tasks with a large language model
John: Capital T is "you've just got a sea of text— infer the tasks that are implied by that text." I wrote that one because sometimes when you use these voice transcriptions of meetings, all I have is the transcript, and I want to know, well, what were the action items? So I wrote "infer tasks" to get the action items. Let's infer the tasks out of this OPNsense router. So I will run that. I'm using now the Claude Sonnet model— I think I'm using the Claude Sonnet model. We're about to find out. Let me actually see which model that uses. 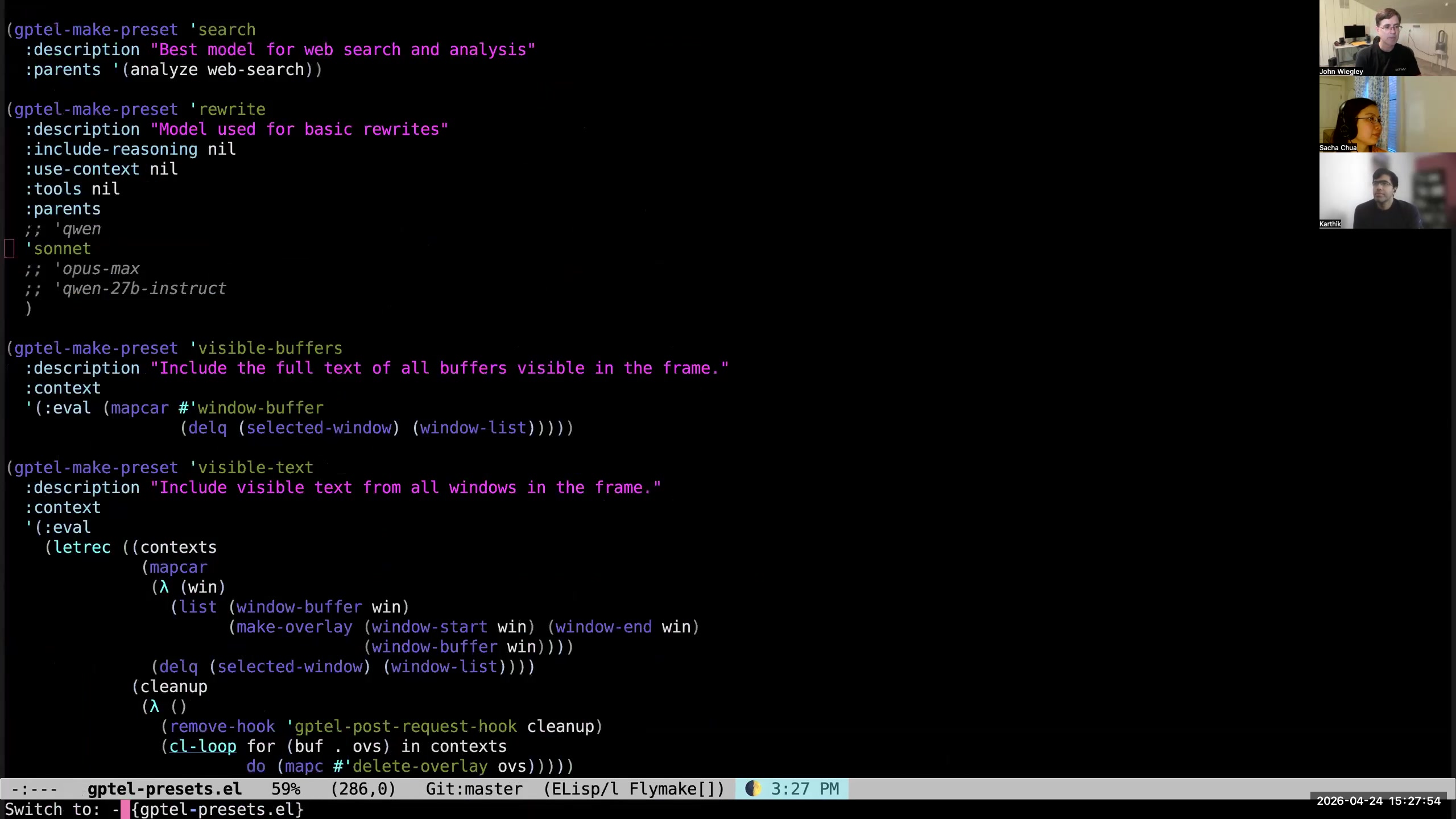 John: So that uses the "infer tasks" preset. The infer tasks—oh yeah, it uses the Sonnet model. I do not know—oh, maybe I have to block out the text. I mean, select the region. There we go. So what that did—you know, for some reason Claude was changed recently and it does not work for these types of tasks anymore.
John: So that uses the "infer tasks" preset. The infer tasks—oh yeah, it uses the Sonnet model. I do not know—oh, maybe I have to block out the text. I mean, select the region. There we go. So what that did—you know, for some reason Claude was changed recently and it does not work for these types of tasks anymore.  John: "No actionable tasks identified in this text." Let's go somewhere else. Let's go to a work meeting. This is my directory that has all the meetings in it. Let's find one that has a transcript.
John: "No actionable tasks identified in this text." Let's go somewhere else. Let's go to a work meeting. This is my directory that has all the meetings in it. Let's find one that has a transcript.  John: This one has a transcript. So we're just going to select the whole transcript, and the transcript got sent to Claude. We'll see what it comes up with. Sacha: All right. So AI help for identifying the tasks and also asking you questions, I guess, to break down tasks. John: It doesn't ask me questions.
John: This one has a transcript. So we're just going to select the whole transcript, and the transcript got sent to Claude. We'll see what it comes up with. Sacha: All right. So AI help for identifying the tasks and also asking you questions, I guess, to break down tasks. John: It doesn't ask me questions.  John: So these are the seven tasks that it inferred from the body of the transcript. It even identified that two of them were tasks to be done by the person that I met with, and the other five are the ones to be done by me. They have descriptive text, possibly, showing the context that it used to determine that that text should be there.
John: So these are the seven tasks that it inferred from the body of the transcript. It even identified that two of them were tasks to be done by the person that I met with, and the other five are the ones to be done by me. They have descriptive text, possibly, showing the context that it used to determine that that text should be there.  John: It even has the time codes as a property, so I can go back to where in the transcript it got that task from. That ends up being extremely valuable, especially when I'm dealing with— like I said—a sea of information, and I want to pick from that sea which fish I intend to catch. I've been using AI with gptel and Org-mode more and more connectedly to try and help me manage—not just manage that sea of information, not just search it and categorize it, but also refine it, break things down into more manageable pieces, help me find which things I should work on today. All of that is coming together rather nicely to help combat the drift problem that Karthik was talking about. Sacha: And it's so easy to work with because it's all text, and you can just give it that along with your prompts. Do you share your prompts anywhere?
John: It even has the time codes as a property, so I can go back to where in the transcript it got that task from. That ends up being extremely valuable, especially when I'm dealing with— like I said—a sea of information, and I want to pick from that sea which fish I intend to catch. I've been using AI with gptel and Org-mode more and more connectedly to try and help me manage—not just manage that sea of information, not just search it and categorize it, but also refine it, break things down into more manageable pieces, help me find which things I should work on today. All of that is coming together rather nicely to help combat the drift problem that Karthik was talking about. Sacha: And it's so easy to work with because it's all text, and you can just give it that along with your prompts. Do you share your prompts anywhere? 1:15:35 johnw/prompt-deploy has the prompts
John: My prompts are all on GitHub. There's a project that I wrote called Prompt Deploy, and you'll find all of my prompts in there. Prompt Deploy is both a set of prompts, agents, skills, MCP tools, and models, and then a Python script that will deploy it to all of your agentic frameworks. It knows about Factories, Droid, OpenCode, Claude Code, Codex, Gemini—and it knows how to rewrite that information so that the prompt is usable in every one of these for every machine that you use all of these things on. When I do a Prompt Deploy, it writes out 896 different files to all of these different tools in all of their different locations. Because I only want to define the prompt once. Sacha: I'm looking forward to having a good poke around. Now, interestingly, in our last conversation, I think one of the ideas was to then take the transcript of that conversation and see if a meeting summarizer could do something with it. I don't think we actually went through with that last time in 2024, but maybe this year it'll do a better job of pulling out the key topics. I will still probably edit the transcript manually, because transcripts are fun. Yeah. But okay— 1:17:02 Summarizing our conversation so far
Sacha: Today, the conversation was mainly about your kind of Org task lifecycle, including using AI to help you refine the tasks further. Karthik, do you have anything that you want to dig into a little bit more? Karthik: I don't think we'll have time to discuss philosophy today—the philosophy of task management. But I do want to say, I think we covered how things go into the system and then how things surface, right? Things go into the system using manual captures, using voice or whatever, or they're created by LLMs. Then things come out of the system or are surfaced using the various agenda views, right? I hope that that's a somewhat complete picture of just the ins and outs—tasks go in and then they show up in various ways. There's a lot to take in. I knew some of this, but this is still too much. I've been using Org for nearly 20 years and I can't even wrap my head around it. It's easy to think of these as cool things that might be possible, but to actually see them being used— and usefully—there's a huge gap between the two. The fact that John actually uses this productively is pretty crazy to me. Sacha: I think we can break it down into a couple of practices that people might be interested in experimenting with. Like, for example, that idea of using those kinds of focus or home dashboards—an Org file where everything is organized by your hierarchy of importance, and includes the dynamic blocks to list the actual tasks for that section, or the links that you can open with C-c C-o. 1:19:13 Karthik's completing-read version of C-c C-o
Sacha: Karthik, did you know that C-c C-o could open all the links, Because I did not. Karthik: Yeah. Sacha: So let's go. Karthik: I knew that, and I also wrote— I didn't like the way Org does it, so I wrote a completing-read version of that. Sacha: Oh, very cool. Karthik: That's what I use, and I use it from the agenda. So if I do C-c C-o in the agenda, it shows me a completing-read interface with all the links in that entry. The reason I did this is because now I can do other things with the links. I can use Embark. I can export the links, just the links. You're not limited to just opening them. 1:19:56 Karthik's thoughts on the demo so far
Karthik: But anyway, it's just difficult for me to wrap my head around the fact that all of this comes together in a way where it shows you what you need to see when you need to see it. Yeah, it's like magic to me. I don't know how else to describe it. As proofs of concept, all of this makes sense— every individual feature. But the idea that it actually works—and then when you see it, you're not like, "Oh, I see what you're showing me, but that's not what I want to think about right now." The fact that that doesn't happen, or if it does happen, it's in a minimal way—it's pretty impressive. Sacha: It's something that people will have to ease into as they try out different parts of this workflow. Things like using the org-capture, even just with the menu that you have, where it breaks it down into lots of levels—names starting from A to D, that sort of thing. Yeah, it's a lot of cool stuff, which we will try to write about and index, and maybe use screenshots for, because otherwise I think Karthik goes slightly crazy with the blurring. Karthik: No, for the most part... The only challenging moments are when you were scrolling line by line, because that gets... But most of the time it was static, so it's easy to draw rectangles. 1:21:29 Categories are subject areas
Karthik: There's one other thing I wanted to ask you, which is how you break down... So Org has a few affordances. It has TODO keywords, categories, properties, and tags, right? I just wanted to know what meanings—you're free to assign whatever meanings you want to all of these, right? There are different ways to break this down. I just wanted to know, for the record, how do you think about each of these things? John: For me, categories are subject areas. So if I want to see everything that I currently have in my TODOs related to AI— because those are usually fun tasks— then anything that is in the AI category, or under the AI category (one of the subcategories), I can just do a category report for AI and I will see all of those tasks. Sometimes when I have an evening and I just want to play, that's the report I'll do. Karthik: But sorry, categories are mutually exclusive though, right? When you assign a category, it owns that task. John: AI is a child of the Computer category, which is a child of the Personal category. So they're hierarchical. Karthik: Oh, categories can have children? John: Yes. Sacha: Because you can specify it as a property. John: So an entry has multiple categories— it's every parent that it has up the hierarchy. 1:22:58 TODO keywords use a fixed vocabulary
 Karthik: Okay. The next is TODO keywords. I saw even HABIT was a TODO keyword for you, so I was wondering... John: Oh yeah, I have a very fixed vocabulary of TODO keywords. If I share my screen again, the way that I manage my TODO keywords is that I have a dot-file. This dot-file defines my keyword hierarchy and how they're all related. The Org Haskell utility that I wrote that does the data normalization—this is how I tell it what my keywords are. I don't yet have Elisp code that also populates Emacs's Org-mode definitions based on this file, but I do it by hand— I guess because that data was older and it was already mostly there. Karthik: And these are global across your whole corpus? John: Yes, they're global. I don't ever use keywords outside of this set. Karthik: Per-file keywords? John: No, I don't use per-file keywords. Sacha: Because you have your validation smacking it if it gets mistyped, for example. John: Right. Karthik: So to be clear, your TODO keywords represent the state of a task, right? Like, what state is it in? Hence the state machine right here, right? John: Exactly. Karthik: Okay. And the states include things like SCRAP or LINK. Why is LINK a state? John: LINK is because it's a different kind of a note. A LINK is a note that only has a URL. Sacha: So it doesn't require—yeah, your action is just look at the thing or do something with it. John: Yeah, it has no body.
