La semaine du 15 juin au 21 juin
| frenchlundi 15
Ma fille avait fait une sieste hier soir, donc elle s'était couchée très tard. Eh ben, on va voir. Elle a un examen ce matin.
Ma fille était fière d'obtenir la note maximale à son quiz sur la conjugaison du verbe aller. Nous l'avons révisée au fil de la conversation avant son quiz.
J'ai corrigé et segmenté le sous-titrage de ma conversation avec Prot la semaine précédente. J'ai fait une diffusion en direct pendant que je le faisais.
Après l'école, j'ai emmené ma fille au cours de gymnastique. Nous étions un peu en retard, mais elle s'est amusée. Elle s'est exercée au deuxième étage au lieu d'utiliser le trampoline au rez-de-chaussée.
Ma mère a du mal à signer de la paperasse à cause de la maladie de Parkinson, donc c'est une bonne idée de préparer une procuration durable pour me permettre de signer en son nom. J'ai lu la paperasse que j'avais demandée aux avocats de préparer pour ma mère et j'ai demandé à la responsable de l'imprimer avant ma conversation avec ma mère pour lui expliquer.
Ma mère s'est inquiétée pour les revenus d'entreprise et elle a voulu agrandir l'entreprise malgré ses difficultés physiques et cognitives. À mon avis, c'est une mauvaise idée parce qu'elle ne peut pas encore gérer des décisions compliquées à cause de son manque d'énergie et du Parkinson qui rend beaucoup de choses difficiles.
mardi 16
Ma fille s'est réveillée trop tard et elle a séché les cours. Elle est allée en cours l'après-midi.
J'ai analysé les statistiques sur la remise des devoirs de ma fille. Cette année scolaire (la quatrième année), elle en avait rendu 43 pour cent à temps et 32 pour cent en retard, et elle n'a pas rendu 25 pour cent des devoirs. Ses enseignants ne semblaient pas trop inquiets.
J'ai rendez-vous avec mon tuteur Raphaël. Nous avons parlé des animaux de compagnie, des voyages, de nos familles et de ses études. Je m'habitue à converser petit à petit.
J'ai relu les procurations durables pour ma sœur et ma mère. J'ai encore envoyé des questions à l'avocat.
Après avoir joué à Donjons et Dragons chez nous, ma fille et moi sommes allées au parc pour jouer ensemble. Nous avons joué encore à Donjons et Dragons dans la vraie vie.
Ma fille a fait un cauchemar sur une mouffette la nuit dernière. Elle a dit qu'elle ne voulait pas dormir. Elle a eu peur d'en faire encore un.
mercredi 17
Il y avait encore un remplaçant à l'école. Ma fille n'a pas voulu travailler sur ses devoirs qui sont à rendre demain. Je n'avais pas l'énergie pour la convaincre de les faire. Elle avait passé une mauvaise nuit l'autre jour, donc elle n'avait pas voulu aller se coucher jusqu'à ce qu'il soit très tard. J'étais encore fatiguée.
Ma fille et moi sommes allées au parc pour jouer à Donjons et Dragons grandeur nature.
J'ai fait les courses et je suis allée à la bibliothèque pour emprunter des livres.
jeudi 18
Ma fille a fait deux présentations (une sur la musique et une sur la science). Elle a dit qu'elle avait réussi les deux.
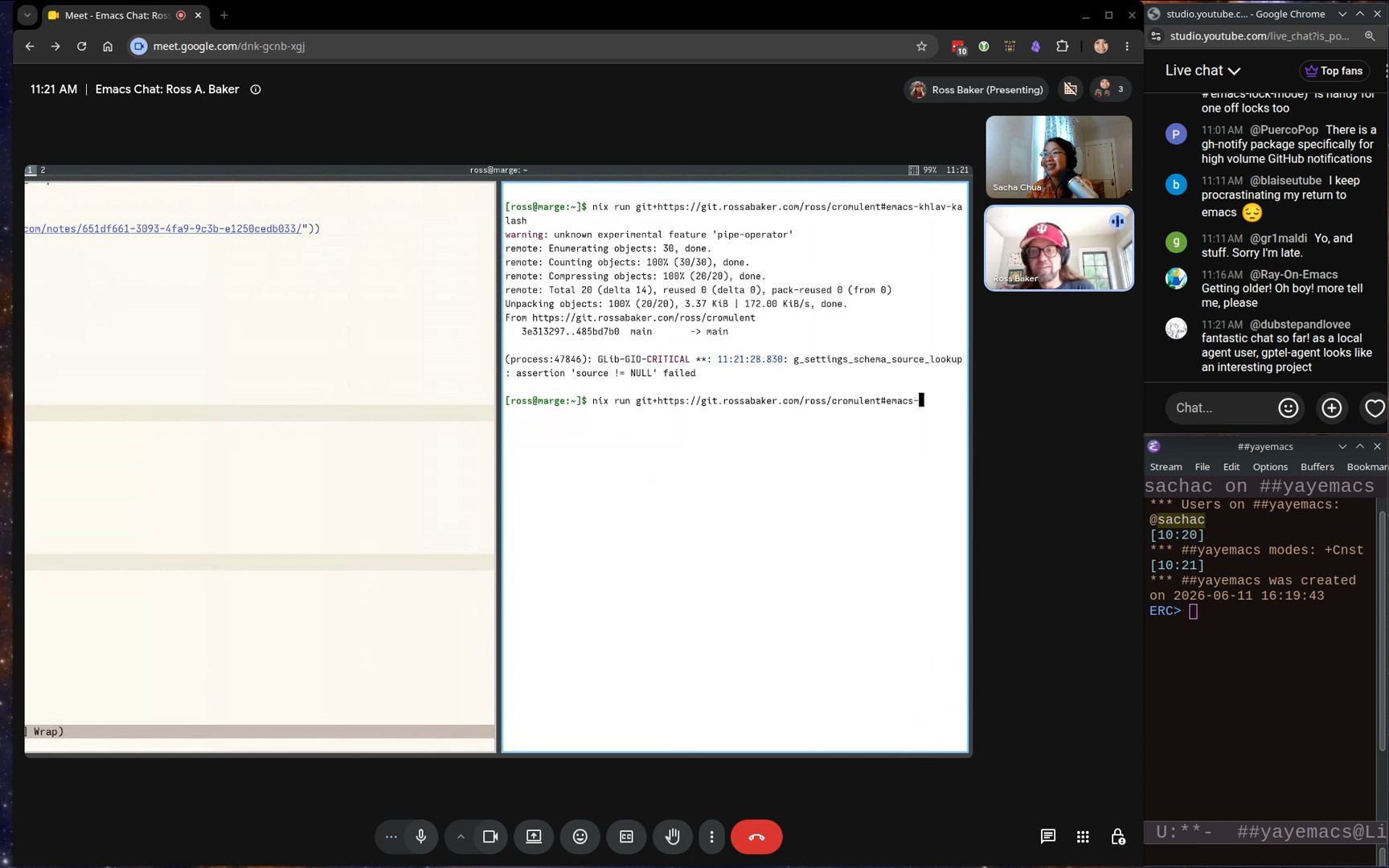
J'ai interviewé Ross A. Baker sur ses expériences et ses flux de travail d'Emacs.
Ma fille et moi avons peint à l'aquarelle. J'ai peint les mots à partir de sa feuille de vocabulaire à l'école. Elle portait sur les vêtements.