Karthik: Okay. The next is TODO keywords. I saw even HABIT was a TODO keyword for you, so I was wondering... John: Oh yeah, I have a very fixed vocabulary of TODO keywords. If I share my screen again, the way that I manage my TODO keywords is that I have a dot-file. This dot-file defines my keyword hierarchy and how they're all related. The Org Haskell utility that I wrote that does the data normalization—this is how I tell it what my keywords are. I don't yet have Elisp code that also populates Emacs's Org-mode definitions based on this file, but I do it by hand— I guess because that data was older and it was already mostly there. Karthik: And these are global across your whole corpus? John: Yes, they're global. I don't ever use keywords outside of this set. Karthik: Per-file keywords? John: No, I don't use per-file keywords. Sacha: Because you have your validation smacking it if it gets mistyped, for example. John: Right. Karthik: So to be clear, your TODO keywords represent the state of a task, right? Like, what state is it in? Hence the state machine right here, right? John: Exactly. Karthik: Okay. And the states include things like SCRAP or LINK. Why is LINK a state? John: LINK is because it's a different kind of a note. A LINK is a note that only has a URL. Sacha: So it doesn't require—yeah, your action is just look at the thing or do something with it. John: Yeah, it has no body. 1:24:48 Tags are context: person, place, or thing needed for the task
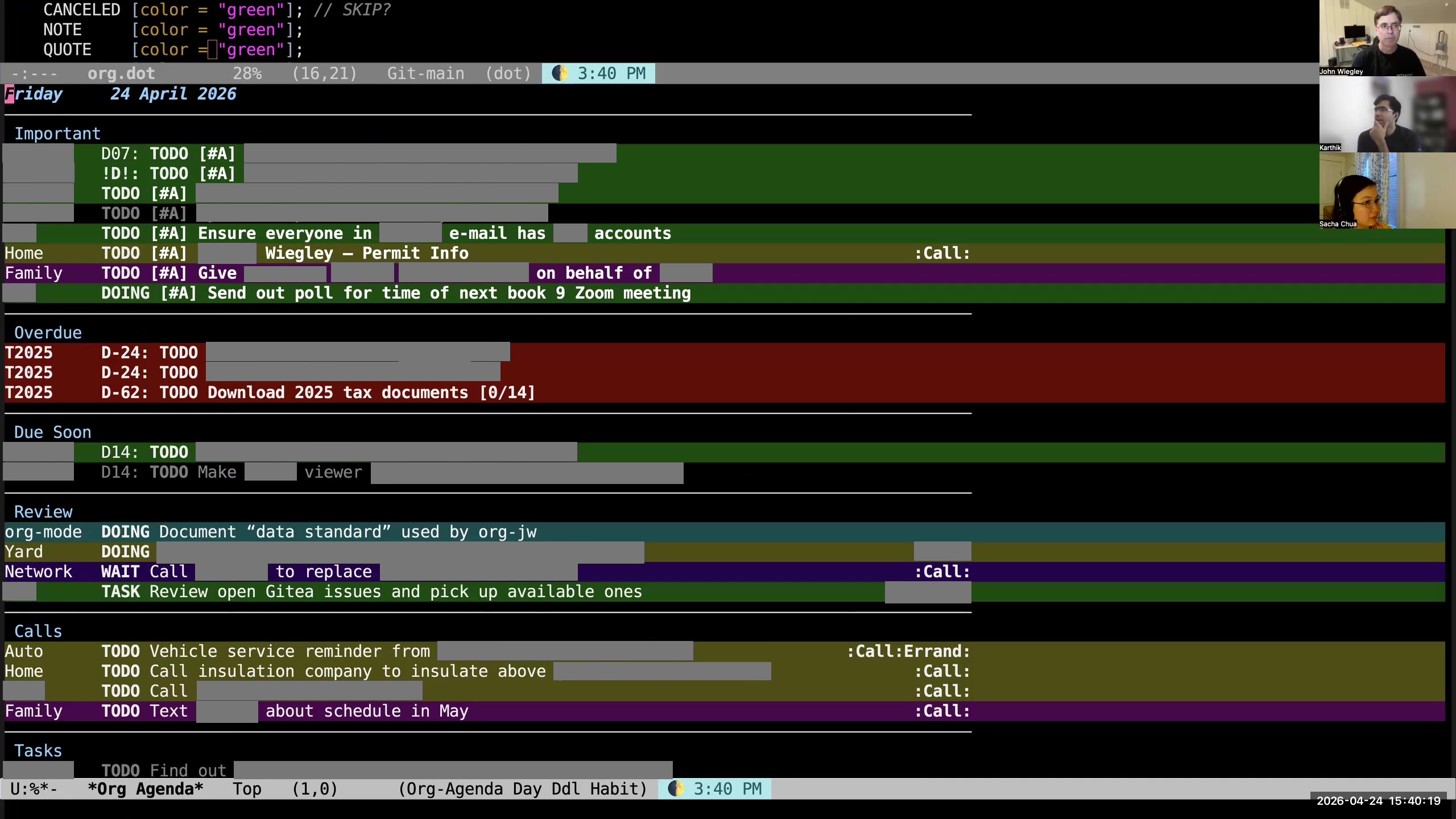 Karthik: The next question is tags. How do you think of tags in Org? John: Tags for me are context. They indicate the person, place, or thing that has to be present in order for me to be able to make progress on that task. Karthik: And how is that different from— oh, okay, I can see how it's different from the category, I guess. So what are some examples of tags you use? I understand people's names are tags, but what else do you have there? John: I have "call" as a tag, so it has to be during the times of the day when I could make a phone call. I have "errand" as a tag—it has to be during a time of the day that things would be open and I could drive out of the house. I have tags for individual people, so that I have to be able to be in contact with them. Org-mode has a nice feature: if I hit \ RET, it will examine my environment based on the
Karthik: The next question is tags. How do you think of tags in Org? John: Tags for me are context. They indicate the person, place, or thing that has to be present in order for me to be able to make progress on that task. Karthik: And how is that different from— oh, okay, I can see how it's different from the category, I guess. So what are some examples of tags you use? I understand people's names are tags, but what else do you have there? John: I have "call" as a tag, so it has to be during the times of the day when I could make a phone call. I have "errand" as a tag—it has to be during a time of the day that things would be open and I could drive out of the house. I have tags for individual people, so that I have to be able to be in contact with them. Org-mode has a nice feature: if I hit \ RET, it will examine my environment based on the name-mask-list-at Emacs Lisp function that I wrote, and it will auto-filter out the tags that don't currently apply. So if I have a tag based on "call" and it's outside of the time of when it could happen—like at 7 AM— then it will filter all the call items out of my daily agenda. They're still in the daily agenda; they just won't appear until later when it is time to make calls. Karthik: Ooh. Okay. 1:26:14 Priority: A means must do, C means optional
Karthik: So the next affordance is priority. I guess you use priority the normal way— just A, B, C—for importance. John: Well, I only use A and C. I don't use B. Karthik: Okay, so you only need two, I guess. So what does it mean if it doesn't have a priority? Is that the lowest? John: No. If it doesn't have a priority, that's just... So to me it's "must," "should," and "optional"—those are the meanings of the three priorities. "Must" means there is a consequence if you don't do it. "Should" means maybe you're missing out on an opportunity if you don't do it. But really, it's up to you. "Optional" means there's really no good or bad here; it's just an item you may want to do. Karthik: So if it doesn't have an explicit priority, is it optional? John: If it has no explicit priority, it's a "should." Karthik: Okay. John: I assume that if I made a TODO entry, it's something I should do. That's the assumption. 1:27:31 Properties are mostly automatically assigned metadata
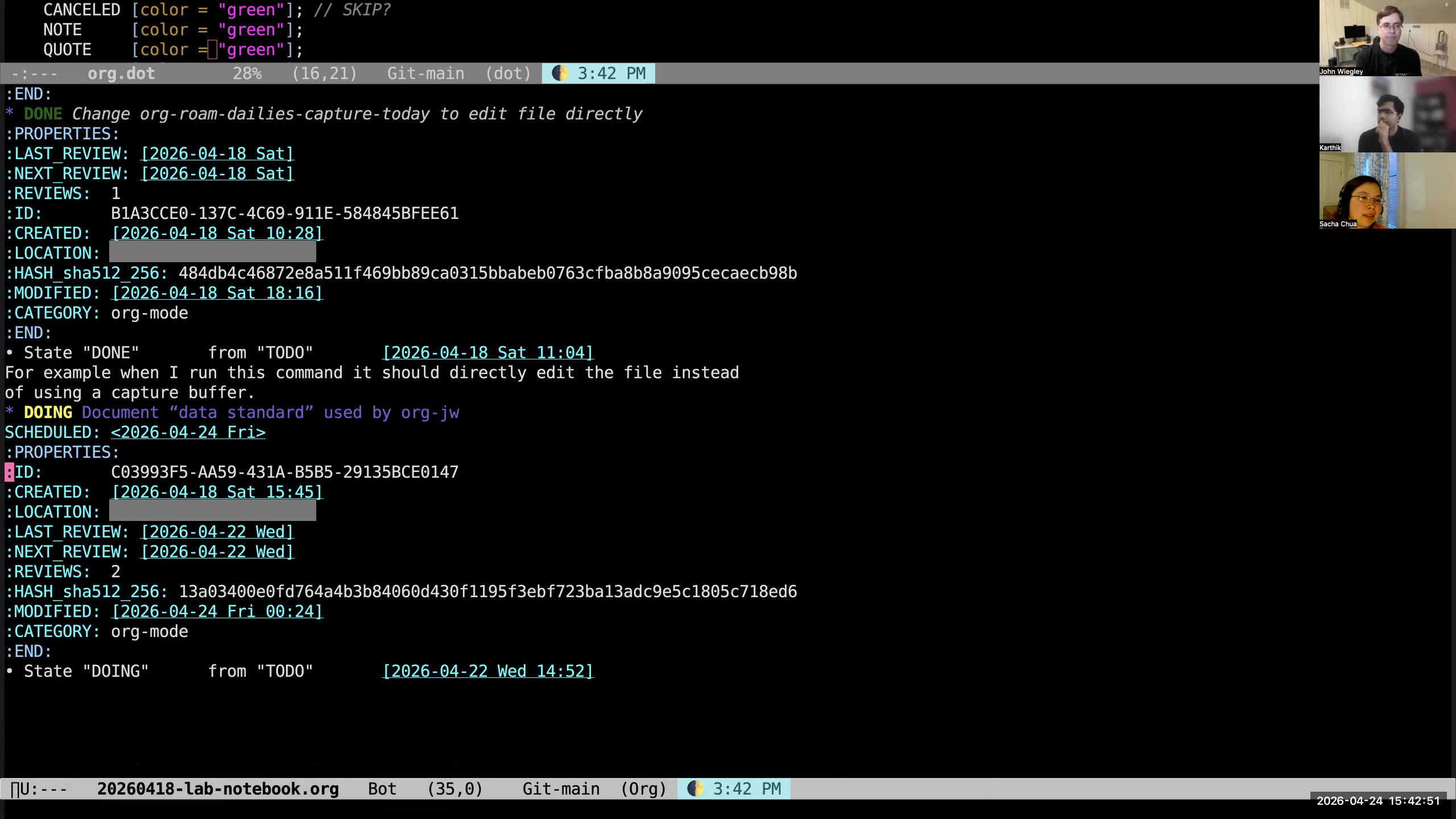 Sacha: Do you use properties for anything? Aside from the review property, of course, do you have any other custom properties you like? John: Just the ones I showed after we did the capture, like the ID, the location, when it was created, when it was modified. Sacha: Yeah, so those seem to be more automatically assigned. John: I very rarely use manually assigned properties. Sacha: Okay. John: To me, properties are metadata, so I'd rather just never look at them and have the system automatically manage them. Sacha: I don't think we actually touched on what you do with a hash. Did we talk about that one yet?
Sacha: Do you use properties for anything? Aside from the review property, of course, do you have any other custom properties you like? John: Just the ones I showed after we did the capture, like the ID, the location, when it was created, when it was modified. Sacha: Yeah, so those seem to be more automatically assigned. John: I very rarely use manually assigned properties. Sacha: Okay. John: To me, properties are metadata, so I'd rather just never look at them and have the system automatically manage them. Sacha: I don't think we actually touched on what you do with a hash. Did we talk about that one yet? 1:28:09 The hash
 John: The hash is how the database knows that an entry needs to be fully updated. If the hash has changed—the database has the hashes in it as well, and it has the last modification dates as well— first I do a search for all items whose modification date is different from the modification date in the Org-mode file, and then I check the hash values, because maybe I changed an item but I changed it back, and now the database doesn't need to be updated for that. Sacha: Very cool. All right, so that's all the different Org features and how they support your workflow. John: Yeah.
John: The hash is how the database knows that an entry needs to be fully updated. If the hash has changed—the database has the hashes in it as well, and it has the last modification dates as well— first I do a search for all items whose modification date is different from the modification date in the Org-mode file, and then I check the hash values, because maybe I changed an item but I changed it back, and now the database doesn't need to be updated for that. Sacha: Very cool. All right, so that's all the different Org features and how they support your workflow. John: Yeah. 1:28:51 Assigning the tags when refiling
Karthik: Yeah, the one that's most interesting to me is tags, because I understand in the abstract what you mean by "a tag is a context or a resource that you need." But somehow I can never seem to implement it. It's not that I end up with a pile of tags that don't mean anything; it's that entries just don't get the tags that they need, so they don't show up later. Is there some way you ensure—when you capture, I know that you don't assign tags, you just want to get stuff in— at what point does it get assigned the right tags, and how? John: Usually when I'm refiling it from the inbox into the appropriate category, into the appropriate heading. Karthik: So do you do that by hand? John: Yes, I always do that by hand. That's my main way of interacting with the task. I go to the inbox and then I give it the tags or the properties I want it to have. Sacha: Are you using the standard Org completion for tags, or typing it in manually, or doing something to help you select from the gazillions of tags you probably have? John: Yeah, I use—let's see, where is it in my Org-mode file here? I use the Org-mode feature... where are tags? Let me see where tags get defined, because I know I have the shortcut defined somewhere here in my Org-mode file. It says that "call" is the letter C. Sacha: Oh, yeah. John: I forget how Org defines that. Sacha: That looks like that org-tag-persistent-alist there. Karthik: That's C, yeah. John: Yeah, but that's only a couple of tags. 1:30:47 Per-file tags and tag validation
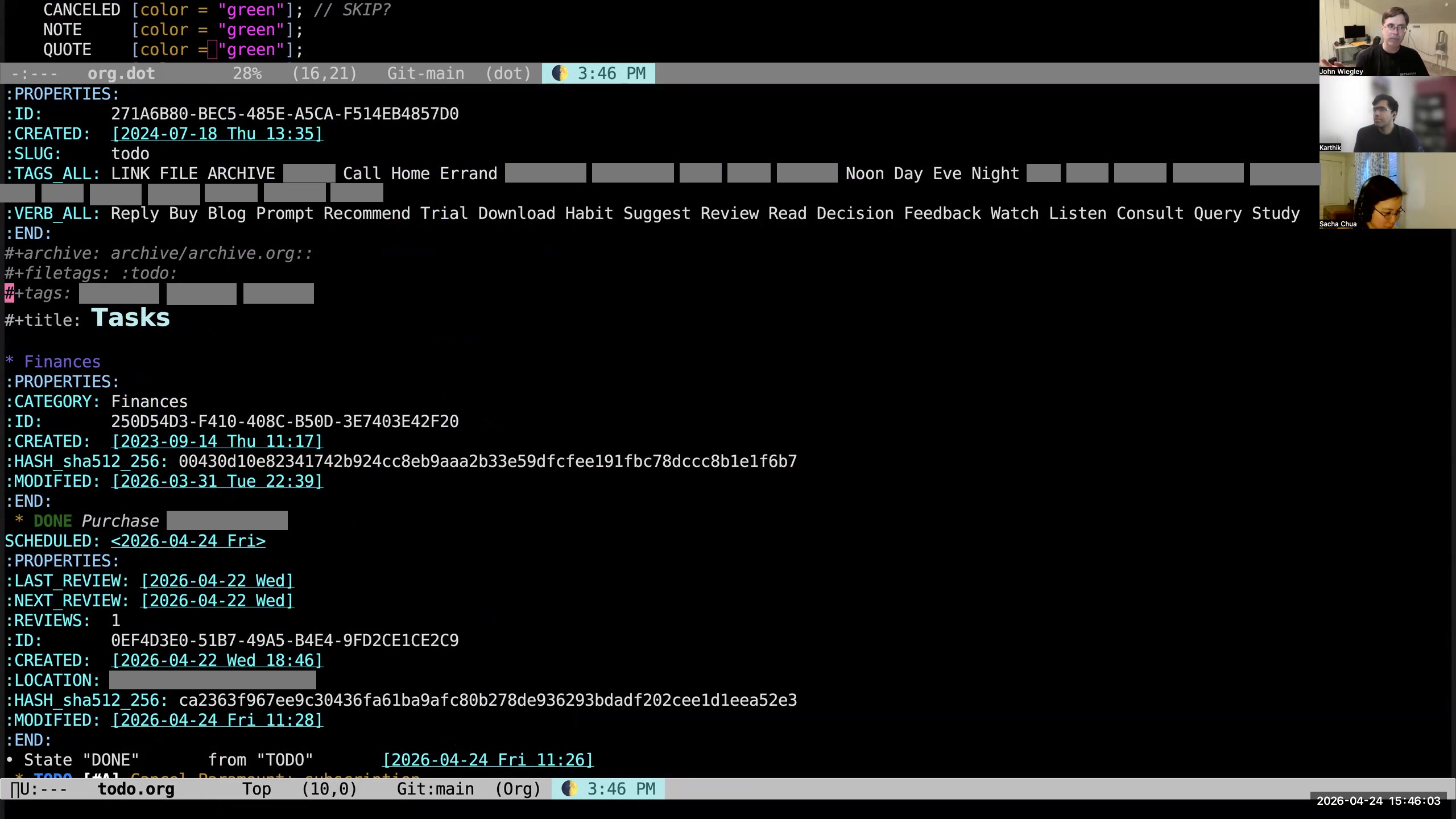 John: Tags are one thing where I do tend to use in-file. If I want to have shortcuts for tags, I tend to use—so I have some tags that are truly global, and then I have per-file tags because I want the tags to be related to the categories that I'm tagging. My org-jw Haskell utility recognizes a file property called
John: Tags are one thing where I do tend to use in-file. If I want to have shortcuts for tags, I tend to use—so I have some tags that are truly global, and then I have per-file tags because I want the tags to be related to the categories that I'm tagging. My org-jw Haskell utility recognizes a file property called tags-all. If that file property is set, it will mandate that the tag has to be within that vocabulary. 1:31:29 Starting tasks with a restricted set of verbs and validating them
 John: The same with
John: The same with verb-all. Verbs are words that can be at the beginning of an entry title that are followed by a colon.  John: So I might have, instead of "send an email to Sacha," I might say "Reply: Sacha's email." Instead of saying "reply to," I just make it a command verb. That verb has to be within that constrained vocabulary. Sacha: That's interesting. Do you use those verbs for further filtering? John: Yeah, because then you can search. They stand out a little bit better because they represent actions that need to be taken, and it's very clear what the action is. You could also query for all of the items that have a certain verb type. Like if I'm sitting down to write a bunch of emails, I don't have a tag for writing email and I don't have a category for writing email, but if I were to search for all items that have a "Reply" verb, I would find all of the emails that I need to write today. Karthik: Is that just a text search, or do you search for...? John: It's just a text search. Yeah, because colons don't get used in any other way. That's also a constraint of the system: where other people would use colons, I just use em dashes. Karthik: Okay. And if I understand your system right, you wouldn't tag this entry with "Sacha," right? Because you don't need Sacha for this task. John: That's correct. Unless Sacha would be the one writing the email, I don't need Sacha to write the email. Sacha: Okay. Very interesting.
John: So I might have, instead of "send an email to Sacha," I might say "Reply: Sacha's email." Instead of saying "reply to," I just make it a command verb. That verb has to be within that constrained vocabulary. Sacha: That's interesting. Do you use those verbs for further filtering? John: Yeah, because then you can search. They stand out a little bit better because they represent actions that need to be taken, and it's very clear what the action is. You could also query for all of the items that have a certain verb type. Like if I'm sitting down to write a bunch of emails, I don't have a tag for writing email and I don't have a category for writing email, but if I were to search for all items that have a "Reply" verb, I would find all of the emails that I need to write today. Karthik: Is that just a text search, or do you search for...? John: It's just a text search. Yeah, because colons don't get used in any other way. That's also a constraint of the system: where other people would use colons, I just use em dashes. Karthik: Okay. And if I understand your system right, you wouldn't tag this entry with "Sacha," right? Because you don't need Sacha for this task. John: That's correct. Unless Sacha would be the one writing the email, I don't need Sacha to write the email. Sacha: Okay. Very interesting. 1:33:08 Searching items: ripgrep, vector embedding, openclaw
Karthik: So if you want to get a list of all your interactions with Sacha that have been captured in your Org database, would you just use full-text search with a name, or a semantic search with a name? John: That's a really good question. Sacha: You just removed two of the tasks, so we can put some back so that there's something to search. 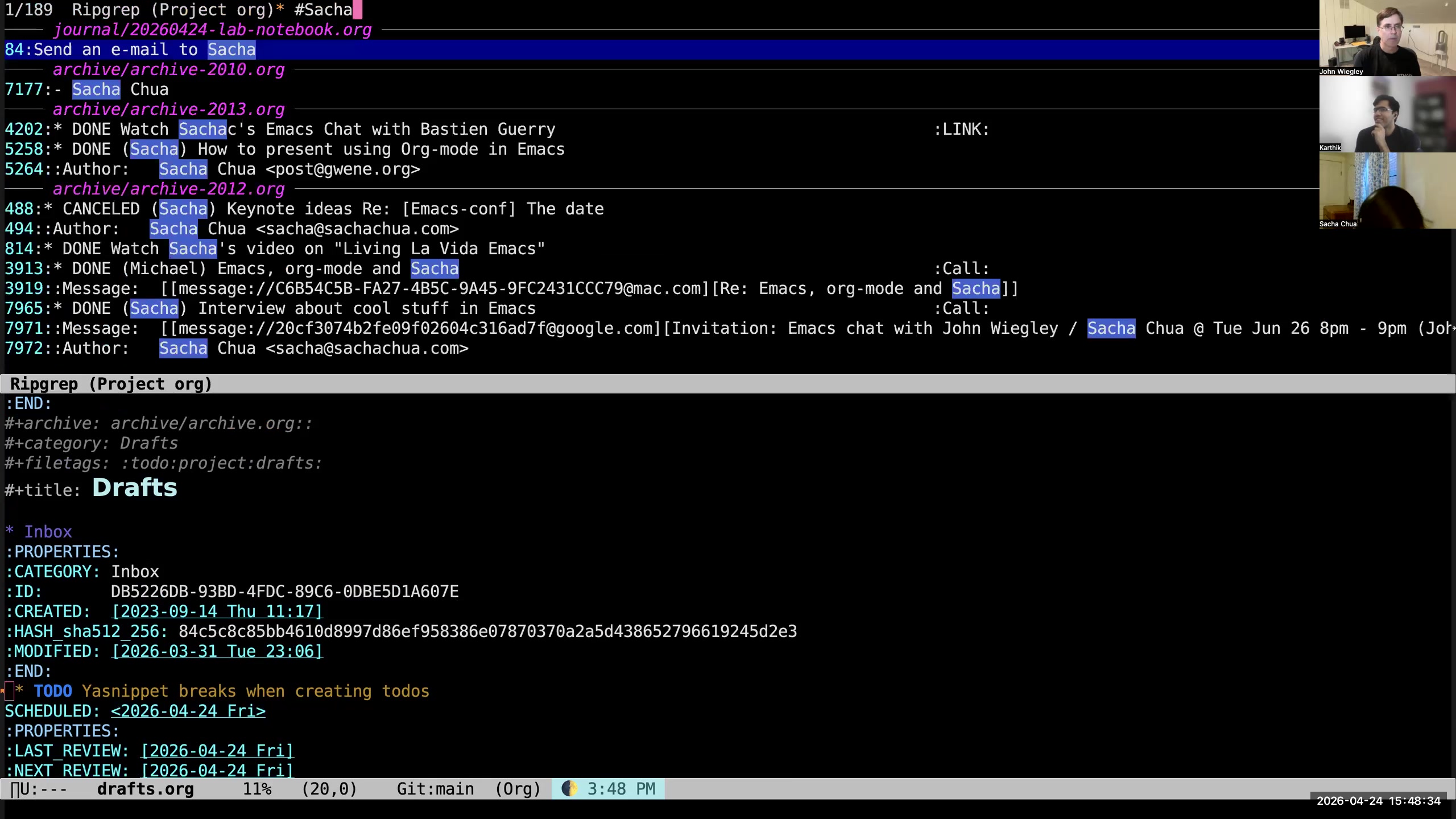 John: Well, I would first use ripgrep, because that's the fastest.