Ma fille a dit qu'elle ne mange parfois pas le dîner parce qu'elle ne peut pas choisir. Je dois offrir moins de choix.
vendredi 19
J'ai corrigé la transcription de ma conversation avec Ross A. Baker sur Emacs.
J'ai rendez-vous avec un nouveau tuteur français qui habite au Cameroun. Il m'a donné des épreuves du DELF A2. J'ai lu à voix haute et j'ai répondu à presque tout à l'exception d'un peu de confusion sur le faire-part de mariage, parce que c'est habituel ici d'envoyer un message pour réserver la date avant l'invitation réelle. La prochaine fois, nous allons faire l'épreuve de compréhension. Je pense qu'il s'exprime un peu plus clairement que mon tuteur habituel. À mon avis, cela vaudrait la peine de continuer avec les deux tuteurs pour m'habituer aux différents interlocuteurs. Mon tuteur initial semblait plus aimable et nous partageons un intérêt pour la technologie, et cet autre tuteur semblait plus sérieux et plus structuré. Les vacances d'été arriveront bientôt. Je ne sais pas quel type de programme j'aurai parce que ma fille veut jouer avec moi. Je veux continuer mon apprentissage du français.
Je suis passée à l'écriture de mon journal principal en français. J'ai aussi essayé de dicter mon journal. La reconnaissance vocale ne peut pas saisir tous mes mots, donc je pense que c'est mieux que je tape mes mots tout en les disant pour m'habituer.
J'ai appris qu'il faut que le témoin pour la paperasse de l'assurance-vie soumette une copie de son passeport. Oh, dommage. Je ne sais pas à quel point je connais bien mon témoin initial, qui est un voisin, pour oser lui demander une copie de son passeport.
J'ai emmené ma fille au cours collectif de gymnastique aérienne. Elle a participé au spectacle. Elle était très fière.
Après le cours, nous sommes allées au parc des asperges (c'est notre diminutif pour ce parc) pour jouer là-bas. Elle a descendu le toboggan de nombreuses fois. J'étais un peu stressée parce que d'autres enfants ont essayé d'escalader le toboggan même si quelqu'un allait descendre.
Ma fille s'est blottie contre moi toute la nuit.
samedi 20
Il faisait chaud. Nous sommes allées à la piscine pour la première fois cette saison. C'était rafraîchissant. L'eau n'était pas trop froide parce que la piscine est chauffée.
dimanche 21
Mon mari a préparé des grillades coréennes pour le dîner.
Ma fille et moi sommes allées à pied jusqu'à la piscine près de chez nous, mais l'eau était froide parce que la piscine n'a pas de système de chauffage. Une fois rentrées, je l'ai emmenée à vélo à l'autre piscine qui a un système de chauffage et un toboggan. Nous sommes arrivées là 10 minutes avant la pause, donc nous nous sommes baignées brièvement. Nous avons joué à l'aire de jeu jusqu'à la réouverture de la piscine. Puis, nous avons nagé pendant une heure. Ma fille se fatigue trop vite pour réussir un test de natation. Si elle s'entraîne, elle s'améliore.
J'ai transféré de l'argent du compte de ma mère à mon compte pour me permettre de gérer la situation au cas où quelque chose surviendrait.
Ma fille m'a apporté tous les livres philippins à lire.
À l'heure du coucher, nous avons eu une longue conversation sur la neurodivergence.





{kind=link}