John: Well, I would first use ripgrep, because that's the fastest.  John: But it all really depends on what it is that I'm looking for, because I have lots of—Sacha occurs a lot of times in my database. I don't have any way of saying, "What are all of my tasks related to Sacha?" unless she were a category. If she were a category, I could do it. But I don't have categories for every single person that I know. Karthik: Okay. Sacha: Okay, cool. Karthik: So even with this extensive system, there are views that are not readily available? John: I mean, I would probably at this point ask OpenClaw, "What are all my tasks related to Sacha?" Karthik: Yeah. That's the semantic search doing its job. John: Semantic plus full-text. Karthik: Yeah. John: Actually, let's see what it says. You know what? Actually, I shouldn't just have semantic search doing vector embedding here. I should actually have this able to engage a local LLM from Emacs, instead of just from OpenClaw. Sacha: We see a TODO appearing real-time as John thinks, "Okay, I've got to add this to the system." John: Yeah, I'll wait until the need increases. Sacha: Yeah, yeah. But yeah, once you have the data, especially if you've got it indexed in something like Postgres that can do things a little bit faster, then yeah.
John: But it all really depends on what it is that I'm looking for, because I have lots of—Sacha occurs a lot of times in my database. I don't have any way of saying, "What are all of my tasks related to Sacha?" unless she were a category. If she were a category, I could do it. But I don't have categories for every single person that I know. Karthik: Okay. Sacha: Okay, cool. Karthik: So even with this extensive system, there are views that are not readily available? John: I mean, I would probably at this point ask OpenClaw, "What are all my tasks related to Sacha?" Karthik: Yeah. That's the semantic search doing its job. John: Semantic plus full-text. Karthik: Yeah. John: Actually, let's see what it says. You know what? Actually, I shouldn't just have semantic search doing vector embedding here. I should actually have this able to engage a local LLM from Emacs, instead of just from OpenClaw. Sacha: We see a TODO appearing real-time as John thinks, "Okay, I've got to add this to the system." John: Yeah, I'll wait until the need increases. Sacha: Yeah, yeah. But yeah, once you have the data, especially if you've got it indexed in something like Postgres that can do things a little bit faster, then yeah. 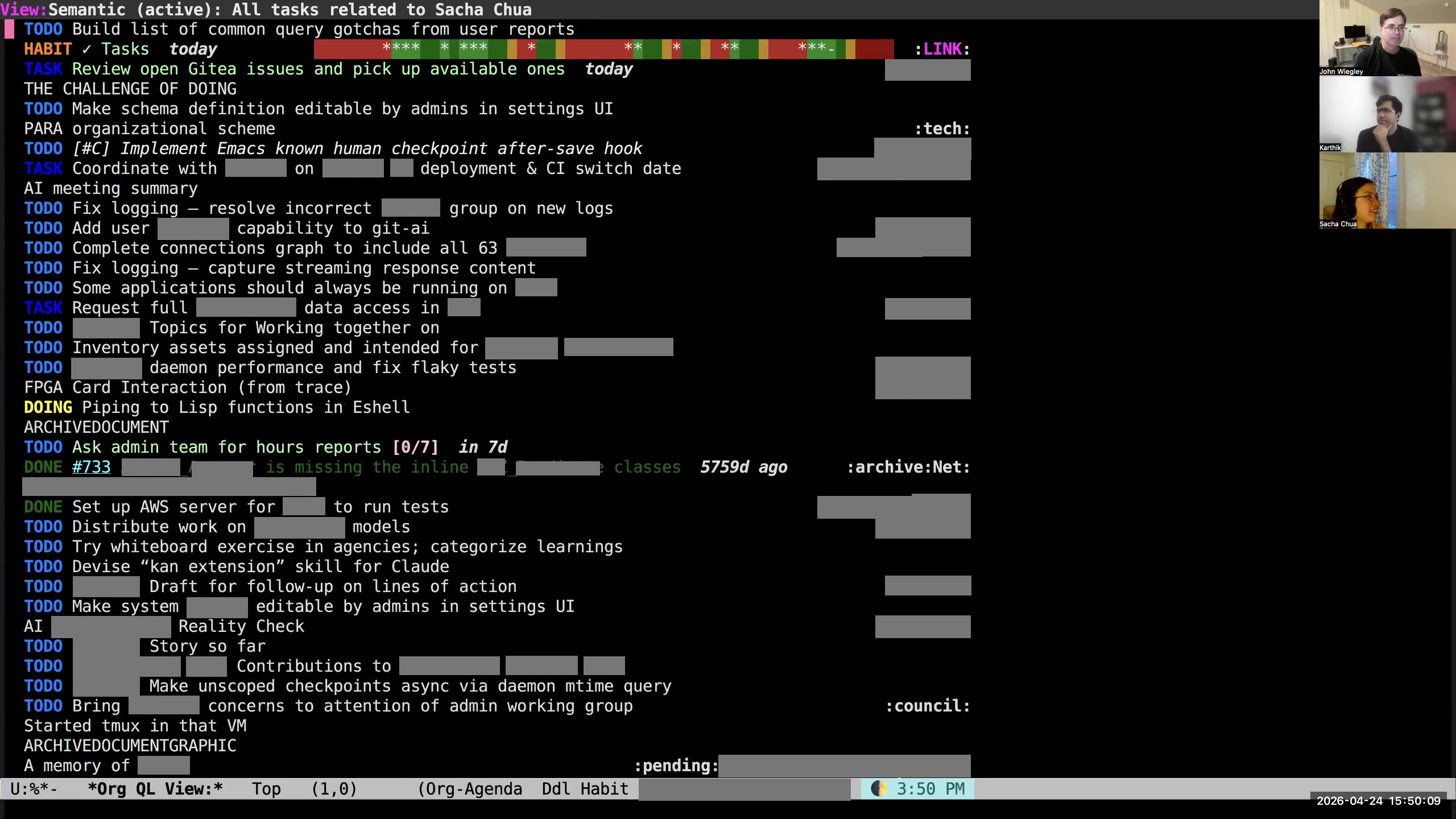 John: So this was its list of all tasks related to Sacha Chua. It didn't do a very good job. Sacha: Because semantic—you know, vector search and names doesn't make sense. But if you're doing something more concept-related, that might work. John: Yeah. Sacha: Full text would be great. I think org-ql is something that people often use for that sort of thing anyway.
John: So this was its list of all tasks related to Sacha Chua. It didn't do a very good job. Sacha: Because semantic—you know, vector search and names doesn't make sense. But if you're doing something more concept-related, that might work. John: Yeah. Sacha: Full text would be great. I think org-ql is something that people often use for that sort of thing anyway. 1:35:36 Linting and normalizing data in a pre-commit hook using Lefthook
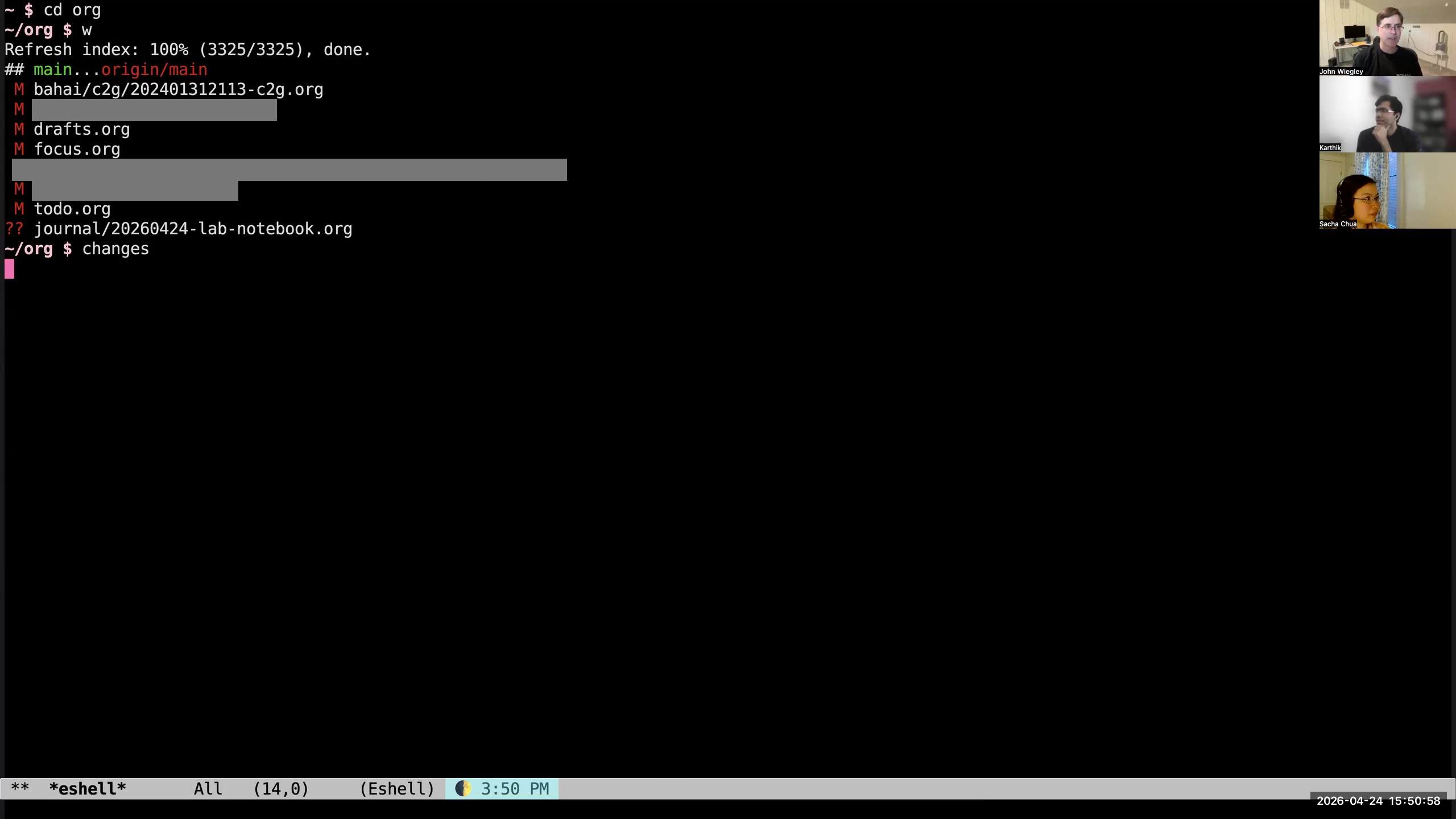 John: Then finally, I use Lefthook, which is a Git hooks manager, so that when I type "changes"— which is going to make a commit whose subject line is just "changes" (I don't try to give descriptive commits for my thing)— it will use Lefthook to run the pre-commit hook, which is going to use the linter and use the org-jw Haskell. So it's now doing full round-trip lint on just the files that changed, by the way, not on all of them.
John: Then finally, I use Lefthook, which is a Git hooks manager, so that when I type "changes"— which is going to make a commit whose subject line is just "changes" (I don't try to give descriptive commits for my thing)— it will use Lefthook to run the pre-commit hook, which is going to use the linter and use the org-jw Haskell. So it's now doing full round-trip lint on just the files that changed, by the way, not on all of them. 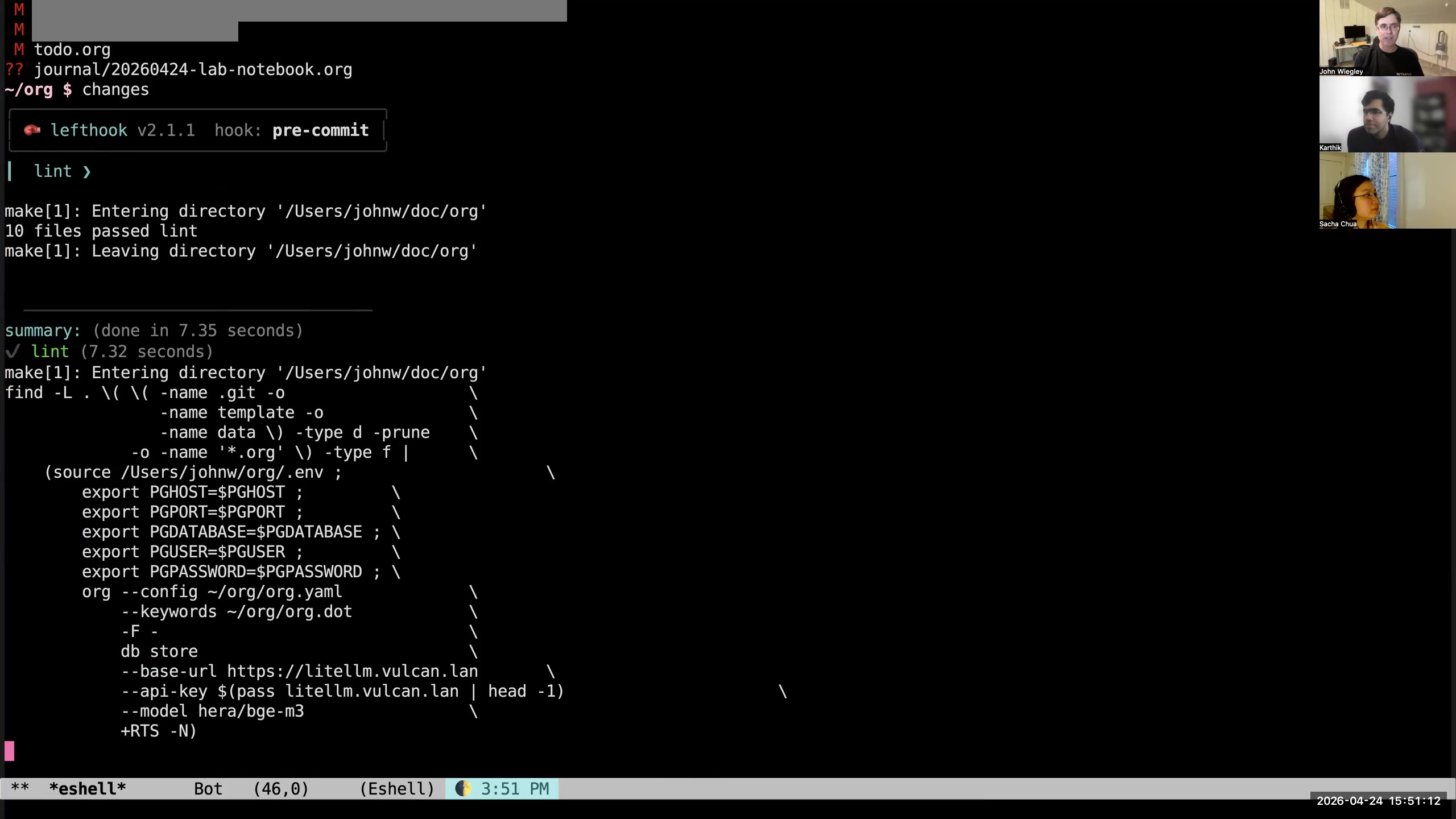 John: That succeeded, so it made the commit. Now that it's made the commit, it's going to store all of the changed entries in the database. Then it's going to do vector embeddings on all of the text regions that need up-to-date embeddings. Sacha: I think this whole normalization piece is something that I would love to see if we can get into a form that somebody other than you can run, because it's one of the things I've envied about your system for a while.
John: That succeeded, so it made the commit. Now that it's made the commit, it's going to store all of the changed entries in the database. Then it's going to do vector embeddings on all of the text regions that need up-to-date embeddings. Sacha: I think this whole normalization piece is something that I would love to see if we can get into a form that somebody other than you can run, because it's one of the things I've envied about your system for a while. 1:36:40 LLM-generated RFC-style specifications of the format
 John: I did finally write it all. I had AI help me create an RFC-format document for the entire Org-mode format. So this documents as a standard the Org-mode text format. Then this document is an RFC-format document which is the delta—everything that I do that is different or adds on to the Org-mode format is in this document. We could see, like, keywords. Not keywords, what do I call them... Verbs.
John: I did finally write it all. I had AI help me create an RFC-format document for the entire Org-mode format. So this documents as a standard the Org-mode text format. Then this document is an RFC-format document which is the delta—everything that I do that is different or adds on to the Org-mode format is in this document. We could see, like, keywords. Not keywords, what do I call them... Verbs. 1:37:17 The heading grammar
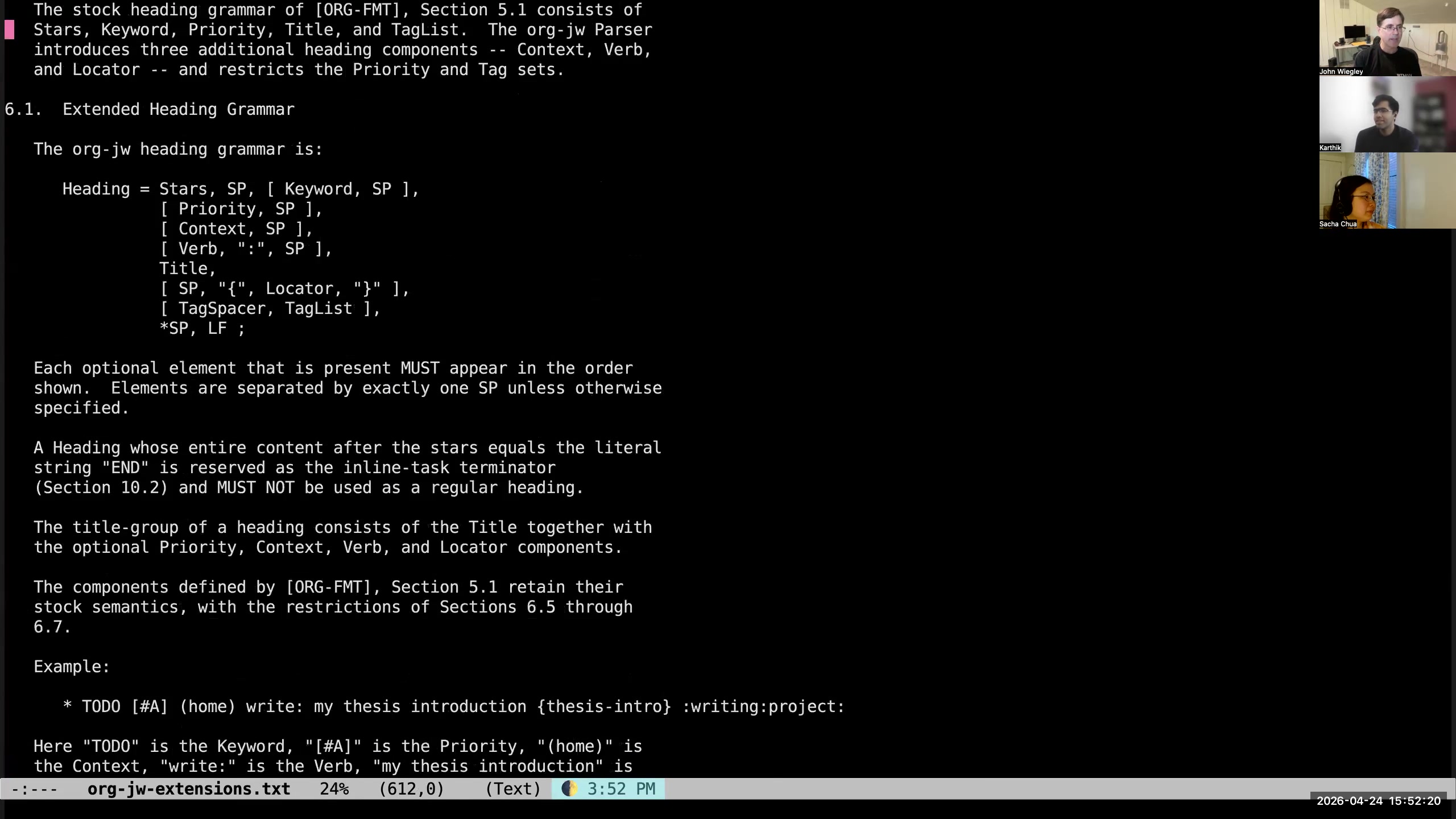 John: So like here, this is the extended heading grammar. This shows exactly what can be in the heading of an Org-mode entry in what order. There is no syntax for headings in the Org-mode standard, but there is one in the JW extensions. So my org-jw Haskell project really is just an implementation of this RFC document. Sacha: I see, because you've constrained your vocabulary so that, for example, your headings are verb-colon-whatever, and that can be verified by your Haskell program.
John: So like here, this is the extended heading grammar. This shows exactly what can be in the heading of an Org-mode entry in what order. There is no syntax for headings in the Org-mode standard, but there is one in the JW extensions. So my org-jw Haskell project really is just an implementation of this RFC document. Sacha: I see, because you've constrained your vocabulary so that, for example, your headings are verb-colon-whatever, and that can be verified by your Haskell program. 1:37:52 A TODO example with everything
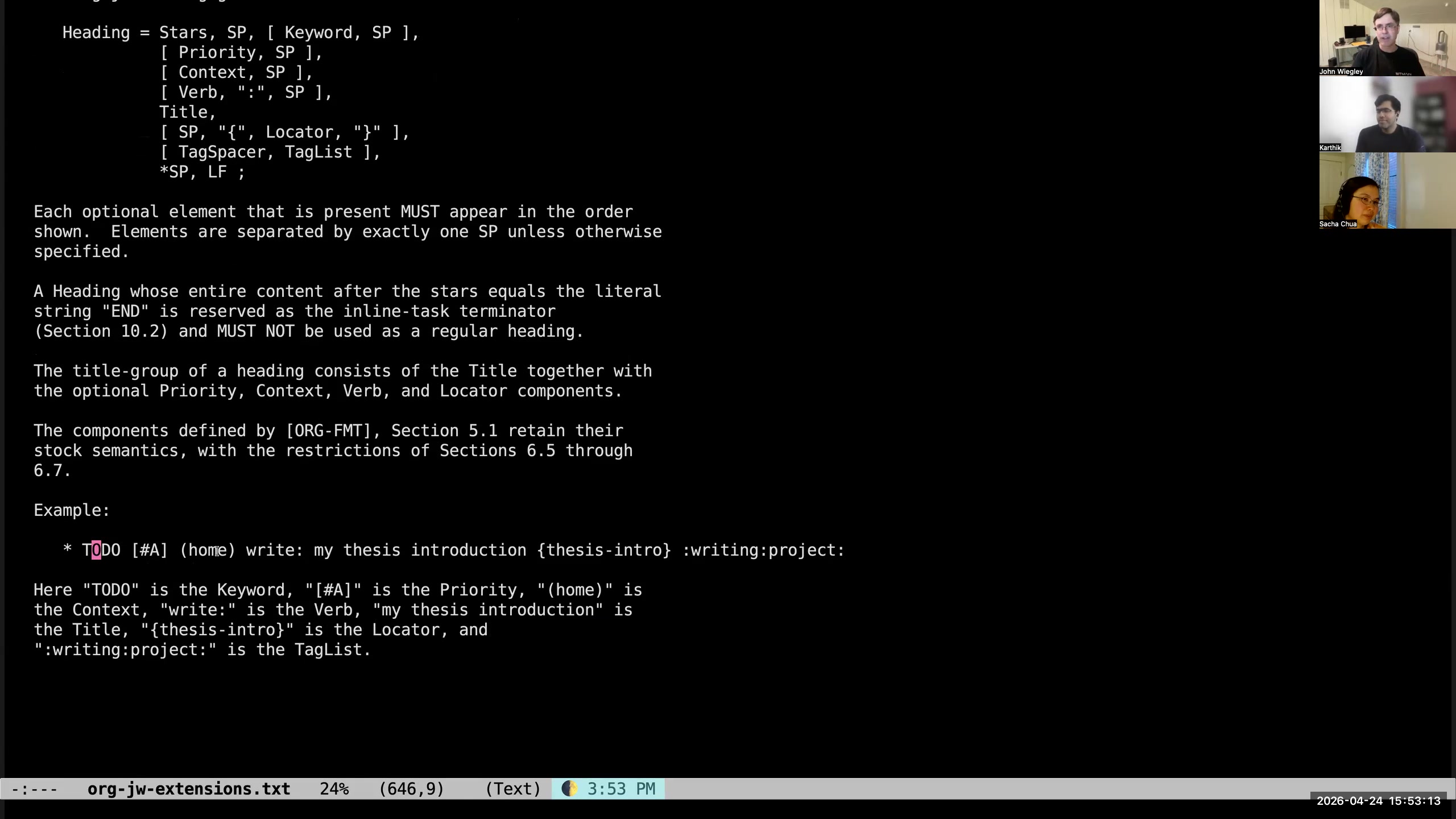 John: Exactly. You can see down here an example that uses every feature. It's got the keyword, the priority. It's got the context, which is a special type of context—usually relating to accounts or things like that. If it's related to a bank, or actually if Sacha were the one who asked me to write the email, I might make Sacha be the context of the task. Then there's the verb, then there's the title, then there's the locator.
John: Exactly. You can see down here an example that uses every feature. It's got the keyword, the priority. It's got the context, which is a special type of context—usually relating to accounts or things like that. If it's related to a bank, or actually if Sacha were the one who asked me to write the email, I might make Sacha be the context of the task. Then there's the verb, then there's the title, then there's the locator. 1:38:27 Locating objects in the physical world with {text}
John: The reason I use a locator is that in my closet I have a hanging files folder, and every file has a letter of the alphabet on it, A through Z. So if the task has—let's see here—if the task was "send email to Sacha" like this, this is an indicator to me that there is information related to this task that's in folder A of the hanging files folder. So sometimes if I have to send my property taxes into the county— well, they sent me a form to fill out and post with my check, so that form has to live somewhere while the task is open. Closed tasks, it's okay that their locator becomes invalid, because then I take the item out of the hanging folder and I shred it. But while the task is open, the locator locates related information, even if that information is physical. Sacha: I'm always very interested in the interaction between digital and physical systems. 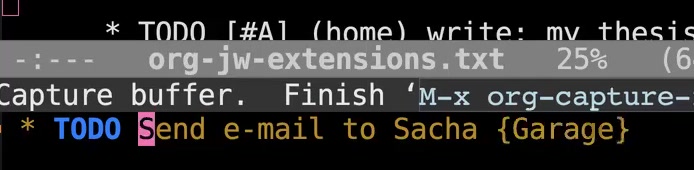 John: Yeah, I might say "garage" to locate something in my house, that there's an item in the garage. Karthik: The typical approach to this would be to use an Org property that says "location" or "physical location," but I guess because you require properties to be managed... John: Yeah, I don't see properties. To me, they can't hold actionable information. Sacha: So what I'm taking away from this is "stuff more useful metadata into titles." John: Or put a tag in the title that tells me that there is useful metadata, like the link tag. Sacha: Yeah, yeah. John: I could have a "phys" tag, which says that there's a locator to a physical something in the property. Or what's another one I use? It just occurred to me a second ago, but now I've forgotten it. Whatever. But yes, I could use that more too.
John: Yeah, I might say "garage" to locate something in my house, that there's an item in the garage. Karthik: The typical approach to this would be to use an Org property that says "location" or "physical location," but I guess because you require properties to be managed... John: Yeah, I don't see properties. To me, they can't hold actionable information. Sacha: So what I'm taking away from this is "stuff more useful metadata into titles." John: Or put a tag in the title that tells me that there is useful metadata, like the link tag. Sacha: Yeah, yeah. John: I could have a "phys" tag, which says that there's a locator to a physical something in the property. Or what's another one I use? It just occurred to me a second ago, but now I've forgotten it. Whatever. But yes, I could use that more too. 1:40:37 Managing attachments: DEVONthink for long-lived files, org-attach for temporary ones
John: Oh, attachments. I also use Org attachments. If somebody sends me a PDF, if that PDF is long-lived, I'll put it into a file-retrieval database called DEVONthink. Then I have a package for Org-mode, of course, called org-devonthink. If I just have the item selected in that database, I can hit a key which will associate a link that goes to that unique entry within the database. But if it's short-lived, meaning that I only need the PDF as long as I need the task to be open—kind of like with locators— then I will put it into an Org attachment, and that lives within a git-annex-controlled Git data directory within my Org-mode, sea of Org-mode data files. It gets a tag, which is capital FILE instead of capital
LINK, which tells me if I open the attachments directory for this task, I will see something related to the task. Sacha: Interesting. 1:41:45 Tags hint at where you can find more information
Sacha: So the tags also include hints about where you can go for more information. John: Yeah, and those tend to be all uppercase— those sort of metadata-awareness tags— whereas the "call," "errand," blah blah blah are all capitalized words, as are all of the ones for people. Karthik: About the link tag, sorry—you have LINK as the TODO keyword. You also have a link tag. Yes. Do they mean different things? John: The LINK keyword means this is equivalent to a note that has a link tag but no body. Karthik: Sorry, what am I looking at on your screen? John: Oh, you're not looking. I'm not showing you anything. 1:42:31 :LINK: tags indicate that there is a link; LINK state says this note is only a link
 John: So if I have a note that has a body and it has a URL, then it has to have a link tag. Karthik: Oh, okay. This is just putting it into practice.
John: So if I have a note that has a body and it has a URL, then it has to have a link tag. Karthik: Oh, okay. This is just putting it into practice.  John: If there is no body, then it's this. It's just a contraction. Sacha: It says, "Don't bother looking in here for a body." John: Yeah, right. There's no supporting information here. This is a bookmark link. But if it's a note, then it's a note with a link attached. It's a question of: is the link the principal piece of information, or is the link the ancillary information? Sacha: So the link tag says you can use C-c C-o on this and have something useful happen. The LINK type, or the LINK TODO state, says, "I'm just the link, I don't have any other notes."
John: If there is no body, then it's this. It's just a contraction. Sacha: It says, "Don't bother looking in here for a body." John: Yeah, right. There's no supporting information here. This is a bookmark link. But if it's a note, then it's a note with a link attached. It's a question of: is the link the principal piece of information, or is the link the ancillary information? Sacha: So the link tag says you can use C-c C-o on this and have something useful happen. The LINK type, or the LINK TODO state, says, "I'm just the link, I don't have any other notes." 1:43:30 Some other code turns Firefox bookmarks into an Org Mode file
John: Right. I have some other code— I believe it's written in Python— that will turn my Firefox bookmarks file into an Org-mode file with a bunch of link entries. It does this so it keeps that file in sync. That way I can use Firefox as a bookmark manager if I want. Sacha: Cool. 1:44:06 The format specifications are LLM-generated
Karthik: So I looked at the RFC and it's 3,600 lines. That's the delta. How long did that take you? John: It didn't take me any time at all. I just asked Claude to write it. Karthik: Okay. But then how do you know it got it right? John: I don't know that. Even if I wrote it, I wouldn't know that I'd gotten it right. Karthik: That's true. Yeah. But I was wondering, is that intended for humans? John: Probably not. It's intended for people who are writing such a process for themselves, and they would only be reading one specific section of interest. There's no human being that would ever read that document front to back. Or you could feed it to an AI and have it create the same thing for you in Python or Rust or whatever language you prefer. Sacha: It's a specification. John: Yeah, and AIs do very well with specifications. One thing that I could do that would be interesting is to use that specification to create a compliance test, and then any application which is able to pass the compliance test would be an implementation of the spec. Sacha: It also helps with your validation code, probably. Yeah, that makes sense. 1:45:30 Quick recap
Sacha: Cool, cool. Okay, so a whole bunch of things here that I am definitely looking forward to digging into further. I particularly like that idea of a draft—you know, kind of just capture the text and then have a menu of actions that you can do with the text, such as turning it into an email message or copying to your clipboard while saving a copy of it. That sounds very interesting. And then I can dig into all the other cool things that you do with breaking down tasks and identifying tasks out of transcripts. Many, many things to explore. Karthik, is your brain full too? Karthik: Yes, my brain overflowed with both information and ideas. I knew about the Drafts thing because John told me last year, but I didn't get it. The demo really helped with that in particular. Yeah, this was a whirlwind tour of... 1:46:28 A quick look at Github repositories: org2jsonl
 John: So in my GitHub, you will find—if you look for "org-this" and other utilities that I use for managing Org-mode— there's another one I wrote called org2jsonl, which will take any Org-mode file and turn it into a list of JSON objects. That's because there are certain utilities like Beads for managing tasks for AIs, and this allows you to use Org-mode as the data format for that. I have a Rust implementation of Beads that I cloned from somebody else that I modified to use org2jsonl, so it manages the tasks database there. We talked about org-hash, org-drafts.
John: So in my GitHub, you will find—if you look for "org-this" and other utilities that I use for managing Org-mode— there's another one I wrote called org2jsonl, which will take any Org-mode file and turn it into a list of JSON objects. That's because there are certain utilities like Beads for managing tasks for AIs, and this allows you to use Org-mode as the data format for that. I have a Rust implementation of Beads that I cloned from somebody else that I modified to use org2jsonl, so it manages the tasks database there. We talked about org-hash, org-drafts. 1:47:16 org-gptel: chat with AI within Org Mode instead of having to leave it
 John: I use ob-gptel so that in my lab notebook especially, I can dialogue with AI within Org-mode, not having to leave Org-mode and go to some other client. I have a now a running dialogue with the AI in my Org-mode file.
John: I use ob-gptel so that in my lab notebook especially, I can dialogue with AI within Org-mode, not having to leave Org-mode and go to some other client. I have a now a running dialogue with the AI in my Org-mode file. 1:47:35 obr: fork of Rust port of Beads to use Org Mode for issue lists
 John: obr is the task management tool that uses Org-mode as the storage format. We talked about org-devonthink.
John: obr is the task management tool that uses Org-mode as the storage format. We talked about org-devonthink. 1:47:45 org-context saves metadata when refiling to allow restoring the task to its original location afterwards
John: Oh yes, I use org-context a lot as well. I never mentioned that one. This is another way that I use metadata. If I'm on a task, I can be on the stars of that task and type a short key. So w will refile a task somewhere else into another Org-mode file. When you refile a task in my system, it will supply it with a rich set of metadata identifying where the task came from. That's what org-context does. It doesn't do that for items that you refile out of the drafts inbox, because I assume that everybody came from the drafts inbox. But if it goes from the inbox to another file and then to another file, it'll know it came from that previous file. This can happen, for example, if a work task becomes an open-source task. Using org-context, this process is reversible. You can go to a task and say, "You know what? Unrefile yourself back to where you were." It uses that metadata to put itself back. Karthik: Does this also work when you archive entries? John: org-context advises on top of the archive mechanism to do the same thing for archiving that it does for refiling, by thinking of archiving as a form of refiling. So it allows you to unarchive a task back to where you archived it from. Karthik: Yeah, because that's... 1:49:13 org-context use case: moving packing lists to the phone and back
John: The main reason I wrote it and that I use this system is that I use the iPhone app Plain Org for maintaining a list of items that I want to have access to as Org entries on my phone. So I have a special file called mobile.org that has its own little tiny hierarchy of just the items I want to see on my phone. But an Org entry can't live in two places, and it doesn't make sense for the phone version to be a link to the computer version because it doesn't have access to the computer. So what I do is, for the duration of time that I want it on the phone— and usually this is packing lists, actually, because I want to do the packing list on my phone— I will refile it into mobile.org. Then when I mark it done, I will unrefile it back to where it came from, which is typically a trip. One of the capture templates I have is for trips, where it will include "get a hotel," "get a flight," "do this," "do that"— it just is like a stock body of ten tasks that are associated with every trip that I ever take. Every time I do a trip, one of those tasks is a packing list task with a huge checklist underneath it. I will file that into mobile.org and unrefile it back. Karthik: I see what you meant by "don't ever have only one system, only ever use Org, put everything in Org." You can't have a packing list somewhere else that's full of things to do. John: I wouldn't have two. It has to live in this. Karthik: Yeah, yeah, I know. I mean, that's one of the—I mean, that is a tooling problem. So there's a psychological problem, I think, with me trying to do things with Org, where present-me and future-me don't agree on what needs to be done and when, right? Org can't help with that. Then there's a tooling problem, which is just how do I see the things I need to see on my phone when I need to see them? At least as far as the tooling problem is concerned, you've got it all sorted. John: I'm getting there! Little bit by little bit. 1:51:22 org-agenda-overlay
 John: Then lastly, org-agenda-overlay. This is what causes the background colors to differ among my org-agenda items. org-agenda-overlay allows you—as a property, or as a file property, or as a defined Org-mode variable— to associate categories. I don't... maybe I even can associate tags. It might be arbitrary items, but you can associate it with a face property. Then you can specify in the face property any modifications to the Emacs face that you want to make. I have it set so that—I think I do this by... yeah, I do it by... Are you seeing my Emacs at the moment? Karthik: Not yet. John: Let me show you the Emacs. So I do it with org-todo-keyword-faces. Then I also do it with—oh, I think that's the only one I do it for. But you can see here—no, that's the colors of the keywords. Sorry, let me go here. It's under, of course, my org-agenda-overlay use-package declaration.
John: Then lastly, org-agenda-overlay. This is what causes the background colors to differ among my org-agenda items. org-agenda-overlay allows you—as a property, or as a file property, or as a defined Org-mode variable— to associate categories. I don't... maybe I even can associate tags. It might be arbitrary items, but you can associate it with a face property. Then you can specify in the face property any modifications to the Emacs face that you want to make. I have it set so that—I think I do this by... yeah, I do it by... Are you seeing my Emacs at the moment? Karthik: Not yet. John: Let me show you the Emacs. So I do it with org-todo-keyword-faces. Then I also do it with—oh, I think that's the only one I do it for. But you can see here—no, that's the colors of the keywords. Sorry, let me go here. It's under, of course, my org-agenda-overlay use-package declaration. 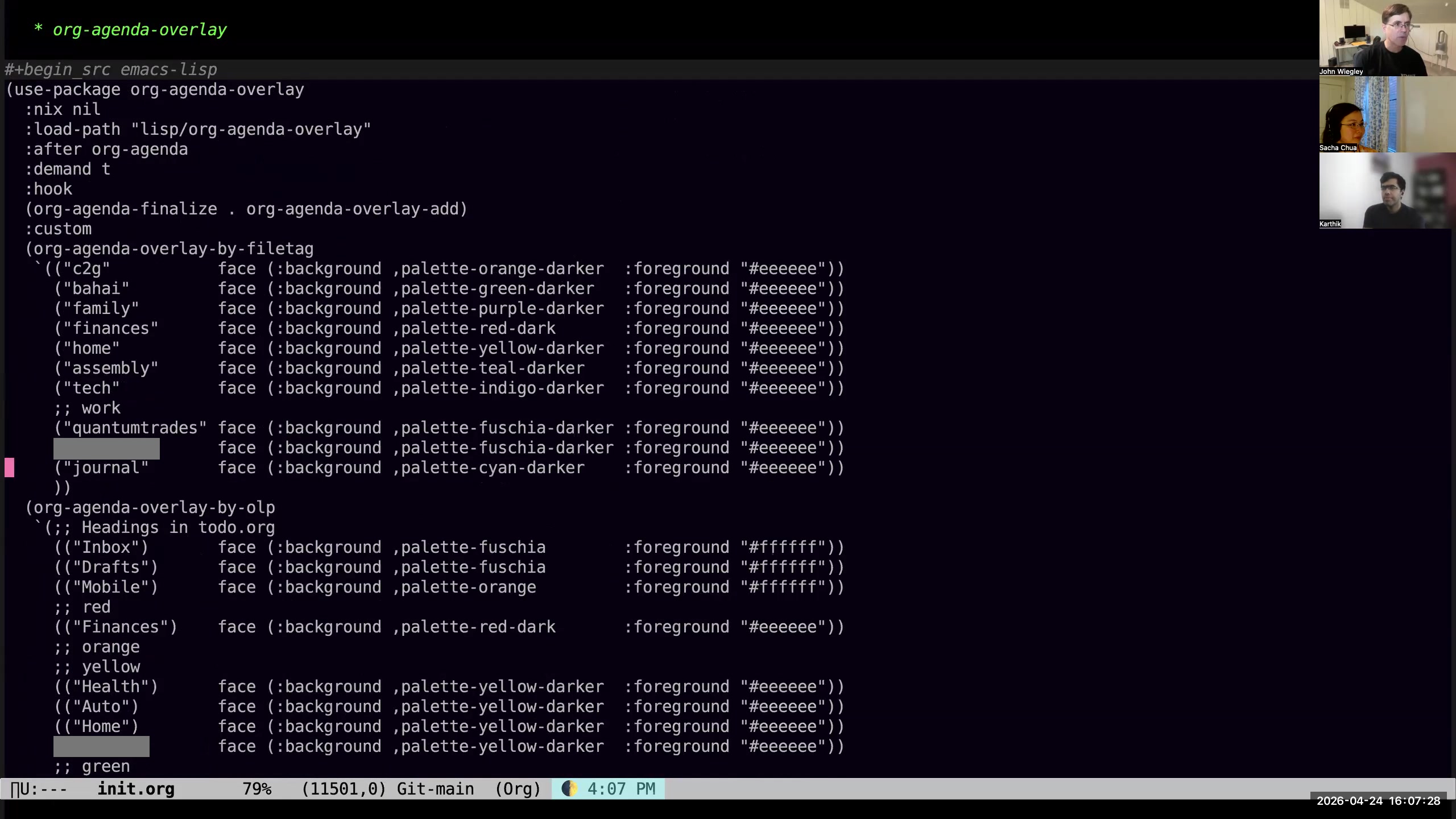 John: So I have org-agenda-overlay-by-file-tag. If the file has this file tag, then it will apply this background and foreground to any task from that file.
John: So I have org-agenda-overlay-by-file-tag. If the file has this file tag, then it will apply this background and foreground to any task from that file. 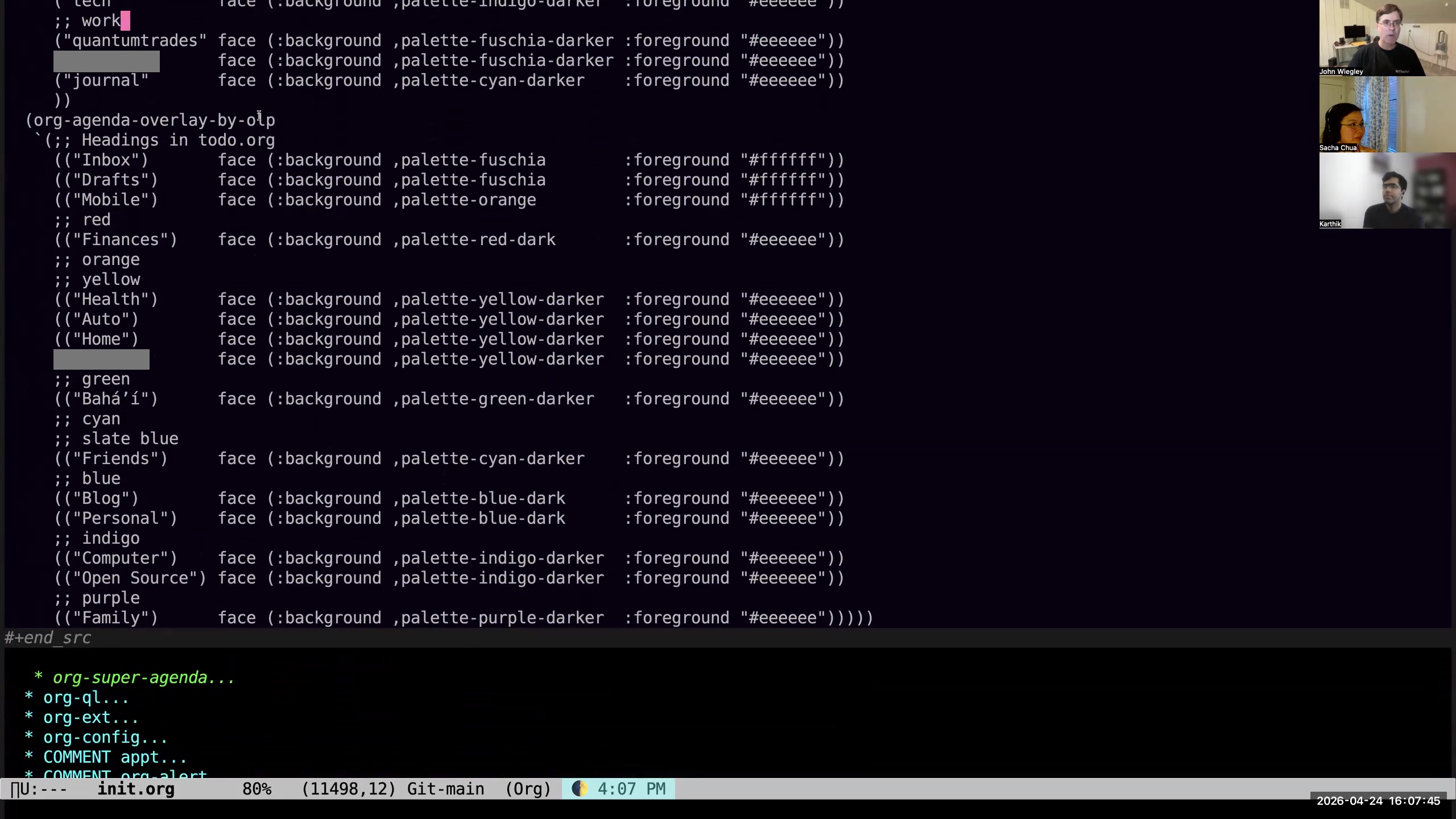 John: Then this is overlay-by-olp, which is the outline-level path. If it's in a heading called "inbox" (and of course this supports slashes so that you can be more specific), then alter the face. But you could do this with properties on the individual entries as well, if you wanted to.
John: Then this is overlay-by-olp, which is the outline-level path. If it's in a heading called "inbox" (and of course this supports slashes so that you can be more specific), then alter the face. But you could do this with properties on the individual entries as well, if you wanted to. 1:53:05 john-wiegley-theme defines a palette
 John: I created—let me see, what did I call it?—oh, john-wiegley-theme. I love to use rainbow-mode to help me edit this file. I wanted to create a consistent color vocabulary for everything that is in Org-mode. So all Org-mode tags, keywords, background colors, everything is harmonized to use these sets of colors. I have dark, darker, and darkest variants because of my black background. Sacha: Interesting. John: Yeah, I used a Mac app called Paletton to help me create the harmonious color wheel that these are chosen from. Sacha: Okay, just a quick check. In terms of getting stuff out of this conversation in two forms that other people can learn from— if we're thinking of the audio recording and the transcript—we didn't talk about anything really weird. So is that reasonably good to go, or do you want to review it first? John: No, I would ask the AI to let me know whether there was anything in the transcript that I wouldn't want to become public. Sacha: All right. So basically, we do the transcript, we break it up into chapters so that there are timestamps, you have your AI say whether we should need to take stuff out. I was thinking maybe we do the transcript, possibly the audio recording, because it's fun to hear people be excited about stuff—and then you can imagine your cadence as you're talking about things. Then we can progressively enhance it with screenshots or clips or whatever Karthik has patience for. I don't know if we're going to do the full whole length video, but definitely bits of it. Karthik: I'm going to start, and then I'm going to see how it's going. If it looks like I just have to draw rectangles over things—let me do like ten minutes of the video by hand and see if it took a reasonable amount of time. If it did, then I can extend that to the whole video. Otherwise, we will probably have to downgrade to screenshots or something where it's safe and easy to redact stuff. Sacha: And then we can send— Karthik will coordinate with John about whatever else needs to be removed. Karthik: Yeah. So John, I'm going to ping you and ask you, "Is this okay to include? Is this okay to include?" I'll try to batch these queries so you can give me—I'll try to be conservative, but yeah, let's see. In any case, I will share the video with you. No one is publishing anything until you give me the okay. So I think the transcript and audio stuff, Sacha, that's on you. Sacha: And the text. Yes. Karthik: And the video thing—drawing rectangles and adding blur filters— I will get started on that.
John: I created—let me see, what did I call it?—oh, john-wiegley-theme. I love to use rainbow-mode to help me edit this file. I wanted to create a consistent color vocabulary for everything that is in Org-mode. So all Org-mode tags, keywords, background colors, everything is harmonized to use these sets of colors. I have dark, darker, and darkest variants because of my black background. Sacha: Interesting. John: Yeah, I used a Mac app called Paletton to help me create the harmonious color wheel that these are chosen from. Sacha: Okay, just a quick check. In terms of getting stuff out of this conversation in two forms that other people can learn from— if we're thinking of the audio recording and the transcript—we didn't talk about anything really weird. So is that reasonably good to go, or do you want to review it first? John: No, I would ask the AI to let me know whether there was anything in the transcript that I wouldn't want to become public. Sacha: All right. So basically, we do the transcript, we break it up into chapters so that there are timestamps, you have your AI say whether we should need to take stuff out. I was thinking maybe we do the transcript, possibly the audio recording, because it's fun to hear people be excited about stuff—and then you can imagine your cadence as you're talking about things. Then we can progressively enhance it with screenshots or clips or whatever Karthik has patience for. I don't know if we're going to do the full whole length video, but definitely bits of it. Karthik: I'm going to start, and then I'm going to see how it's going. If it looks like I just have to draw rectangles over things—let me do like ten minutes of the video by hand and see if it took a reasonable amount of time. If it did, then I can extend that to the whole video. Otherwise, we will probably have to downgrade to screenshots or something where it's safe and easy to redact stuff. Sacha: And then we can send— Karthik will coordinate with John about whatever else needs to be removed. Karthik: Yeah. So John, I'm going to ping you and ask you, "Is this okay to include? Is this okay to include?" I'll try to batch these queries so you can give me—I'll try to be conservative, but yeah, let's see. In any case, I will share the video with you. No one is publishing anything until you give me the okay. So I think the transcript and audio stuff, Sacha, that's on you. Sacha: And the text. Yes. Karthik: And the video thing—drawing rectangles and adding blur filters— I will get started on that. 1:56:16 Some numbers: 83 packages just related to Org Mode
John: I just looked at my Emacs init file, and I realized that I have 83 different packages being configured that are related just to Org-mode. There's a lot being layered on to Org-mode. I didn't talk about org-contacts, I didn't talk about org-edna, I didn't talk about vcard or inline-task—all of these are things that I use very heavily. Like org-noter—org-noter is my primary way of taking notes on PDF files. Sacha: You know, if we spend like five minutes where you just rattle off this list of modules you have, with like a one-line description—beyond the package description— of how it fits into your workflow... John: I don't even remember what they all do. Sacha: That's true. Yeah. John: org-transcription I use, like, oh my gosh. Sacha: A topic for another conversation. John: Yeah, I think it's another— Sacha: I think that's one of the fun things that we had back when we did the first Emacs Chat: just going through the configuration. Because when you're looking at it, you're like, "Oh yeah, that package, this is how I use it," or, "Oh yeah, I totally forgot about that one." So at some point we can do a walkthrough that's got config so you can say, "Oh yeah, this is what I use for this." Karthik: Just use-package block after use-package block. John: Yes, that's right. One after the other. Sacha: But it doesn't have to be today. Karthik: Yeah, definitely not. Yeah. I think Sacha and I have our hands full trying to get this video ready to be published. John: Yeah. Well, at least I think we scratched the surface. I think we covered some of the big, broad strokes. Sacha: Yeah. Karthik: Yeah, I would say so. Sacha: So this was a great idea. And thank you for taking the time to do it. 1:58:05 Org Mode inspiration
Karthik: I hope people get an idea of what's possible with Org-mode, because the common problem is that people say, "You can do everything, you can manage your life in Org-mode," and then when someone asks you to show how, you see some very anodyne, pedestrian things like to-do lists, and that's not what we're talking about. That's not the scale of things. Yeah, yeah, yeah. "And don't forget the milk," and this and that. No, that's not... Sacha: Yeah, no, that's why we should talk about... 40,000 entries—what were you saying... 9,700 tasks and 1,200 of them are open. Yeah, that's the kind of scale we're looking at. Karthik: And it's been maintained for 20 years at least. 1:58:51 Statistics
John: Actually, let's see, talking about— Let me share my terminal because I haven't looked at this in a little bit. John: So if we go into my Org and I type make stats. 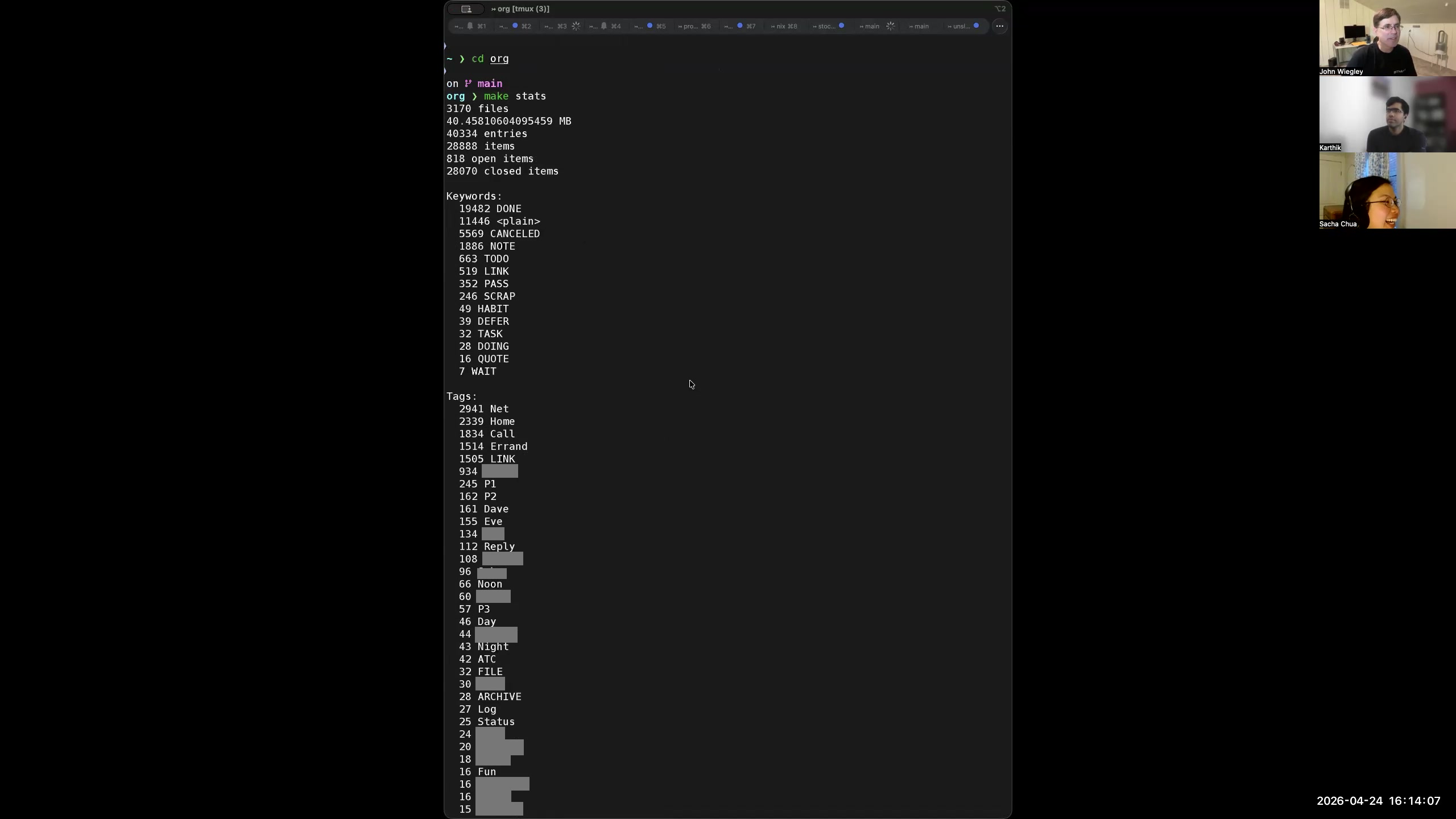 John: So this is 3,170 files, 40 megabytes of data. Oh, it is over 40,000 entries now. Sacha: Yeah, yeah, yeah. John: 28,000 are TODO items. Sacha: Okay, okay. Well, let's update that. John: 818 are open. So more than half of my Org-mode entries are TODO items. Sacha: Very cool. And somehow the combination of org-ql and the Postgres database makes it easy to just fly through all of those files looking for the ones that you need. John: I mean, "easy" is a very charitable word.
John: So this is 3,170 files, 40 megabytes of data. Oh, it is over 40,000 entries now. Sacha: Yeah, yeah, yeah. John: 28,000 are TODO items. Sacha: Okay, okay. Well, let's update that. John: 818 are open. So more than half of my Org-mode entries are TODO items. Sacha: Very cool. And somehow the combination of org-ql and the Postgres database makes it easy to just fly through all of those files looking for the ones that you need. John: I mean, "easy" is a very charitable word. 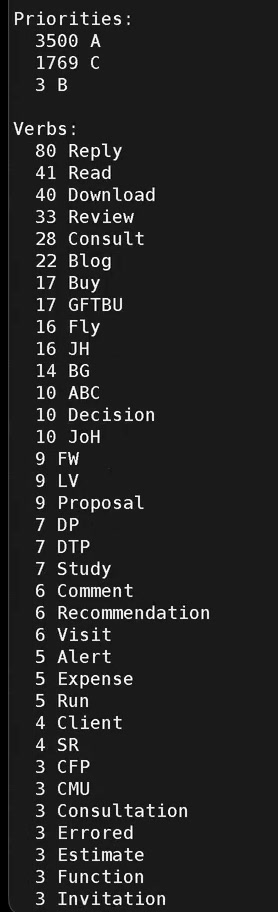 Sacha: "Fast," at least. John: Oh wow, I have three items that actually have B priorities. I wonder what those mean. Sacha: I'm surprised that your validation and normalization functions let those slip past you. John: I don't think I disallow B. I think I had B have a specific meaning at one point, because B stands out so much. I had ascribed it to some special meaning. Sacha: I like your stats. They're fun.
Sacha: "Fast," at least. John: Oh wow, I have three items that actually have B priorities. I wonder what those mean. Sacha: I'm surprised that your validation and normalization functions let those slip past you. John: I don't think I disallow B. I think I had B have a specific meaning at one point, because B stands out so much. I had ascribed it to some special meaning. Sacha: I like your stats. They're fun. 2:00:18 Most-common properties: ID, CREATED
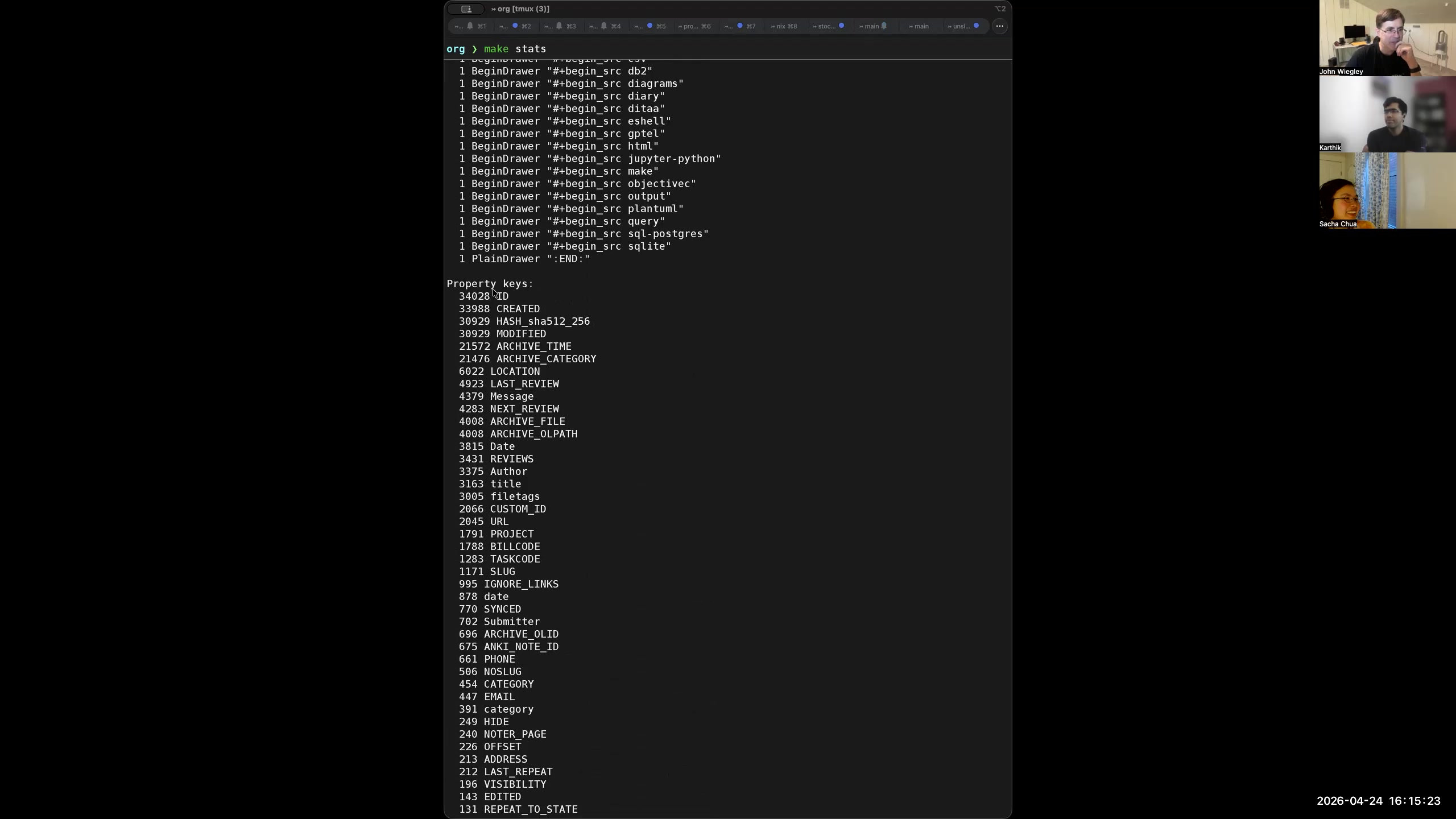 John: Yeah. Look at that. My most commonly occurring properties are ID and CREATED. That's right, that's what it should be. Oh, but not every entry has a hash, clearly. I wonder how that happened.
John: Yeah. Look at that. My most commonly occurring properties are ID and CREATED. That's right, that's what it should be. Oh, but not every entry has a hash, clearly. I wonder how that happened. 2:00:33 Log entries are useful for notes by date
John: And we didn't talk about how useful log entries are. That's actually— I did try to veer away from Org-mode in like 2010, and the reason I couldn't was because log entries are too useful. Sacha: Oh, now I'm really curious. John: Yeah. Just the ability—while you're working on it— you know, some tasks live a long time. There was a time when Aetna wouldn't honor one of my insurance claims and it took me nine months to resolve it with them. But every single time I talked to them on the phone or by email, I would log an Org-mode note of what we talked about and who I talked to. So as time went on and I would get on the phone with a new person, I would be like, "Well, on this date I talked to this person and they said this. Then on this date, this person said this." I would overwhelm them with so much concrete information about how much I had done to resolve this, that they would be like, "Okay, okay, I get it." Sacha: This person keeps receipts. Karthik: How did you get that log into Org-mode? Were you on your computer while you were on the phone with them? John: Yes, I was on the computer while I was on the phone. Karthik: Okay. I'm just wondering, that's the kind of thing I could never manage, because I don't know where I'll be on the phone. I won't be near Org-mode. 2:01:48 Transcripts are great too
John: Well, nowadays the iPhone lets you record your phone conversations. So you can ask them if it's okay to record, and then—hey, AI is your friend. Karthik: Okay. John: I love transcripts now. I use them for all kinds of things. Sacha: I agree. Transcripts are wonderful. John: Yeah. And I record them all. Every meeting file, if I can, I just put the whole transcript in the file, because it helps with searching in the future. Sacha: Yeah. All right. And on that note, we are going to turn this into a transcript and possibly [video].{kind=link}